pyVideoTrans 技术架构与实现原理
pyvideotrans 是一款功能强大的视频翻译工具,其核心设计思想是采用模块化、多线程流水线的架构,以实现高效、稳定且可扩展的视频处理流程。
一、 核心处理流程
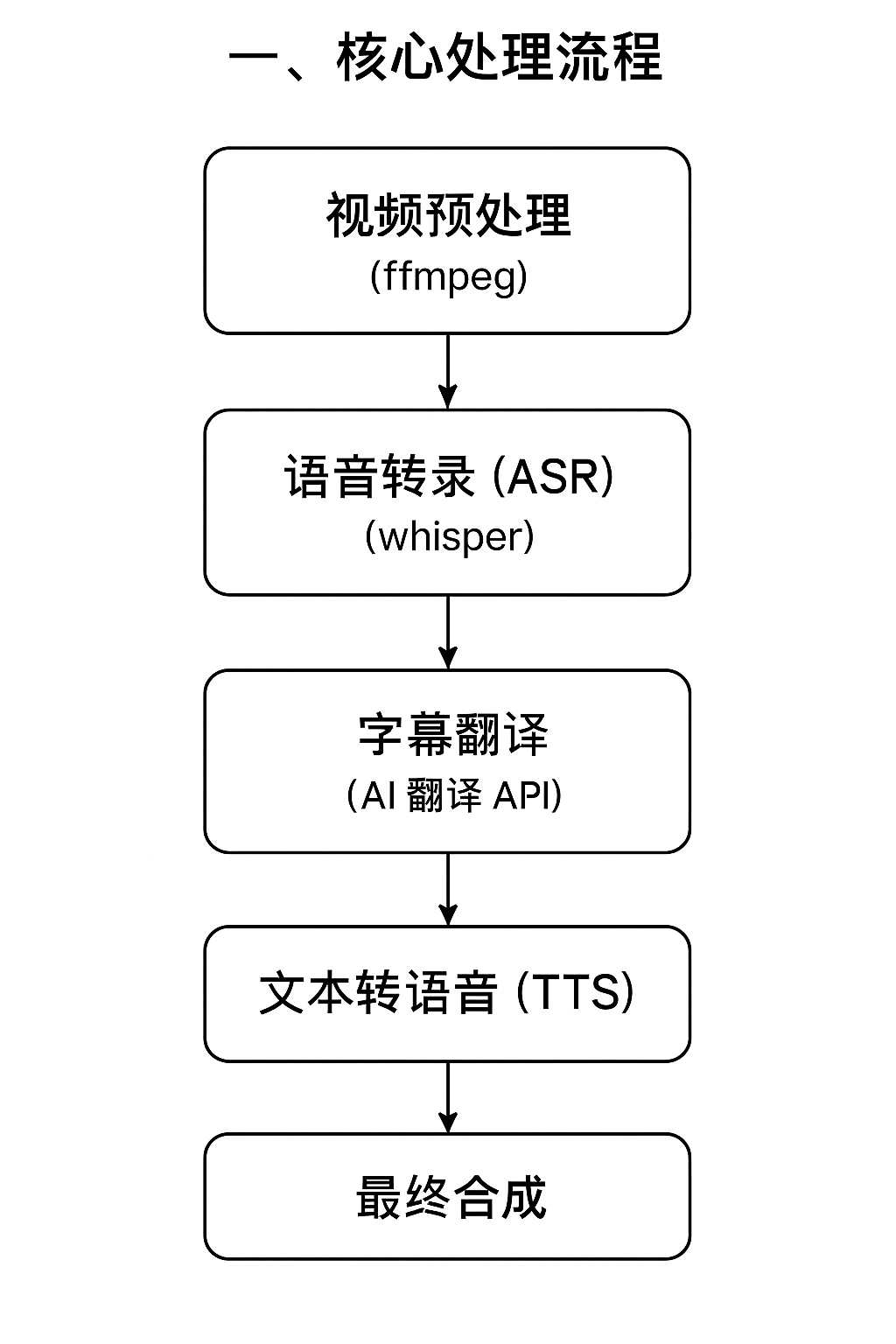
软件的核心功能是将一个视频自动翻译并配上目标语言的语音。整个过程被分解为一系列独立的步骤,形成一条自动化的处理流水线:
- 视频预处理: 首先,使用
ffmpeg工具将原始视频文件分离成两个独立部分:一个无声的视频流和一个原始的音频流。 - 语音转录 (ASR): 接着,调用语音识别引擎(如
whisper模型)将分离出的原始音频转录为带时间戳的字幕文件(SRT 格式)。 - 字幕翻译: 将原始语言的 SRT 字幕文件通过翻译服务(如 AI 翻译 API)翻译成目标语言的 SRT 字幕。
- 文本转语音 (TTS): 使用 TTS 引擎,根据目标语言的 SRT 字幕内容和时间戳,生成对应的配音音频文件。
- 最终合成: 最后,将无声视频流、目标语言字幕文件和新生成的配音音频文件三者合并。通过精确的时间码对齐,最终生成一个翻译完成并配好音的视频文件。
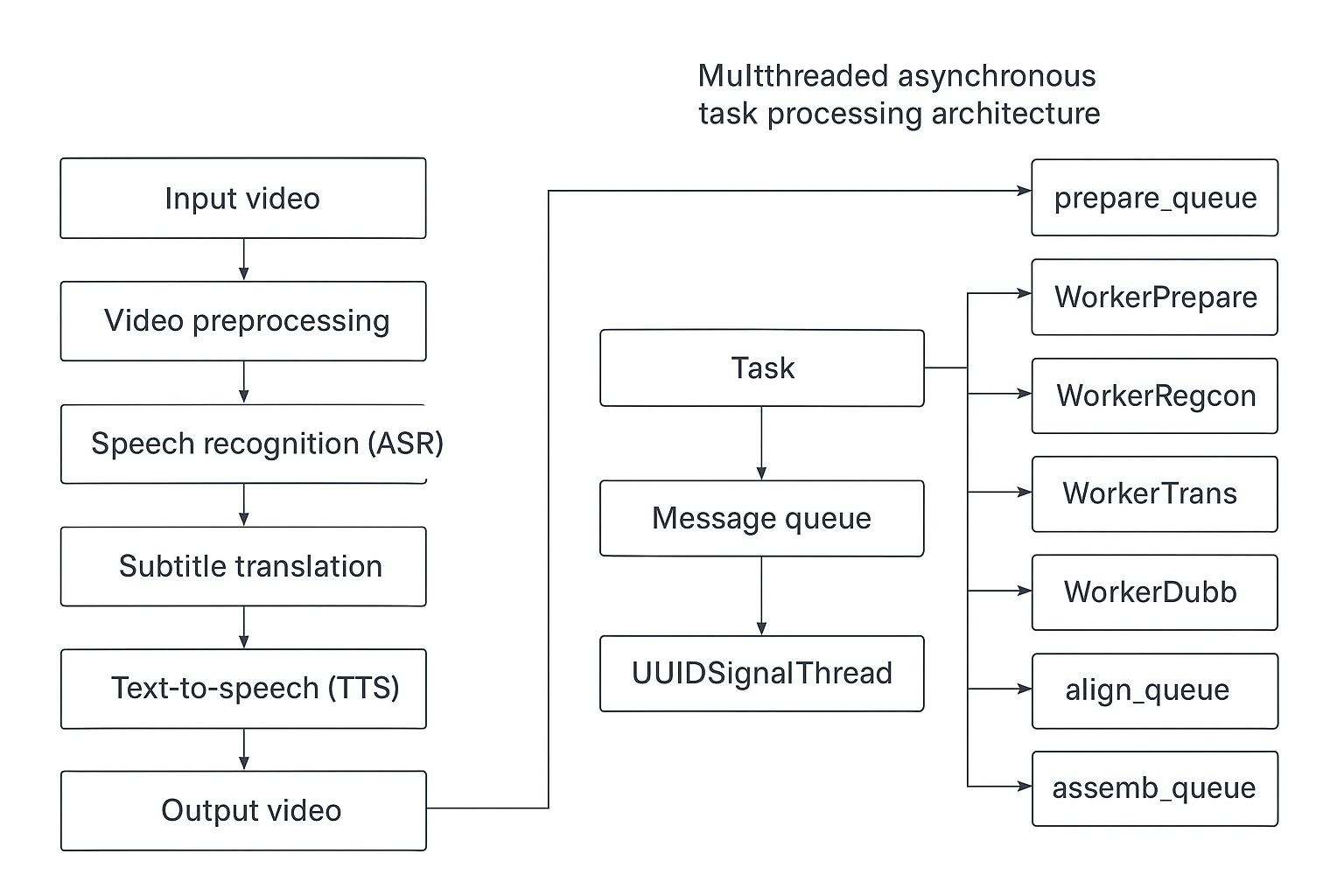
二、 多线程异步任务处理架构
为了在执行长时间的视频处理任务时保持用户界面(UI)的流畅响应,pyvideotrans 采用了基于“生产者-消费者”模式的多线程和多队列架构。
