pyVideoTrans WebUI 使用指南
⚠️ 重要提示
WebUI 版本仅实现了部分功能,主要用于以下场景:
- 云服务器部署(远程访问翻译服务)
- 局域网内部署(服务器与使用机分离)
- Docker 容器化部署
如需完整功能,请使用桌面客户端(
sp.exe)或源码运行(sp.py)。 桌面版支持更多 API 渠道配置、实时交互编辑、批量处理等高级功能。
一、部署方式
1.1 源码部署(推荐)
git clone https://github.com/jianchang512/pyvideotrans.git
cd pyvideotrans
uv sync --extra webui启动服务:
uv run webui.py # 默认 0.0.0.0:7860
uv run webui.py --port 8080 # 指定端口
uv run webui.py --host 127.0.0.1 # 仅本机访问
uv run webui.py --share # 创建 Gradio 公网链接访问:http://127.0.0.1:7860 或 http://<服务器IP>:7860
1.2 Docker 部署
# 构建镜像
git clone https://github.com/jianchang512/pyvideotrans.git
cd pyvideotrans
docker build -t pyvideotrans-webui .
# 运行
docker run -d -p 7860:7860 --name pyvideotrans pyvideotrans-webui
# 持久化配置和输出
docker run -d -p 7860:7860 \
-v ./data/output:/app/output \
-v ./data/config:/app/videotrans \
--name pyvideotrans pyvideotrans-webui
# GPU 加速
docker run -d -p 7860:7860 --gpus all \
-v ./data/output:/app/output \
-v ./data/config:/app/videotrans \
--name pyvideotrans pyvideotrans-webui1.3 Google Colab
