高级设置各个选项说明
在顶部菜单--工具/选项--高级选项 中可对一些参数进行自定义,以便实现更精细的控制。如下图。
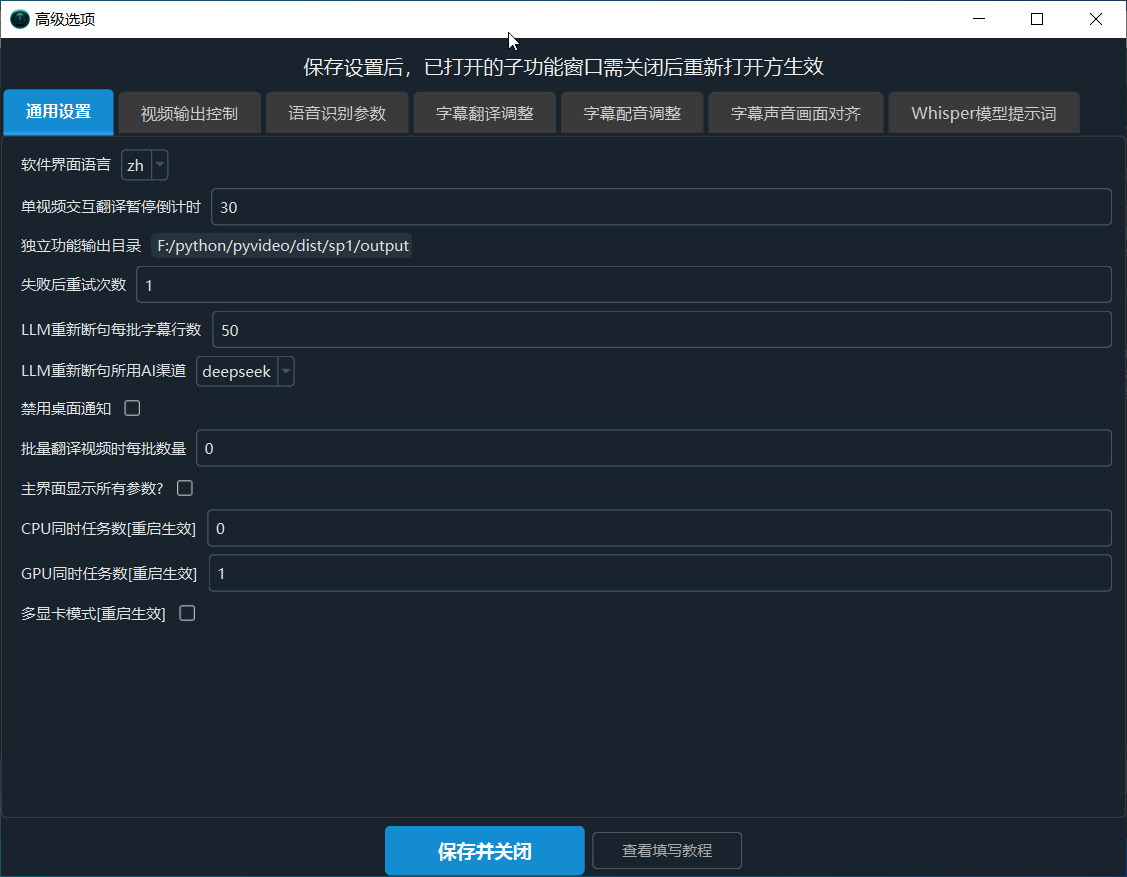
【通用设置】
软件界面语言: 设置软件界面语言,修改后需要重启软件单视频交互翻译暂停倒计时: 当单视频交互翻译时,暂停倒计时秒数(设为0将跳过编辑窗口)独立功能输出目录: 用于设置 批量语音转录 / 批量为字幕配音 / 批量翻译srt字幕 等功能的输出结果位置,非视频翻译结果保存位置,默认软件安装目录 下output文件夹失败后重试次数: 失败后重试次数(针对重试可能恢复的错误,在此设定重试次数)LLM重新断句每批字幕行数: LLM大模型重新断句时,每次发送多少条字幕,该值越大断句效果越好,一次性发送全部字幕最佳,但受限于最大输出token和上 下文(max_token),过长输入可能导致超出AI限制而失败,默认20条字幕LLM重新断句所用AI渠道: LLM重新断句时使用的AI渠道,目前支持 OpenAI-ChatGPT 或 DeepSeek 渠道禁用桌面通知: 任务完成或失败后不显示桌面通知批量翻译视频时每批数量: 批量翻译视频时,在此设置每批次同时翻译几个,默认0即不限制主界面显示所有参数?: 为避免过多参数造成困扰,主界面默认隐藏大部分参数,如果选中这里将切换为默认显示所有参数CPU同时任务数[重启生效]: 最大CPU同时任务数,越大越快但可能爆内存,最大不应超过cpu核数 (修改保存后重启生效)GPU同时任务数[重启生效]: GPU任务同时执行数量,除非多卡或单卡显存大于24G,否则请设为1 (修改保存后重启生效)多显卡模式[重启生效]: 如果有多张显卡,可启用该项,同时可将上述选项设为2或显卡数 (修改保存后重启生效)
【视频输出控制】
视频输出质量控制: 视频转码时损失控制,0=无损但视频会超级大,51=质量差文件小输出视频压缩率: 主要调节编码速度和质量的平衡,有 ultrafast、superfast、veryfast、faster、fast、medium、slow、slower、veryslow 选项,编码速 度从快到慢、压缩率从低到高、视频尺寸从大到小。264/265编码: 采用 libx264 编码或 libx265 编码,264兼容性更好,265压缩比更大清晰度更高输出视频格式(mp4/mkv): 输出视频格式(mp4/mkv)可变帧率vfr/固定帧率cfr: 有视频慢速处理时,可变帧率vrf效果更好,固定帧率cfr兼容性更佳强制软编码视频?: 强制ffmpeg使用软编解码?(速度慢但兼容性好不易出错,默认优选硬件编码)视频合成cuda硬解码: 最后一步视频合成时,强制使用cuda解码视频,更快但易出错自定义ffmpeg命令参数: 自定义ffmpeg命令参数, 将添加在输出文件之前的位置,例如 -bf 7 -b_ref_mode middle
【语音识别参数】
选择VAD: 选择要使用的VAD语音阈值: 表示音频片段被认为是语音的最低概率。VAD 会为每个音频片段计算语音概率,超过此阈值的部分被视为语音,反之视为静音或噪音。越小越灵敏 但可能误将噪声视为语音非语音阈值: 减小可降低幻觉但可能遗漏文字最长语音持续(秒): 最长语音持续时长(秒),限制单个语音片段的最大长度。超过此时长时强制分割。填写数字,单位是秒最短语音持续(毫秒): 最短语音持续时长(毫秒),如果某条字幕时长小于该ms,则尝试将该字幕合并进相邻字幕中,单位是毫秒二次识别最长语音持续(秒): 二次识别最长语音持续时长(秒),限制单个语音片段的最大长度。超过此时长时强制分割。填写数字,单位是秒二次识别最短语音持续(毫秒): 二次识别最短语音持续时长(毫秒),如果某条字幕时长小于该ms,则尝试将该字幕合并进相邻字幕中,单位是毫秒静音分割持续毫秒: 在语音结束时,需等待的静音时间达到此值后,才会分割出语音片段。