快速使用入门
本教程将带您从零开始完成第一个视频翻译任务。
核心功能一览
- 全自动视频翻译、音频翻译:智能识别转录音视频中的说话声,生成源语言字幕文件,再翻译为目标语言字幕文件,接着进行配音,最后将新的音频与字幕合成到原视频中,一气呵成(左侧功能面板:翻译视频和音频)。
- 语音转录/音视频转字幕:批量将视频或音频文件中的人类说话声,精准转录为带时间轴的 SRT 字幕文件(左侧功能面板:批量语音转字幕)。
- 语音合成/文字转语音 (TTS):利用多种先进的 TTS 渠道,为您的文本或 SRT 字幕文件生成高质量、自然流畅的配音(左侧功能面板:批量为字幕配音)。
- SRT 字幕文件翻译:支持批量翻译 SRT 字幕文件,保留原有时间码和格式,并提供多种双语字幕样式(左侧功能面板:批量翻译srt字幕)。
一、软件工作原理
pyVideoTrans 的核心功能是「视频翻译」,将一个语言的视频自动翻译成另一个语言:
[原始视频] --> [语音识别] --> [字幕翻译] --> [语音合成] -->
--> [音画同步对齐] --> [输出翻译视频]通俗解释:
- 语音识别:像听写员一样,把视频里人物说的话逐字听写成字幕
- 字幕翻译:把听写出来的字幕翻译成目标语言
- 语音合成:用 AI 语音把翻译后的字幕"读"出来,生成配音
- 同步对齐:把新的配音和原视频画面重新对齐,确保声音和画面同步
整个过程完全自动化,您只需选择文件和设置参数,点击开始即可。
- 可处理范围:任何包含清晰人类语音的音视频(无论视频本身是否有字幕)。
- 无法处理范围:仅有背景音乐/画面但无人声说话的视频。
二、下载与安装
Windows 用户
- 下载预打包版本:点击下载Windows版
- 建议解压到只包含英文及数字的简短路径中(如
D:\pyVideoTrans) - 双击
sp.exe启动
⚠️ 请勿直接在压缩包内运行。如需 GPU 加速,请确保已安装 CUDA 12.8 和 cuDNN 9
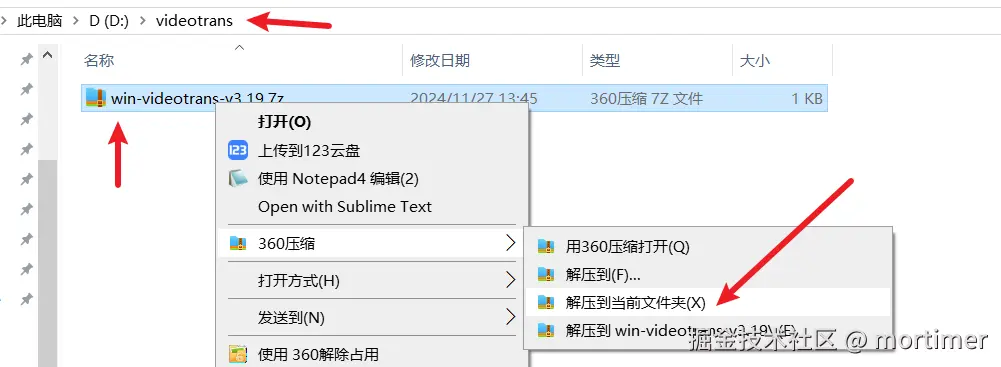
点击查看注意事项,可避免大多数错误
- 不要解压到
C:/Program Files、C:/Windows等需要特殊权限的系统文件夹,因软件生成的文件和临时文件均需要写入解压路径中。 - 推荐将软件解压到仅包含英文和数字的文件夹中,例如
D:/videotrans,然后将压缩包解压到此文件夹内。强烈建议不要包含任何中文、空格或特殊符号,存放路径也不可太深,否则windows上容易出错。 - 待翻译的视频请保持简短的文件名,例如30个字符内长度较好,而上百个字符则太长,叠加路径和其他命令后,在Windows下可能超过系统限制而报错。
