语音识别中的 VAD 参数调整
在视频翻译的语音识别阶段,生成的字幕有时可能过长(几十秒甚至几分钟),有时又过短(不到 1 秒)。通过调整 VAD(语音活动检测)参数,可以优化这些问题,使字幕更符合实际语音内容。
什么是 VAD?
VAD(Voice Activity Detection,语音活动检测)是一个用于识别音频中语音部分的工具,它可以将语音与静音或噪音分离。与 Whisper 等语音识别工具结合使用时,VAD 能在识别前后检测和分割语音片段,从而提升识别效果。
当前版本默认使用 silero 作为 VAD 模型。你可以在「菜单 → 工具 → 高级选项」中切换为 ten-vad。
参数详解及调整建议
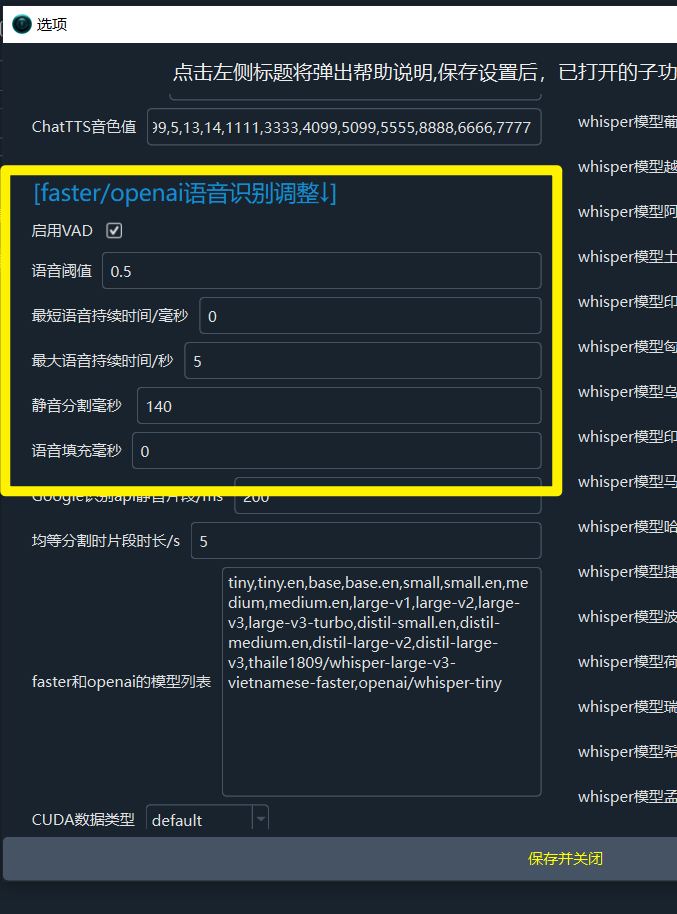
核心参数
| 参数 | 说明 | 默认值 | 调整建议 |
|---|---|---|---|
| 选择 VAD | 选择要使用的 VAD 模型 | silero | 一般保持默认即可 |
| 语音阈值 | 音频片段被认为是语音的最低概率,越小越灵敏 | 0.5 | 降低可提高灵敏度,但可能误将噪声视为语音 |
| 最长语音持续秒数 | 超过此时长强制分割 | 5 | 需要短字幕可设为 3-4,需要长字幕可设为 8-10 |
| 最短语音持续毫秒 | 小于此值尝试合并到相邻字幕 | 2000 | 需要短字幕可设为 1000-1500 |
| 合并过短字幕到邻近 | 选中后才会合并短字幕 | 否 | 一般建议选中 |
| 静音分割持续毫秒 | 只在大于此值的静音处分割 | 140 | 增大可减少分割次数 |
| 非语音阈值 | 减小可降低幻觉但可能遗漏文字 | — | 一般保持默认 |
高级参数
| 参数 | 说明 | 默认值 |
|---|---|---|
| 采样温度 | 控制识别的随机性 | — |
| 热词 | 告诉模型哪些词可能出现,以英文逗号分隔 | 空 |
| 重复惩罚 | 增大该值有利于减少重复 | — |
| 文本压缩率 | 减小该值有利于减少重复 | — |
| Whisper 预分割音频 | 是否提前将音频切割为句子片段后再发给 Whisper 模型识别 | 否 |
💡 使用 clone 配音角色时:请选中「Whisper 预分割音频」,并将最短语音设为 3000,最大语音设为 10,以确保参考音频时长在 3-10 秒之间,提高克隆可靠性。
常见问题
Q: 字幕太长(几十秒),如何缩短?
- 减小「最长语音持续秒数」(如设为 3-4)
- 选中「合并过短字幕到邻近」
- 减小「静音分割持续毫秒」
Q: 字幕太短(不到 1 秒),如何加长?
- 增大「最长语音持续秒数」(如设为 8-10)
- 增大「最短语音持续毫秒」(如设为 3000-4000)
- 取消「合并过短字幕到邻近」
Q: 字幕中有重复内容怎么办?
- 增大「重复惩罚」值
- 减小「文本压缩率」
- 增大「采样温度」(但过高可能导致幻觉)
Q: 如何让模型识别特定的专有名词?
在「热词」栏中填写专有名词,以英文逗号分隔。例如:北京,清华大学,ChatGPT
相关文档
- 提高 AI 翻译字幕的质量 — 翻译模式对比与术语表使用
- 更好的使用本地大模型作为翻译渠道 — 本地大模型配置指南
- 修改 AI 翻译提示词 — 自定义翻译提示词
- 视频翻译最佳效果推荐 — 每个阶段的最优配置
- 翻译后出现"空白字幕行"的原因与解决方法