本文讲述如何使用语音识别渠道中的字节语音识别大模型极速版
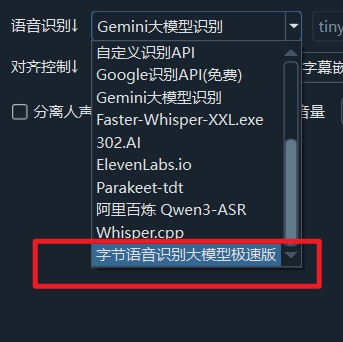
请注意,这里说的是
字节语音识别大模型极速版,和字节火山字幕生成渠道不是一回事。另外字节火山中有一大堆名称类似的各种语音识别服务,必须使用指定的这个
录音文件识别--语音识别大模型极速版API才可以。对应的字节文档地址 https://www.volcengine.com/docs/6561/1631584
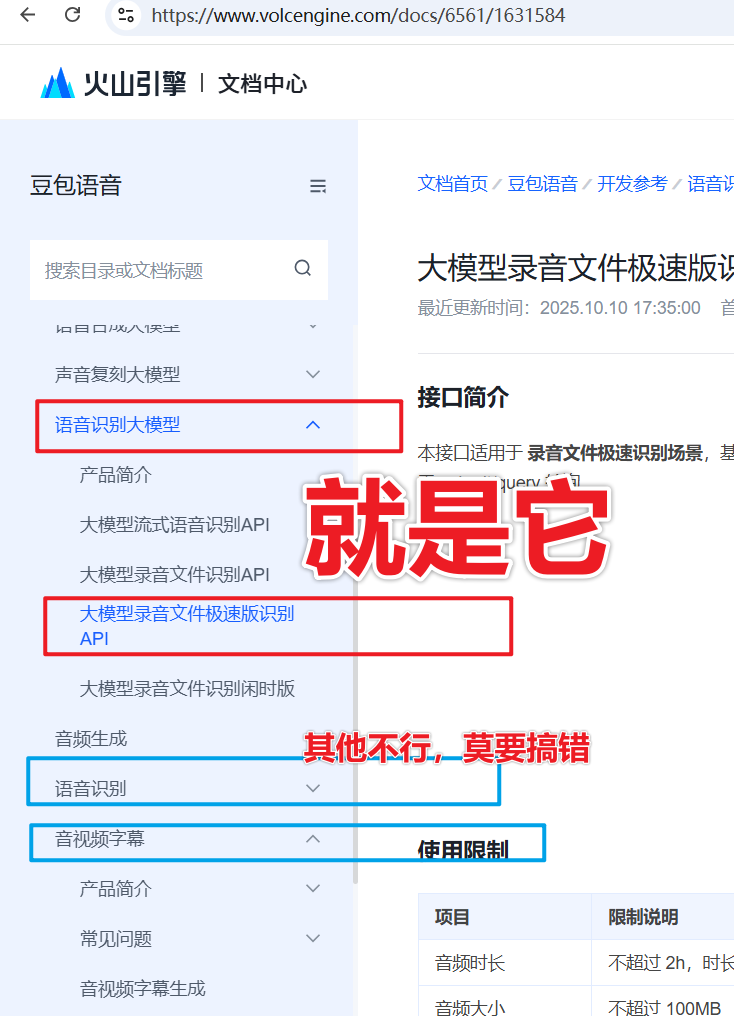
首先登陆注册火山引擎
打开火山登陆地址 https://console.volcengine.com/auth/login ,若无账号,当然需要先注册了,还需要实名认证。