文件名中也不要包含":?*等特殊符号,否则Win上同样可能报错,尤其从油管下载的视频,文件名通常超级长,还包括各种特殊符号,若不经修改直接使用,大概率在win系统上会遇到各种错误,建议修改为简短的名称并去除各种特殊符号。  4. Windows下请开启显示扩展名(默认是隐藏的),能避免一些错误,尤其涉及参考音频填写时。
4. Windows下请开启显示扩展名(默认是隐藏的),能避免一些错误,尤其涉及参考音频填写时。
打开任意一个文件夹,点击导航栏--查看--文件扩展名,选中它,选中后mp4视频将会在名称后显示扩展名.mp4,wav音频会显示扩展名.wav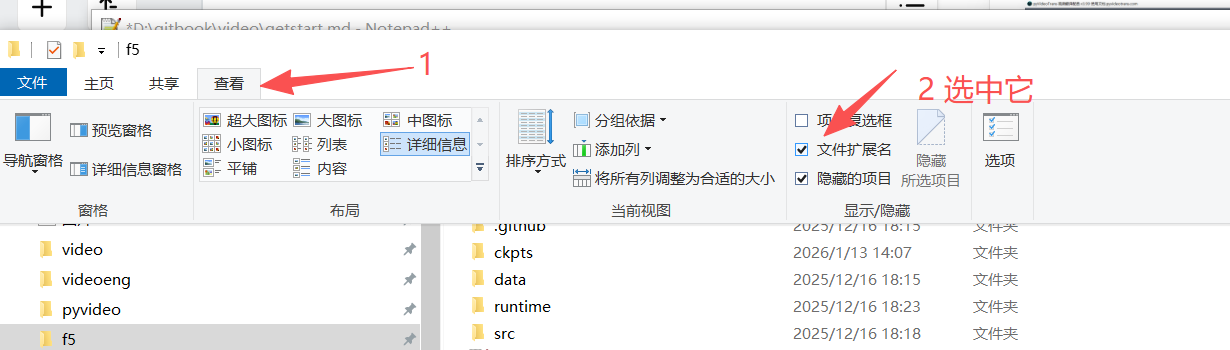
MacOS / Linux 用户查看安装方法
安装依赖:
bash# macOS brew install libsndfile git brew tap homebrew-ffmpeg/ffmpeg brew install homebrew-ffmpeg/ffmpeg/ffmpeg # Ubuntu/Debian sudo apt-get install ffmpeg libsndfile1-dev安装 uv:
bashcurl -LsSf https://astral.sh/uv/install.sh | sh克隆并启动:
bashgit clone https://github.com/jianchang512/pyvideotrans.git cd pyvideotrans uv sync uv run sp.py
三、界面概览
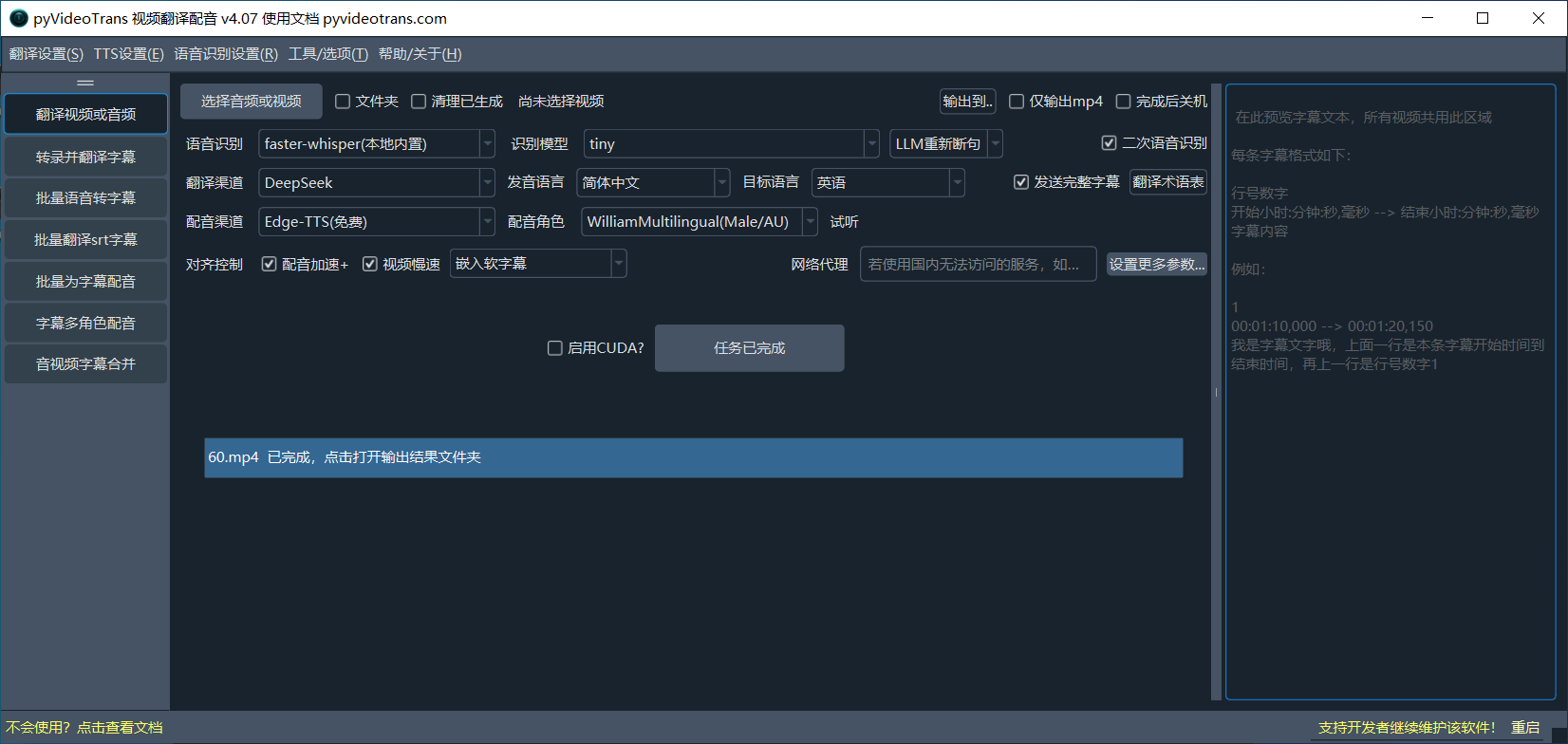
启动软件后,主界面从上到下分为以下几行:
| 行 | 内容 | 说明 |
|---|---|---|
| 第1行 | 选择视频 | 支持 mp4/mkv/avi/mov/wav/mp3 等格式 |
| 第2行 | 语音识别 | 选择识别渠道和模型,用于将说话声转为字幕 |
| 第3行 | 翻译字幕 | 选择翻译渠道、源语言和目标语言,用于翻译上一步识别出的字幕 |
| 第4行 | 字幕配音 | 选择配音渠道和发音角色,为翻译好的字幕进行配音 |
| 第5行 | 同步对齐 | 音频加速、视频慢速、语速音量、嵌入字幕 |
| 第6行 | 开始执行 | 点击后开始处理 |
| 第7行 | 进度条 | 显示处理进度,点击打开输出文件夹 |
| 第8行 | 更多参数 | 降噪、背景声处理等高级选项 |
点击查看各个功能截图预览
- 左侧功能区。
- 翻译视频和音:智能识别转录音视频中的说话声,生成源语言字幕文件,再翻译为目标语言字幕文件,接着进行配音,最后将新的音频与字幕合成到原视频中,一气呵成()。
- 批量语音转字幕:批量将视频或音频文件中的人类说话声,精准转录为带时间轴的 SRT 字幕文件。