填写数字,单位ms 也就是只在大于此值的静音片段处分割合并过短字幕到邻近: 只有选中该项,才会合并短字幕Whisper预分割音频?: 是否提前将音频切割为句子片段后再发给whisper模型识别? 若使用clone配音角色,请选中,并将最短语音设为3000,最大语音设为10,提供语音克隆可靠性说话人分离模型: 用于说话人分离的模型,默认内置模型支持中英. 若选 pyannote 必须拥有 https://huggingface.co 上的token, 并且同意pyannote组织的授权协议
具体请访问URL查看教程: https://pvt9.com/shuohuaren
Huggingface的token: 填写你在 huggingface.co 的token,否则无法使用 pyannote,具体查看教程 https://pvt9.com/shuohuaren计算数据类型: faster模式时计算数据类型,int8=消耗资源少,速度快,精度低,float32=消耗资源多,速度慢,精度高,float16适合GPU加速。default默 认自选识别准确度beam_size: 字幕识别时精度调整,1-5,1=消耗显存最低,5=消耗显存最多识别准确度best_of: 字幕识别时精度调整,1-5,1=消耗显存最低,5=消耗显存最多启用上下文感知: 若开启将占用更多GPU,效果也更好,但也容易出现重复或幻觉重复惩罚: 增大该值有利于减少重复文本压缩率: 减小该值有利于减少重复采样温度: 采样温度热词: 告诉模型哪些词可能出现,以英文逗号分隔多个faster-whisper模型: faster-whipser的模型列表,英文逗号分隔whisper.cpp模型: whisper.cpp的模型名字列表,英文逗号分隔Gemini语音识别每批切片数: 使用gemini识别语音时,每次发送音频切片数,越大效果越好,但失败率会升高字幕繁体转简体: 强制将识别出的繁体字幕转为简体删除字幕末尾标点?: 删除字幕末尾标点?云API识别暂停秒: 云API每次识别后暂停秒数,防止超过频率限制
【字幕翻译调整】
传统翻译渠道每批字幕行数: 传统翻译渠道每次发送字幕行数AI翻译渠道每批字幕行数: AI翻译渠道每次发送字幕行数AI翻译一次性翻译所有字幕行: AI翻译渠道一次性翻译字幕所有行,翻译质量最佳 【务必注意】1. 必须使用支持超长上下文的先进模型(在线AI旗舰模型)
- 需要将对应AI渠道设置界面中的max token设为较大值,否则长篇输出可能被截断而报错
- 可能反馈较慢,表现为迟迟未返回数据
翻译后暂停秒: 每次翻译后暂停秒数,用于限制请求频率发送完整字幕: 是否在使用AI翻译渠道时发送完整字幕格式内容AI翻译模型温度值: AI翻译模型温度值,默认1.0
【字幕配音调整】
并发配音线程数: 同时配音的线程数配音后暂停秒: 每次配音后暂停秒数,用于限制请求频率移除配音前后静音缓冲: 移除每条字幕配音前后静音缓冲,利于音画同步,但可能结尾仓促保留每条字幕的配音文件: 保留每行字幕的配音结果文本规范化: 配音前对文本规范化处理ChatTTS音色值: ChatTTS 音色值EdgeTTS配音渠道配音并发数: EdgeTTS渠道配音并发数,越大越快,但可能限流失败EdgeTTS配音渠道失败重试次数: EdgeTTS渠道失败后重试次数,有些失败无论多少次重试也无法恢复,太大只会延长耗时人声背景分离线程数: 人声背景声分离线程数,越大越快但占用资源越多分离背景声模型: 选择分离背景声时所用模型
【字幕声音画面对齐】