当用户发起一个任务(例如翻译一个视频)时,该任务会依次流经一个由 7 个专用工作线程组成的流水线。每个线程负责处理流程中的一个特定阶段,并通过队列(Queue)与下一个线程进行数据交接。
任务(Task)
每个待处理的音视频文件都被封装成一个 BaseTask 对象。该对象拥有一个唯一的 UUID 标识符,并贯穿整个处理流程。任务对象中包含了处理所需的所有数据和状态信息。
工作线程与数据队列
每个工作线程都持续监控一个专属的输入队列。一旦队列中有任务数据,线程便会取出并执行其特定工作,完成后将结果放入下一个线程的输入队列。
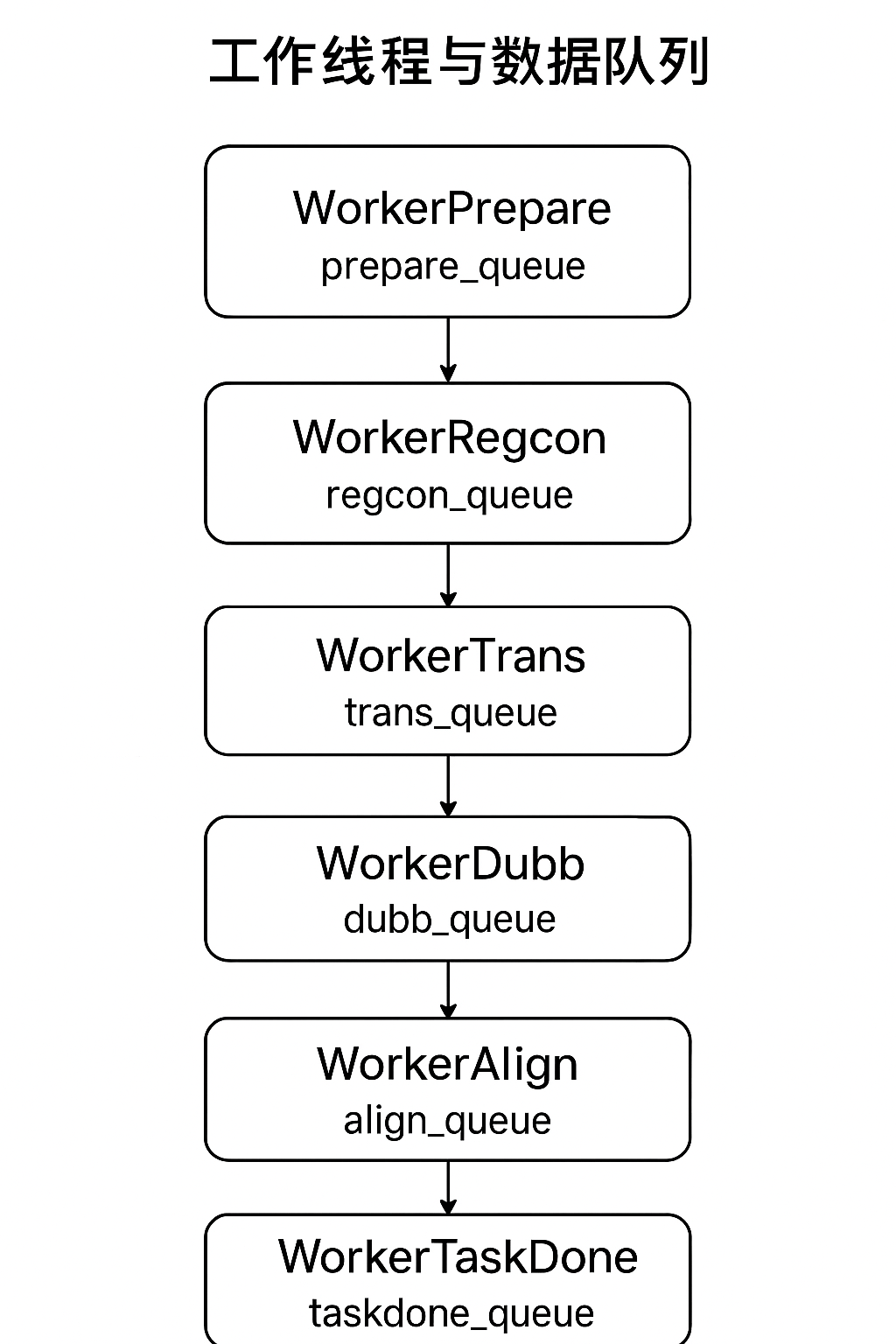
预处理线程 (
WorkerPrepare):- 队列:
prepare_queue - 职责: 接收原始文件路径,执行音视频分离,创建处理所需的临时目录和标准化数据结构。处理完毕后,将任务交由
recogn_queue。
- 队列:
语音识别线程 (
WorkerRegcon):- 队列:
regcon_queue - 职责: 调用指定的语音识别模块,将音频文件转录为原始语言的 SRT 字幕。处理完毕后,将任务交由
trans_queue。
- 队列:
字幕翻译线程 (
WorkerTrans):- 队列:
trans_queue - 职责: 将原始 SRT 字幕翻译成目标语言。处理完毕后,将任务交由
dubb_queue。
- 队列:
配音线程 (
WorkerDubb):- 队列:
dubb_queue - 职责: 根据翻译好的字幕,调用 TTS 模块合成配音。处理完毕后,将任务交由