- 批量为字幕配音:利用多种先进的 TTS 渠道,为您的文本或 SRT 字幕文件生成高质量、自然流畅的配音。
- 批量翻译srt字幕:支持批量翻译 SRT 字幕文件,保留原有时间码和格式,并提供多种双语字幕样式。
- 音视频字幕合并:将音频、视频、字幕三者合并为一个视频文件

顶部菜单栏:进行全局配置。

翻译设置:配置各个翻译渠道(如OpenAI , Azure, DeepSeek )的API Key和相关参数。
TTS设置:配置各配音渠道(如OpenAI TTS, Azure TTS)的API Key和相关参数,以及设置参考音频。
语音识别设置:配置语音识别渠道(如OpenAI API, 阿里ASR)的API Key和参数。
工具/选项:包含各种高级选项和辅助工具,如字幕格式调整、视频合并、人声分离等。
- 帮助/关于:查看软件版本信息、文档和社区链接。
免费/本地API/本地内置 是什么意思
- 免费: 例如 Google翻译、微软翻译、Edge-TTS配音,这些渠道都是在线免费使用的,无需配置开箱即用,只是需注意有限流错误,高频使用时可能会遇到报错
- 本地API: 很多开源模型可自行在本地部署,部署并启动后,将API地址或WebUI地址填写在 pyVideoTrans 软件设置界面,软件即可通过该地址调用你部署的模型服务。例如 GPT-SoVITS / CosyVoice 等
- 本地内置: 有些模型可以相对方便的集成到 pyVideoTrans 软件内,而无需单独另行部署,开箱可用,例如 VITS/Piper/Qwen3-TTS/ OmniVoice / F5-TTS / Qwen3-ASR/SuperionTTS/ChatterBox等,但需要注意,为避免软件体积无限膨胀,仅调用代码内置,模型本身并未内置,第一次使用时需在线下载模型。
四、第一次翻译:详细步骤
以「将中文视频翻译成英文」为例。
步骤 1:选择视频文件
点击「选择音频或视频」按钮,选择您要翻译的文件。支持 mp4/mkv/avi/mov/wav/mp3 等格式。
文件夹:勾选此项可批量处理整个文件夹内的所有视频。清理已生成:若需对同一视频重新处理(而不是使用缓存),请勾选此项,否则会使用上次已生成的缓存文件。输出到..:点击此按钮可单独设置翻译后视频的输出目录,不点击指定,则使用默认
- 未勾选
文件夹时默认输出位置: 所选视频同级的_video_out文件夹内,例如所选视频是D:/videos/001.mp4,则输出到D:/videos/_video_out内,每个视频生成一个结果文件夹,名字是{视频名字(不含后缀)}-{视频后缀名}- 若勾选
文件夹时默认输出位置:所选文件夹同级的_video_out/{该文件夹名}下,例如所选文件夹是D:/videos/ceshi, 输出到D:/videos/_video_out/ceshi文件夹内,每个视频生成一个结果文件夹,名字是{视频名字(不含后缀)}-{视频后缀名}