进入火山后台可能看起来很凌乱,建议登陆后直接打开这个地址,进入应用创建管理 https://console.volcengine.com/speech/app ,否则新手极可能一不小心去创建了智能体应用,这个自然无法在本软件中使用。
然后左上角选择旧版,新版很多地方信息不明,新手可能难以找到正确位置
创建一个应用
上步登陆并实名认证后,打开该地址进入应用创建管理( https://console.volcengine.com/speech/app ),请再次确认左上角是使用的旧版。
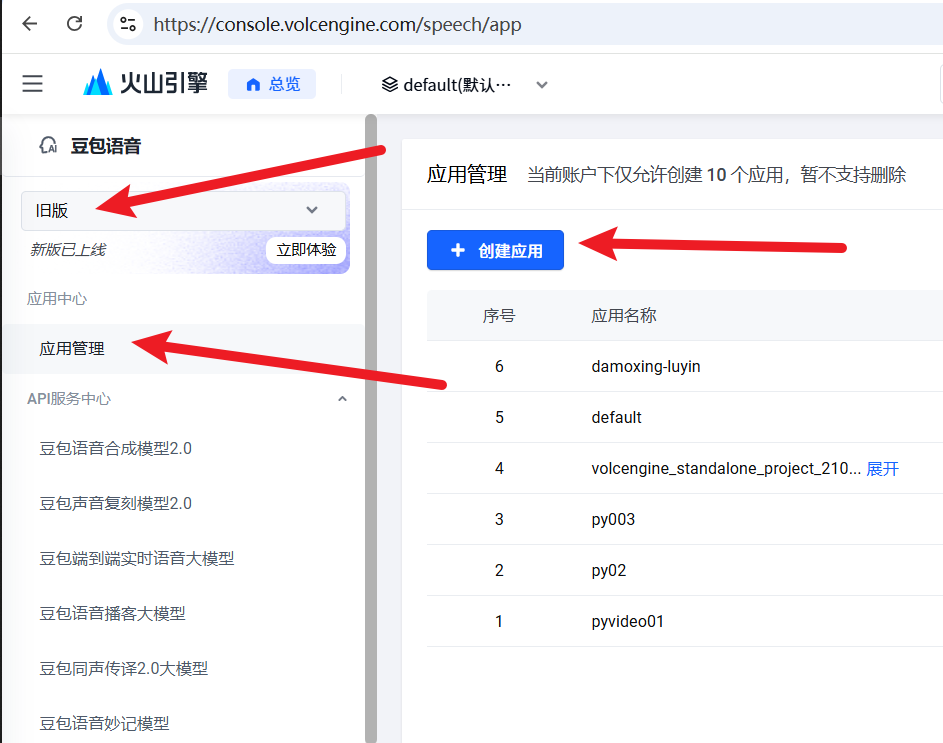
点击 "创建应用",名字填写英文,描述随意,重要的是下方的一堆复选框,选中录音文件识别大模型--录音文件识别大模型 极速版,这是必须的,其他均可以不选。
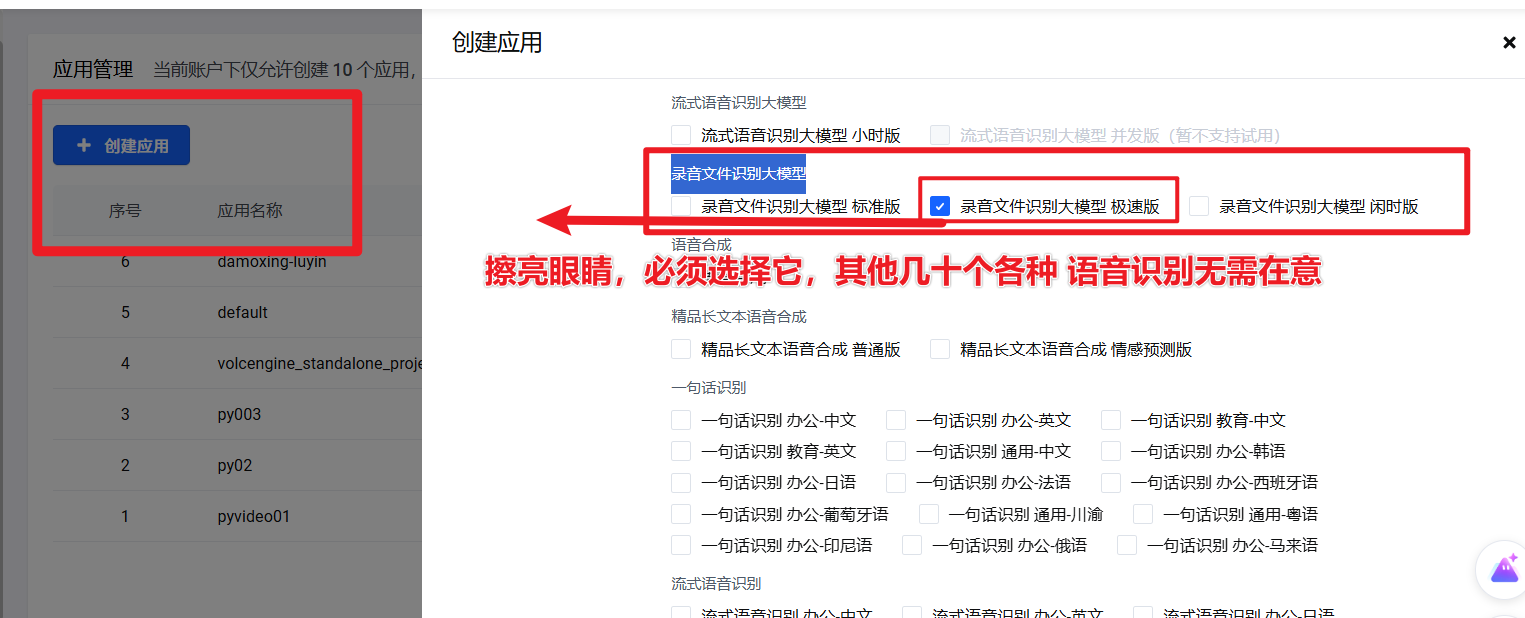