align_queue。
- 队列:
音画对齐线程 (
WorkerAlign):- 队列:
align_queue - 职责: 处理音频变速、视频慢放等复杂场景,确保最终视频的音画同步与字幕精确对齐。处理完毕后,将任务交由
assemb_queue。
- 队列:
嵌入合并线程 (
WorkerAssemb):- 队列:
assemb_queue - 职责: 将无声视频、配音音频和目标语言字幕最终合并成一个完整的视频文件。处理完毕后,将任务交由
taskdone_queue。
- 队列:
收尾处理线程 (
WorkerTaskDone):- 队列:
taskdone_queue - 职责: 将最终生成的视频文件从临时目录移动到用户指定的输出目录,清理临时文件,并向 UI 发送任务完成通知。
- 队列:
消息与 UI 更新线程 (UUIDSignalThread)
除了 7 个工作线程,还有一个独立的消息线程。每个任务都拥有自己的消息队列,工作线程在执行过程中会将进度、日志、状态等信息推送到该队列。消息线程则负责从当前活动任务的消息队列中拉取信息,并实时更新到主界面上,让用户随时了解任务状态。
功能定制与流程跳过
这种流水线架构具有极高的灵活性。软件的不同功能可以通过“跳过”流水线中的某些环节来实现。每个任务(BaseTask)内部都有标志位来控制是否执行某个阶段。
- 示例1:视频转字幕功能 此功能仅需识别字幕,因此会跳过字幕翻译、配音、音画对齐、嵌入合并这 4 个线程。