仅输出mp4:如果选中,则输出中只保留最终的翻译视频,其他字幕、音频等文件都会自动删除。完成后关机:处理完所有任务后自动关闭计算机,适合大批量、长时间任务。
步骤 2:选择语音识别渠道
| 渠道 | 推荐场景 | 说明 |
|---|---|---|
faster-whisper(本地内置) | 默认推荐 | 速度快、质量高 |
openai-whisper(本地内置) | 高精度需求 | 准确度略高,速度较慢 |
Qwen-ASR(本地内置) | 中文及其他十多种常见语言 | 中文识别效果好,速度慢 |
阿里FunASR(本地内置) | 中文识别效果好,可选 paraformer/sensevoice/Fun-ASR-Nano多种模型 | |
Firered中文(本地内置) | 中文及方言视频 | 小红书开源模型 |
parakeet日语(本地内置) | 日语视频 | 英伟达开源模型 |
Dolphin亚洲语言(本地内置) | 东亚语言、东南亚及中东语言 | 专注亚洲小语种 |
OmnilingualASR(本地内置) | 支持所有内置语言,范围广 | facebook开源,支持语言多但效果不佳 |
模型选择:
tiny→ 最快,准确度低base/small→ 平衡之选medium→ 较好效果large-v3→ 最佳效果,需要 8GB+ 显存large-v3-turbo→ 推荐,速度与质量兼顾
二次识别、LLM重新断句
- 二次识别:在选择了
配音角色并选择了嵌入单字幕时,可选中二次识别,将在配音完毕后再次对配音文件进行语音转录,生成较为简短的字幕嵌入视频内,确保字幕和配音精确对齐
在
高级选项--语音识别区域设置二次识别的最长语音持续时间和最短语音持续时间,设置较小的值有利于生成短小字幕注意:在对生成后的配音进行二次识别时,仍会使用语音识别渠道里所选渠道和模型,你需要确保所用渠道支持识别
目标语言,否则会得到错误的识别结果。例如
发音语言(视频说话语言)是中文,目标语言(翻译后配音)是日语,所选语音识别渠道为Firered中文,而渠道不支持日语,若选中二次识别,最后得到的字幕可能是乱码或完全错误的文字
默认断句和LLM重新断句:
- 默认断句:是指使用识别模型返回的断句结果或VAD的断句结果,不进行其他处理
- LLM重新断句:是指在语音识别出字幕文本后,将文本发送给AI大模型,修正错别字、重新切分长文本等,以得到更通顺流畅的结果,需配置DeepSeek或OpenAI ChatGPT。可在菜单-工具--高级选项-通用-LLM断句模型里选择,但注意使用LLM重新断句后结果也可能更糟糕,效果取决于AI大模型本身智能。
在克隆原音色(即配音角色是
clone)时,强烈不建议使用该断句方式,默认即可。启用说话人分离后,会禁用LLM重新断句,以避免降低说话人识别精度