音频加速最大倍数: 最大音频加速倍数,默认100视频慢放最大倍数: 视频慢放最大倍数,默认10,不可大于10中日韩字幕单行字符数: 中日韩字幕单行字符数,多于将换行,仅针对视频翻译中的目标字幕或单独的语音转录功能字幕其他语言字幕单行字符数: 其他语言字幕单行字符数,多于将换行,仅针对视频翻译中的目标字幕或单独的语音转录功能字幕
【Whisper模型提示词】
whisper模型简体中文提示词: 发音语言为简体中文时发送给whisper模型的提示词whisper模型繁体中文提示词: 发音语言为繁体中文时发送给whisper模型的提示词whisper模型英语提示词: 发音语言为英语时发送给whisper模型的提示词whisper模型法语提示词: 发音语言为法语时发送给whisper模型的提示词whisper模型德语提示词: 发音语言为德语时发送给whisper模型的提示词whisper模型日语提示词: 发音语言为日语时发送给whisper模型的提示词whisper模型韩语提示词: 发音语言为韩语时发送给whisper模型的提示词whisper模型俄语提示词: 发音语言为俄语时发送给whisper模型的提示词whisper模型西班牙语提示词: 发音语言为西班牙语时发送给whisper模型的提示词whisper模型泰国语提示词: 发音语言为泰国语时发送给whisper模型的提示词whisper模型意大利语提示词: 发音语言为意大利语时发送给whisper模型的提示词whisper模型希腊语提示词: 发音语言为希腊语时发送给whisper模型的提示词whisper模型高棉语提示词: 发音语言为高棉语时发送给whisper模型的提示词whisper模型挪威语提示词: 发音语言为挪威语时发送给whisper模型的提示词whisper模型葡萄牙语提示词: 发音语言为葡萄牙语时发送给whisper模型的提示词whisper模型越南语提示词: 发音语言为越南语时发送给whisper模型的提示词whisper模型阿拉伯语提示词: 发音语言为阿拉伯语时发送给whisper模型的提示词whisper模型土耳其语提示词: 发音语言为土耳其语时发送给whisper模型的提示词whisper模型印度语提示词: 发音语言为印度语时发送给whisper模型的提示词whisper模型匈牙利语提示词: 发音语言为匈牙利语时发送给whisper模型的提示词whisper模型乌克兰语提示词: 发音语言为乌克兰语时发送给whisper模型的提示词whisper模型印尼语提示词: 发音语言为印尼语时发送给whisper模型的提示词whisper模型马来语提示词: 发音语言为马来西亚语时发送给whisper模型的提示词whisper模型哈萨克语提示词: 发音语言为哈萨克语时发送给whisper模型的提示词whisper模型捷克语提示词: 发音语言为捷克语时发送给whisper模型的提示词whisper模型波兰语提示词: 发音语言为波兰语时发送给whisper模型的提示词whisper模型荷兰语提示词: 发音语言为荷兰语时发送给whisper模型的提示词whisper模型瑞典语提示词: 发音语言为瑞典语时发送给whisper模型的提示词whisper模型希伯来语提示词: 发音语言为瑞典语时发送给whisper模型的提示词whisper模型孟加拉语提示词: 发音语言为瑞典语时发送给whisper模型的提示词whisper模型波斯语提示词: 发音语言为波斯语时发送给whisper模型的提示词whisper模型乌尔都语提示词: 发音语言为乌尔都语时发送给whisper模型的提示词whisper模型粤语提示词: 发音语言为粤语时发送给whisper模型的提示词whisper模型罗马尼亚语提示词: 发音语言为罗马尼亚语时发送给whisper模型的提示词whisper模型菲律宾语提示词: 发音语言为菲律宾语时发送给whisper模型的提示词