- 示例2:批量为字幕配音功能 此功能从已有的字幕文件开始,因此会跳过语音识别、字幕翻译这两个线程。
三、 核心类的设计与继承关系
软件的扩展性得益于其面向对象的继承体系设计,通过基类定义接口,子类实现具体功能。
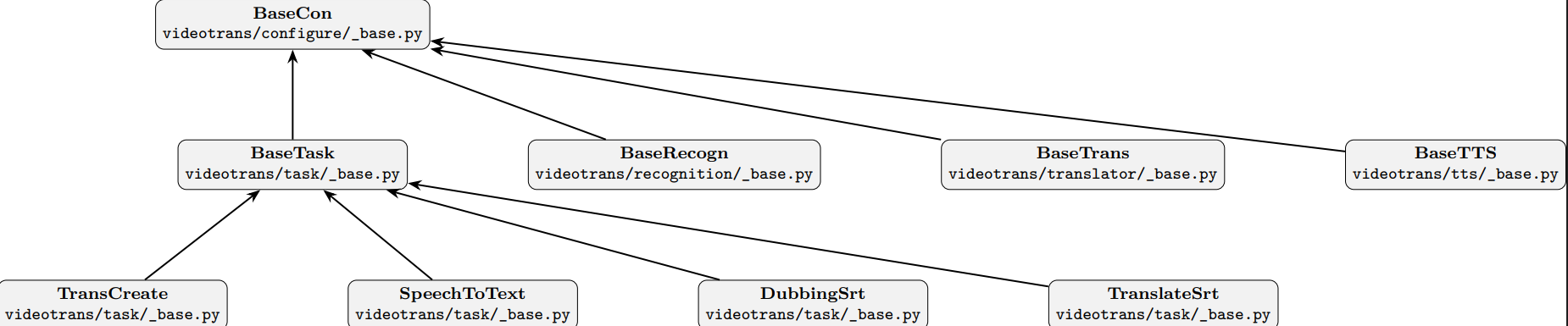
顶层基类 (BaseCon)
位于 videotrans/configure/_base.py,定义了所有类共用的基础属性和方法,如任务 UUID、消息发送机制、代理配置等。
基础任务类 (BaseTask)
位于 videotrans/task/_base.py,继承自 BaseCon。它定义了任务在 7 个工作线程中对应执行的 7 个核心方法,以及控制流程跳过的标志位。它还规定了任务需要使用的识别、翻译和配音渠道。
- 视频翻译任务 (
TransCreate):BaseTask的子类,完整实现了全部 7 个阶段的处理逻辑。 - 音频视频转字幕任务 (
SpeechToText):BaseTask的子类,仅执行预处理、语音识别和收尾 3 个阶段。 - 批量为字幕配音任务 (
DubbingSrt):BaseTask的子类,仅执行预处理、配音、音画对齐和收尾 4 个阶段。 - 批量翻译 srt 任务 (
TranslateSrt):BaseTask的子类,仅执行预处理、字幕翻译和收尾 3 个阶段。
语音识别类 (BaseRecogn)
位于 videotrans/recognition/_base.py,是所有语音识别渠道的父类。BaseTask 在执行语音识别阶段时,会调用其某个子类的实例来完成工作。