LLM重新断句的提示词在
软件目录/videotrans/prompts/resegment/llm.txt中,可自行修改调整同时选中二次识别和LLM重新断句:将在二次识别后,对识别结果再次使用 LLM重新断句,提示词在文件
软件目录/videotrans/prompts/resegment/llm2.txt中
步骤 3:选择翻译渠道
| 渠道 | 说明 |
|---|---|
Google(免费) | 翻译质量尚可,国内需要科学上网 |
Microsoft(免费) | 无需代理,可能限流 |
M2M100(本地内置) | 本地模型翻译 |
Hy-MT2(本地内置) | 腾讯混元模型翻译 |
| DeepSeek | AI大模型翻译质量佳,DeepSeek 物美价廉推荐使用 |
然后选择发音语言(视频中人物说的语言)和目标语言(希望翻译成的语言)。
步骤 4:选择配音渠道
| 渠道 | 说明 |
|---|---|
Edge-TTS(免费) | 默认推荐,微软免费接口,声音自然 |
Qwen3-TTS(本地内置) | 阿里本地模型,效果好速度慢,支持克隆 |
F5-TTS(本地内置) | 中英,支持克隆 |
OmniVoice(本地内置) | 支持所有内置语言,支持克隆 |
Confucius(本地内置) | 支持14种语言,支持克隆 |
ChatterBox(本地内置) | 多语言,欧洲语言效果好,支持克隆 |
ZipVoice中英(本地内置) | 支持中英语言,支持克隆 |
Moss-TTS-Nano(本地内置) | 多语言,支持克隆 |
gTTS(免费) | 多语言,google家的,国内需科学上网 |
选择渠道后,在「配音角色」下拉框中选择发音人。配音角色选中clone,代表将使用原始视频对应的音色进行配音
步骤 5:调整同步与字幕
| 参数 | 默认值 | 说明 |
|---|---|---|
| 配音加速 | ✅ 选中 | 配音比原视频长时,加速配音匹配时长 |
| 视频慢速 | ☐ 不选 | 配音比原视频长时,放慢视频匹配配音 |
| 字幕嵌入类型 | 嵌入软字幕 | 字幕嵌入到画面(若需网页播放,请选嵌入硬字幕) |
字幕类型:
- 不嵌入字幕:只替换声音
- 嵌入硬字幕:字幕永久烧录到画面
- 嵌入软字幕:字幕作为独立轨道,播放器可开关
- 嵌入硬字幕(双语):同时显示原文和译文(二次识别会自动禁用)
- 嵌入软字幕(双语):双语字幕,播放器可开关(二次识别会自动禁用)
步骤 6:开始执行
点击 开始执行 按钮,底部进度条实时显示进度,点击打开输出文件夹,完成后翻译视频自动保存到输出文件夹。
CUDA加速:如果你有英伟达显卡,并且配置好了 CUDA12.8 和 cuDNN9,可选中,语音识别阶段速度数倍提升
