faster-whisper(本地)语音识别渠道
渠道简介
faster-whisper 是基于 OpenAI 开源 whisper 模型转换而来的 CTranslate2 实现,正如名字所暗示的,识别速度更快,同时不降低准确度。它是目前 pyVideoTrans 中最常用的本地语音识别渠道。
主要优势:
- 纯本地运行,不会将音频文件上传到互联网,保护隐私
- 识别速度快,比原版 OpenAI whisper 快数倍
- 支持多种语言,识别准确度高
- 支持 CUDA 加速,有 NVIDIA 显卡时可大幅提速
- 首次使用时自动从 HuggingFace 下载模型,之后完全离线可用
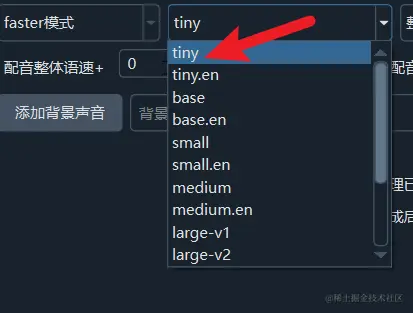
选择faster模式后,即可在右侧选择要使用的模型,第一次使用将在线下载模型,然后就在本地进行语音识别,不会上传你的文件到互联网。
前置条件
在使用 faster-whisper 之前,请确认以下条件:
| 条件 | 说明 |
|---|---|
| 硬盘空间 | 至少预留 5-15GB 用于存放模型文件(大模型更大) |
| 内存 | 基础模型(tiny/base)需 4GB+;large 系列需 16GB+ |
| 显卡(可选) | NVIDIA 显卡 + CUDA 加速可大幅提速,large-v3 需 10GB+ 显存 |
| 网络 | 首次使用需联网下载模型,之后可离线使用 |
模型选择
tiny --> base --> small --> medium --> large-v3-turbo --> large-v1 --> large-v2 --> large-v3
从前到后模型尺寸越来越大,识别精确度也越来越高,需要的内存和显存也越来越多。
建议至少选择大于等于large-v3-turbo的模型,效果最佳的模型是large-v3
以
.en结尾的模型:tiny.en->base.en->small.en->medium.en和以distil开头的模型:distil-large-v3 -> distil-large-v3.5,只可用于英文发音的视频。
模型详细对照表
| 模型名称 | 适用场景 | 内存需求 | 显存需求(CUDA) | 说明 |
|---|---|---|---|---|
| tiny / tiny.en | 快速预览 | 2GB+ | 1GB+ | 速度最快,准确度最低 |
| base / base.en | 简单内容 | 3GB+ | 1GB+ | 适合清晰语音 |
| small / small.en | 一般场景 | 4GB+ | 2GB+ | 速度与准确度较均衡 |
| medium / medium.en | 多语种 | 8GB+ | 5GB+ | 多语种效果好 |
| large-v3-turbo | 推荐起步 | 10GB+ | 6GB+ | 速度快且准确度高 |
| large-v1 | 高精度 | 16GB+ | 10GB+ | 经典大模型 |
| large-v2 | 高精度 | 16GB+ | 10GB+ | 改进版大模型 |
| large-v3 | 最佳效果 | 16GB+ | 10GB+ | 推荐使用,效果最好 |
该渠道最佳配置
为达到最佳语音识别效果,请参考以下设置
- 模型选择
large-v3(确保计算机内存大于16G 或 显存大于10G ),若不满足可尝试使用large-v1/large-v3-turbo模型. - 明确指定发音语言,确保和视频中语音所用语言一致
- 菜单-工具-高级选项-语音识别参数 区域:将
最短语音持续毫秒设为 1000 ,最长语音持续秒数设为大于等于 5 的值,不要选中Whisper预分割音频
此处需注意,如果你需要配音并且配音角色是
clone,即克隆原始发音音色进行配音,那么强烈建议将最短语音持续毫秒设为 3000 ,将最长语音持续秒数设为 10 ,因为 语音克隆时会自动将字幕时长对应的原始语音片段作为参考音频,而多数配音渠道均要求该参考音频时长在 3-10s 之间,否则配音很可能失败。 同时应该选中Whisper预分割音频以及合并过短字幕到相邻,以确保字幕时长能够落在 3-10s 之间
- 如果原始语音不够清晰或者有噪声,请选中 降噪
- 如果你不使用
clone角色,并且希望识别后的字幕尽可能短小,以便适配竖版视频,可适当降低最长语音持续秒数,例如设为 3 或 2. 如果有配音的话,可同时选中二次识别。
二次识别: 在选择配音并选择了嵌入单字幕时,选中二次识别意味着,将在配音完毕后再次对配音后的音频文件进行语音转录,生成较为简短的字幕嵌入视频内,确保字幕和配音精确对齐
CUDA 加速
为加快任务速度,在Windows和Linux上,如果有英伟达显卡,可配置安装CUDA和cuDNN环境后,启用CUDA加速,将能明显提高执行速度。
手动下载模型
默认在第一次使用某个模型时,将自动在线下载。原始模型均在国外 huggingface.co 或国内镜像 hf-mirror.com,因模型较大以及网络问题,可能会遇到下载失败或下载模型不完整的问题,可参考以下方法手动下载。
手动下载通用步骤
- 在
sp.exe(或sp.py)同目录下的models文件夹内,创建对应的模型文件夹(文件夹名称见下表) - 打开对应的 HuggingFace 下载地址
- 将该页面的所有
.json、.bin、.txt文件下载后复制到上面创建的文件夹内即可,若已存在可直接覆盖
模型下载地址
| 模型名称 | 文件夹名称 | HuggingFace 下载地址 |
|---|---|---|
| tiny | models--Systran--faster-whisper-tiny | https://huggingface.co/Systran/faster-whisper-tiny/tree/main |
| base | models--Systran--faster-whisper-base | https://huggingface.co/Systran/faster-whisper-base/tree/main |
| small | models--Systran--faster-whisper-small | https://huggingface.co/Systran/faster-whisper-small/tree/main |