- 特别说明: 为防止
faster-whisper可能出现的崩溃导致整个软件退出,FasterAll和FasterAvg这两个子类被设计为在独立的子进程中运行,增强了主程序的稳定性。
字幕翻译类 (BaseTrans)
位于 videotrans/translator/_base.py,是所有字幕翻译渠道的父类,提供了统一的翻译接口。
配音类 (BaseTTS)
位于 videotrans/tts/_base.py,是所有 TTS 配音渠道的父类。
- 其子类根据不同 TTS 接口的特性采用不同的并发策略。例如,
EdgeTTS在当前线程内使用异步(asyncio)并发,而其他子类则通过创建多个子线程来并行处理配音任务。
当然,这段新增内容非常重要,它解释了软件在不同使用场景下的设计考量。以下是为您优化的版本,使其逻辑更清晰,并与前文风格保持一致。
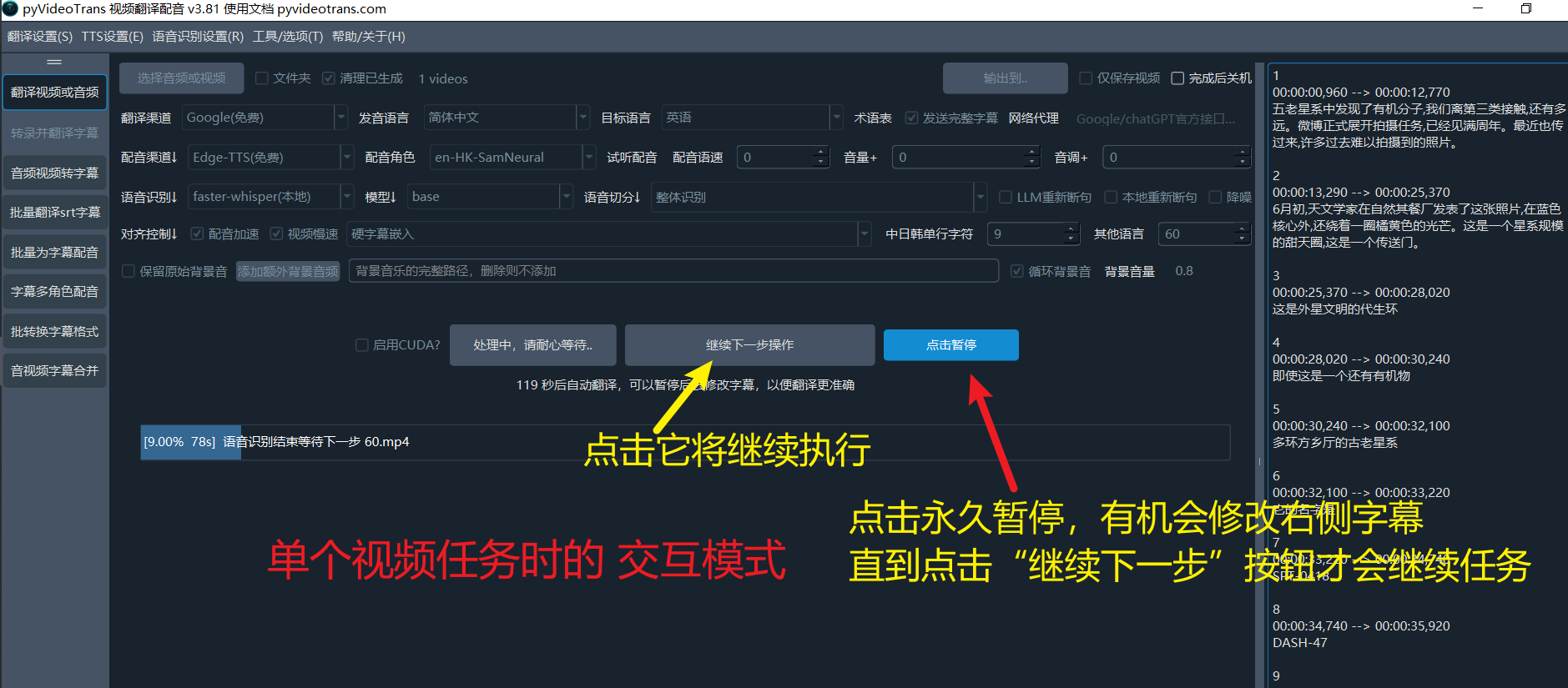
四、 交互式单视频处理模式
为了满足用户在处理单个视频时对字幕精准度的更高要求,pyvideotrans 设计了独特的 “交互式单视频处理模式”。此模式的核心是在自动化流程中引入了人工干预节点,允许用户在关键步骤暂停任务,手动校对和修正中间结果。
设计动机
在处理单个重要视频时,用户往往希望:
- 修正语音识别结果:在语音转录(ASR)完成后,手动修正识别错误的文字,以保证原始字幕的准确性。
- 润色字幕翻译文本:在字幕翻译完成后,对机器翻译的结果进行调整和润色,使其更符合语境和表达习惯,从而提升最终配音的质量。