单视频模式:如果一次只选择一个视频,将在处理过程中弹出3-4次编辑界面,你可在界面中编辑字幕、重新配音、预览视频等,具体界面和操作方法查看单视频模式
五、更多设置
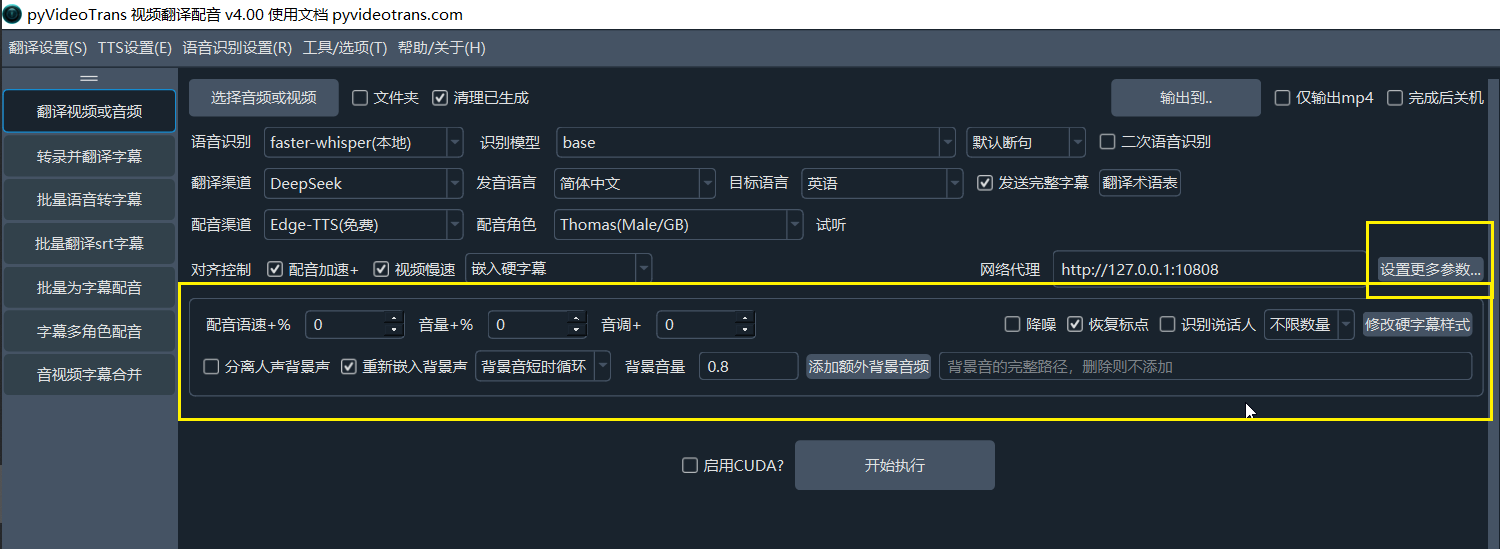
点击「设置更多参数」展开:
| 参数 | 说明 |
|---|---|
| 降噪 | 清除背景噪声 |
| 默认标点/删除标点 | 选择删除标点,会将所有标点使用空格替换 |
| 分离人声背景声 | 将人声与背景音乐分离 |
| 重新嵌入背景声 | 分离后将背景声重新嵌入 |
| 背景音量 | 调整背景音量(0.0-2.0) |
| 配音语速 | 调整配音速度(-50% ~ +50%) |
| 音量调整 | 调整配音音量(-95% ~ +100%) |
| 音调 | 调整配音音调(-100Hz ~ +100Hz) |
六、无损视频输出
确保满足以下所有条件,输出视频保持原始画质:
- 原始视频编码为 H.264 (libx264) 的 MP4 文件
- 不勾选「视频自动慢速」
- 字幕类型选择「不嵌入字幕」或「嵌入软字幕」
- 高级选项中,264/265编码选择
264
七、完整高级选项参考
通过 菜单 -> 工具 -> 高级选项 进入:
通用设置
| 参数 | 说明 | 默认值 |
|---|---|---|
| 软件界面语言 | 修改后需重启 | zh |
| 单视频交互翻译暂停倒计时 | 暂停编辑的秒数 | 30 |
| 独立功能输出目录 | 批量功能的输出位置 | output/ |
| 失败后重试次数 | 可恢复错误的重试次数 | 1 |
| CPU同时任务数 | 最大 CPU 并发数 | 自动 |
| GPU同时任务数 | GPU 并发数 | 1 |
视频输出控制
| 参数 | 说明 | 默认值 |
|---|---|---|
| 视频输出质量控制 (CRF) | 0=无损,51=质量差 | 23 |
| 输出视频压缩率 | ultrafast→veryslow | medium |
| 264/265编码 | 264兼容性好,265压缩比大 | 264 |
| 输出视频格式 | mp4 或 mkv | mp4 |
语音识别参数
| 参数 | 说明 | 默认值 |
|---|---|---|
| 语音阈值 | VAD 语音概率阈值 | 0.5 |
| 最长语音持续(秒) | 超过此时长强制分割 | 6 |
| 最短语音持续(毫秒) | 小于此值合并到相邻字幕 | 3000 |
| 静音分割持续毫秒 | 大于此值的静音处分割 | 140 |
| beam_size | 识别精度 1-5 | 5 |
字幕翻译调整
| 参数 | 说明 | 默认值 |
|---|---|---|
| 传统翻译渠道每批字幕行数 | 每次发送的行数 | 5 |