特别注意:这里大堆名称相似的 语音识别,请必须精准选择录音文件识别大模型--录音文件识别大模型 极速版,否则使用中肯定报错
为什么必须极速版?因为标准版要求传递一个音视频文件的外网url地址,也就是必须将你本地的文件上传到某个服务器,然后将url地址给字节,字节再从服务器下载该文件,这显然不合适
点击确定,继续下一步 获取 APP ID 和 Access Token
获取 Access Token / 开通正式版
请再次确认左上角是旧版,然后左侧菜单依次打开API服务中心--语音识别大模型--录音文件识别大模型,选择的产品若不对,肯定无法正常使用。
也可以直达该地址 https://console.volcengine.com/speech/service/10012
你将能看到已创建的所有应用,选择你要使用的那个。
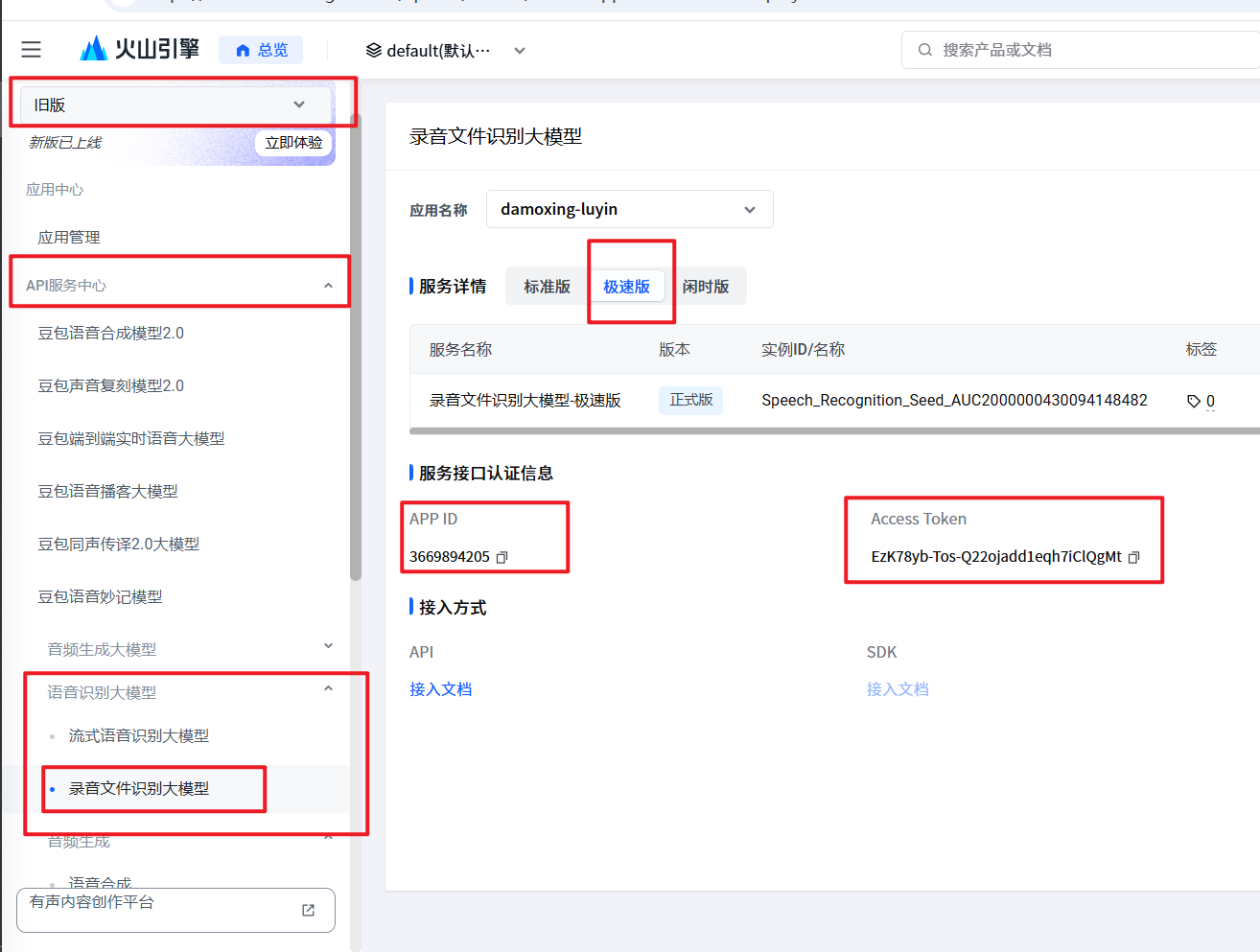
如上图,选择你要使用的的应用,然后必须选择极速版,如果你没有看到极速版标签,说明你搞错了菜单,请左上角切到旧版,重新寻找。
拉到页面底部找到“服务接口认证信息”处,复制 APP ID 和 Access Token, 代码中将用到这2个信息。
在 pyVideoTrans 软件中使用
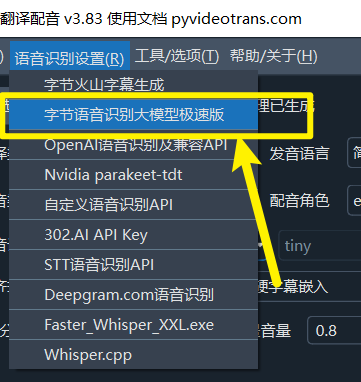
特别注意,
字节语音识别大模型极速版和字节火山字幕生成是2个不同东西,需要分别单独设置
打开 pyVideoTrans 视频翻译配音软件,找到
菜单-语音识别设置-字节语音识别大模型极速版将APP ID 填入,将 Access Token填入
保存,到主界面中选择 “字节语音识别大模型极速版” 就可以了