传统的七线程流水线架构专为高吞吐量的批量处理而设计,任务在线程间自动流转,无法满足单任务下“执行-暂停-校对-继续”的交互式需求。
实现原理
针对此场景,软件采用了不同的处理模型:
专用工作线程: 当用户选择仅处理一个视频时,程序会启动一个专用的工作线程
Worker(QThread)(位于videotrans/task/_only_one.py) 来负责整个流程。串行执行流程: 在此专用线程内部,任务将以串行方式被依次调用执行,而非在多个线程的队列中传递。这确保了流程的每一步都严格按照预设顺序进行。
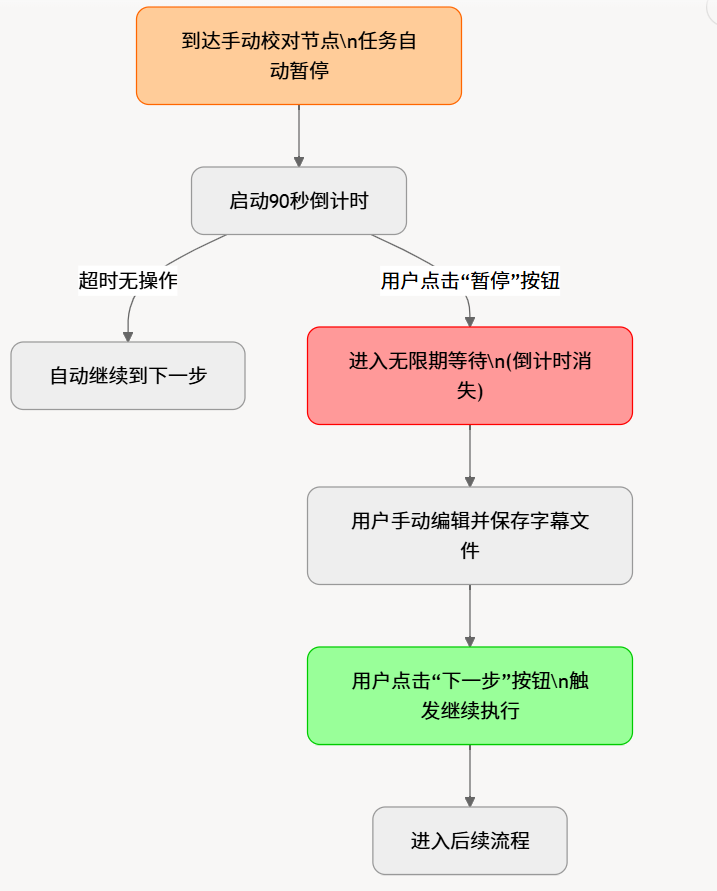
手动校对节点 (Pause Points): 在流程中设置了两个关键的暂停点。
完整的串行流程如下: 数据预处理 → 语音转录 → [手动校对节点 1] → 字幕翻译 → [手动校对节点 2] → 配音 → 音画对齐 → 视频合成 → 任务收尾
暂停与继续机制
在到达“手动校对节点”时,任务会自动暂停,并为用户提供灵活的交互选项:
- 自动继续倒计时: 暂停时,界面会启动一个 90 秒倒计时。如果用户在此期间未进行任何操作,倒计时结束后任务将自动进入下一步。
- 无限期暂停: 用户可以随时点击界面上的**“暂停”按钮**,此时倒计时会消失,任务将进入无限期等待状态,给予用户充足的时间进行字幕文件的编辑和保存。
- 手动触发继续: 当用户完成校对工作后,需要手动点击“下一步”按钮,以触发后续流程的执行。