| AI翻译渠道每批字幕行数 | 每次发送的行数 | 20 |
| 发送完整字幕 | AI翻译时附带时间轴 | 是 |
字幕配音调整
| 参数 | 说明 | 默认值 |
|---|---|---|
| 并发配音线程数 | 同时配音的线程数 | 1 |
| EdgeTTS配音并发数 | 越大越快但可能限流 | 10 |
字幕声音画面对齐
| 参数 | 说明 | 默认值 |
|---|---|---|
| 音频加速最大倍数 | 最大加速倍率 | 100 |
| 视频慢放最大倍数 | 最大慢放倍率 | 10 |
| 中日韩字幕单行字符数 | 超过将换行 | 15 |
八、常见问题
Q: 能否同时启动多个 sp.exe 实例?
可以,但不建议,因多个实例共享同个tmp临时文件夹,并且任意一个实例关闭时,都会尝试清空该临时文件夹,可能导致其他在运行的实例报错。
如果确实需要,建议复制软件到其他文件夹内,然后再启动,例如一个在D:/aivideo下, 再复制一份到D:/aivideo2下,然后分别启动对应文件夹下的sp.exe,这样他们之间就互不影响
Q: 处理速度很慢?
- 确保已启用 GPU 加速(CUDA)
- 使用较小的模型
- 确保显卡驱动已更新
Q: 识别结果不准确?
- 检查「发音语言」是否选择正确
- 尝试更换更大的模型
- 开启「降噪」功能
- 调整「语音阈值」参数
Q: 翻译后声音、字幕、画面不同步?
这是正常现象。不同语言的音节数和语法结构不同,配音时长必然变化。解决方案:
- 启用「音频加速」(默认已启用)
- 可同时启用「视频慢速」
- 设置「配音语速」加快整体速度
Q: 输出视频文件太大?
- 增大「视频输出质量控制」的值(如 25-30)
- 将编码从 264 改为 265
- 关闭「视频慢速」
Q: 如何使用 GPU 加速?
确保已安装 NVIDIA 显卡驱动、CUDA 12.8 和 cuDNN 9.11,然后在主界面勾选「CUDA 加速」。AMD 显卡不支持 CUDA 加速。
Q: 无损视频输出的条件?
原始视频编码为 H.264 MP4 + 不勾选视频慢速 + 不嵌入硬字幕 + 编码选择 264。
Q: 能否提取硬字幕、抹除硬字幕?
本软件无法直接提取或抹除视频画面已经内嵌的硬字幕。
- 如需提取硬字幕,请使用单独的硬字幕提取工具 本地离线提取视频硬字幕。 或 video-subtitle-extractor*
- 如需抹除删除硬字幕,推荐使用github开源项目video-subtitle-remover
相关文档
- 提高 AI 翻译字幕的质量 — 翻译模式对比与术语表使用
- 更好的使用本地大模型作为翻译渠道 — 本地大模型配置指南
- 修改 AI 翻译提示词 — 自定义翻译提示词
- 视频翻译最佳效果推荐 — 每个阶段的最优配置
- 翻译后出现"空白字幕行"的原因与解决方法