| medium | models--Systran--faster-whisper-medium | https://huggingface.co/Systran/faster-whisper-medium/tree/main |
| large-v1 | models--Systran--faster-whisper-large-v1 | https://huggingface.co/Systran/faster-whisper-large-v1/tree/main |
| large-v2 | models--Systran--faster-whisper-large-v2 | https://huggingface.co/Systran/faster-whisper-large-v2/tree/main |
| large-v3 | models--Systran--faster-whisper-large-v3 | https://huggingface.co/Systran/faster-whisper-large-v3/tree/main |
| large-v3-turbo | models--mobiuslabsgmbh--faster-whisper-large-v3-turbo | https://huggingface.co/mobiuslabsgmbh/faster-whisper-large-v3-turbo/tree/main |
仅英语模型下载地址
以下模型只可用于识别转录英语发音的音视频。
| 模型名称 | 文件夹名称 | HuggingFace 下载地址 |
|---|---|---|
| tiny.en | models--Systran--faster-whisper-tiny.en | https://huggingface.co/Systran/faster-whisper-tiny.en/tree/main |
| base.en | models--Systran--faster-whisper-base.en | https://huggingface.co/Systran/faster-whisper-base.en/tree/main |
| small.en | models--Systran--faster-whisper-small.en | https://huggingface.co/Systran/faster-whisper-small.en/tree/main |
| medium.en | models--Systran--faster-whisper-medium.en | https://huggingface.co/Systran/faster-whisper-medium.en/tree/main |
蒸馏模型下载地址(仅英语)
以下蒸馏模型只可用于识别转录英语发音的音视频。
| 模型名称 | 文件夹名称 | HuggingFace 下载地址 |
|---|---|---|
| distil-large-v2 | models--Systran--faster-distil-whisper-large-v2 | https://huggingface.co/Systran/faster-distil-whisper-large-v2/tree/main |
| distil-large-v3 | models--Systran--faster-distil-whisper-large-v3 | https://huggingface.co/Systran/faster-distil-whisper-large-v3/tree/main |
| distil-large-v3.5 | models--distil-whisper--distil-large-v3.5-ct2 | https://huggingface.co/distil-whisper/distil-large-v3.5-ct2/tree/main |
| distil-small.en | models--Systran--faster-distil-whisper-small.en | https://huggingface.co/Systran/faster-distil-whisper-small.en/tree/main |
| distil-medium.en | models--Systran--faster-distil-whisper-medium.en | https://huggingface.co/Systran/faster-distil-whisper-medium.en/tree/main |
国内镜像下载
如果 HuggingFace 下载速度慢或无法访问,可使用国内镜像。将下载地址中的 huggingface.co 替换为 hf-mirror.com 即可,例如:
- 原始地址:
https://huggingface.co/Systran/faster-whisper-large-v3/tree/main - 镜像地址:
https://hf-mirror.com/Systran/faster-whisper-large-v3/tree/main
常见问题与错误
下载模型失败或卡住
原因: 网络不稳定或无法访问 HuggingFace。
解决方案:
- 使用国内镜像下载(将
huggingface.co替换为hf-mirror.com) - 手动下载模型文件,参照上方"手动下载模型"章节
- 检查网络代理设置是否正确
识别结果空白或乱码
原因: 模型文件下载不完整或损坏。
解决方案:
- 删除
models文件夹中对应的模型文件夹,重新下载 - 确认文件夹内的
.json、.bin、.txt文件完整无缺
识别速度非常慢
原因: 未启用 CUDA 加速,或使用了过大的模型。
解决方案:
- 确认已安装 CUDA 和 cuDNN,并在软件中启用
CUDA加速 - 若无 NVIDIA 显卡,可尝试使用较小的模型(如
base或small) - 确认显卡显存满足模型要求
内存不足(OOM)
原因: 模型太大,内存或显存不够。
解决方案:
- 使用较小的模型(如
large-v3-turbo替代large-v3) - 关闭其他占用内存的程序
- 确保内存不低于 16G(使用 large 系列模型时)
识别的语言不正确
原因: 未正确指定发音语言。
解决方案:
- 在软件中明确指定发音语言,确保与视频中语音所用语言一致
- 如果视频包含多种语言,尝试分段处理