通过这种设计,pyvideotrans 在保证批量处理效率的同时,也为追求高质量的单视频翻译任务提供了精细化控制的可能。
五、 软件启动与 UI 实现
开发框架: 软件界面基于
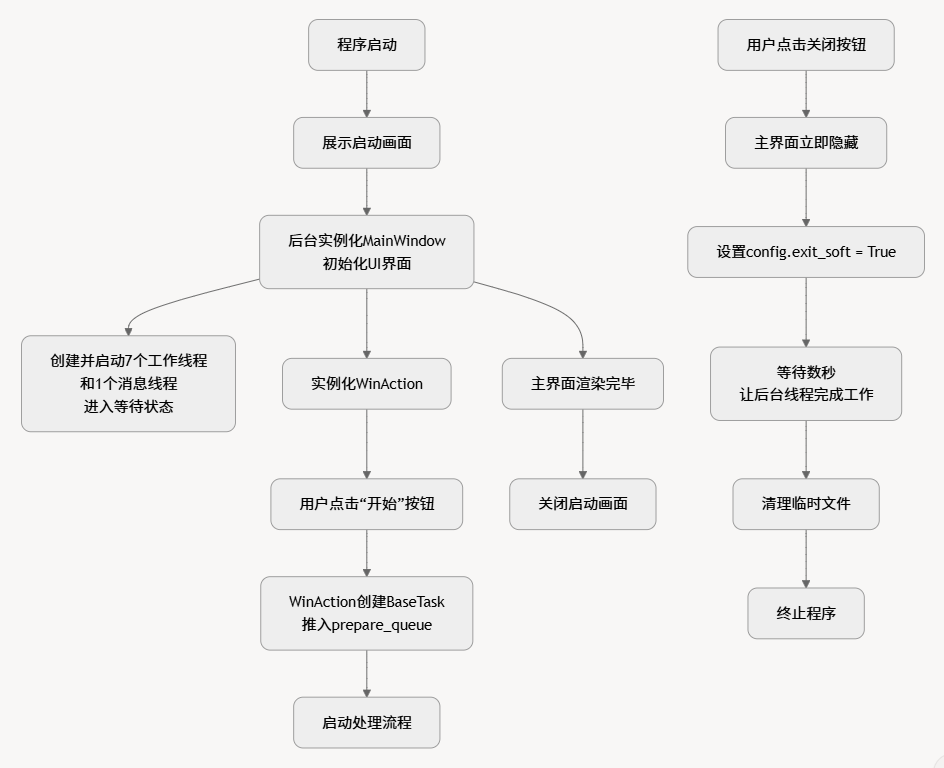
PySide6框架开发。启动过程:
- 程序启动时,首先展示一个启动画面。
- 后台实例化主窗口类
MainWindow(videotrans/mainwin/_main_win.py),并初始化 UI 界面。 - 同时,创建并启动前述的 7 个工作线程和 1 个消息线程,让它们进入等待状态。
- 实例化任务启动类
WinAction(videotrans/mainwin/_actions.py)。当用户在界面上点击“开始”按钮时,由WinAction负责创建BaseTask任务对象,并将其推入流水线的第一个队列 (prepare_queue),从而启动整个处理流程。 - 主界面渲染完毕后,关闭启动画面。
安全退出: 当用户点击关闭按钮时,主界面会立即隐藏。程序将退出标志位
config.exit_soft设为True,并等待数秒,以给予所有后台线程充足的时间来完成当前工作并安全退出,之后再清理临时文件并终止程序。UI 结构:
- UI 定义: 所有窗口和控件的布局定义在
videotrans/ui包中。 - UI 实现:
videotrans/component/set_form.py中的类负责将 UI 定义与业务逻辑连接起来。 - 窗口与动作控制:
videotrans/winform包负责管理各个子窗口的创建、显示和事件响应,实现了 UI 与业务逻辑的解耦。
- UI 定义: 所有窗口和控件的布局定义在
六、 代码结构概览
/
├── sp.py # 主程序入口
├── models/ # 存放本地 AI 模型文件
├── uvr5_weights/ # 人声/背景声分离模型权重
├── logs/ # 日志文件目录
└── videotrans/ # 核心业务逻辑代码
├── component/ # UI 组件的调用入口和通用件
├── configure/ # 配置信息、队列定义、顶层基类
├── language/ # 界面多语言 JSON 文件
├── mainwin/ # 主窗口界面与逻辑
├── process/ # faster-whisper 的独立进程实现
├── prompts/ # AI 提示词模板
├── recognition/ # 语音识别 (ASR) 模块
├── separate/ # 人声背景分离模块
├── styles/ # UI 样式 (QSS) 和图标资源
├── task/ # 各类任务处理逻辑(视频翻译、转字幕等)、后台线程启动入口
├── translator/ # 字幕翻译模块
├── tts/ # 文本转语音 (TTS) 模块
├── ui/ # PySide6 UI 定义文件
├── util/ # 通用辅助工具函数
├── voicejson/ # TTS 音色配置文件
└── winform/ # 各子窗口的逻辑与管理