- 打开 https://colab.research.google.com/drive/1kPTeAMz3LnWRnGmabcz4AWW42hiehmfm?usp=sharing
- 登录 Google 账号 → 点击 全部运行
- 等待
*.gradio.live链接出现,点击使用
⚠️ Colab 免费版有 4-6 小时使用时长限制。
1.4 Huggingface.co
- 打开 https://huggingface.co/spaces/mortimerme/pyvideotrans
- 点击右上角三个点符号,选择
Clone repository - 克隆仓库到自己账号下运行
使用2核CPU运行免费,GPU资源需在 huggingface.co 购买
二、界面说明
WebUI 分为三个标签页:
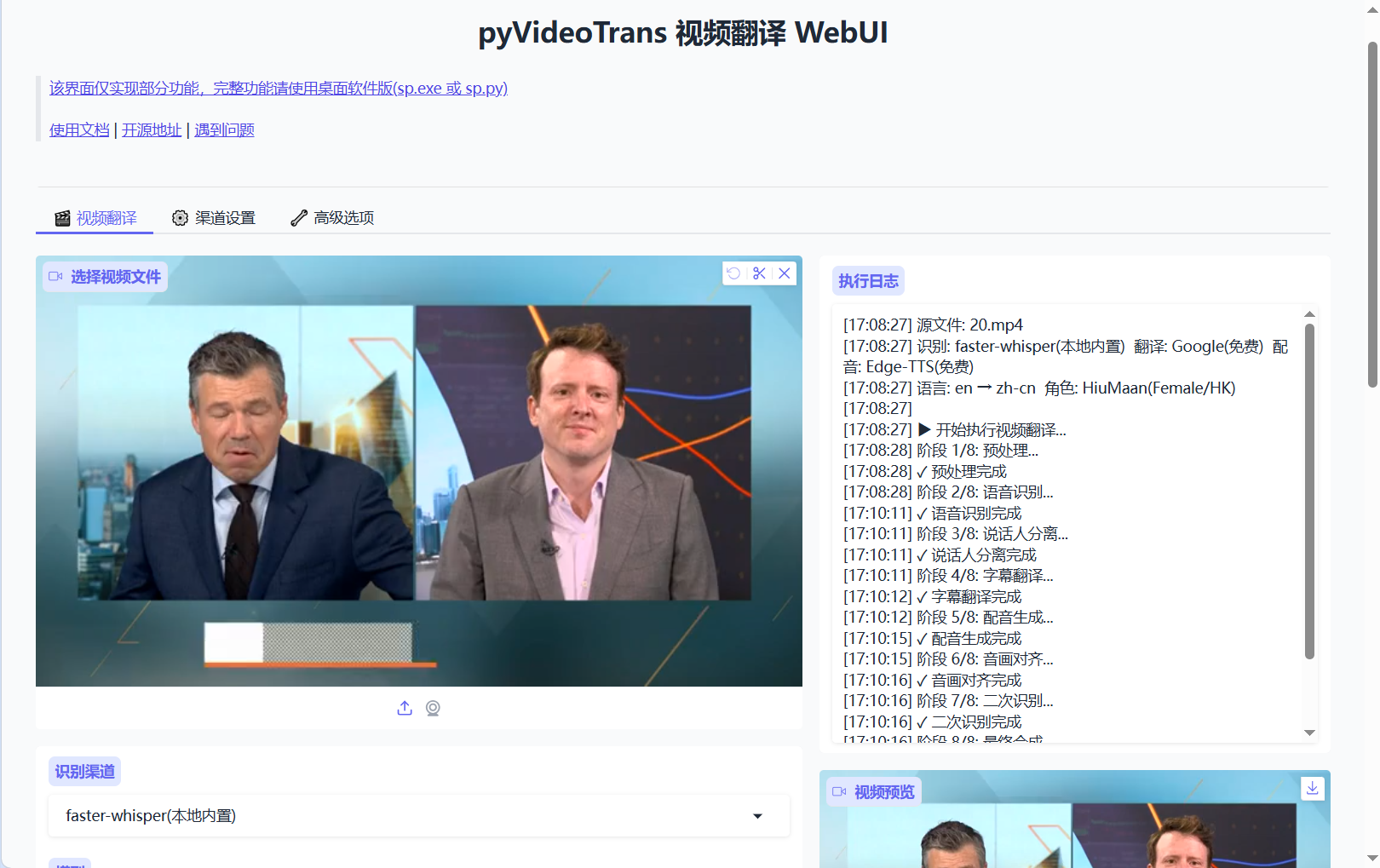
2.1 🎬 视频翻译(主界面)
文件选择:支持 mp4/mkv/avi/mov/webm/wav/mp3/m4a/flac 等格式
语音识别:可选 faster-whisper/openai-whisper/Qwen-ASR/FunASR/Huggingface_ASR(均为本地内置免费渠道)
字幕翻译:可选 Google/Microsoft/M2M100(免费渠道)
字幕配音:可选 Edge-TTS/Qwen3-TTS/MOSS-TTS/Piper/VITS/Supertonic/ChatterBox/gTTS(免费/本地内置渠道)
对齐与字幕:配音加速、视频慢速、语速/音量/音调调节、字幕嵌入类型
更多设置:降噪、标点处理、人声分离、背景声嵌入、CUDA 加速
硬字幕样式编辑:字体、颜色、描边、阴影、对齐等全面自定义
2.2 ⚙️ 渠道设置
配置各渠道的 API 地址、SK 密钥、模型等。与桌面版通用,配置保存在 videotrans/params.json 中。
包含:翻译渠道、语音识别渠道、配音渠道、参考音频设置
使用 API 渠道前,需先用桌面版(sp.exe)配置好 API 地址和 SK 密钥。
2.3 🔧 高级选项
配置全局高级参数,与桌面版 菜单 → 工具 → 高级选项 完全通用。
包含:通用设置、视频输出控制、语音识别参数、字幕翻译调整、字幕配音调整、字幕声音画面对齐、Whisper模型提示词
三、执行翻译
- 选择视频/音频文件
- 配置识别/翻译/配音参数
- 点击「🚀 开始执行」
执行过程:
- 按钮变为「⏳ 执行中...」并禁用
- 右侧日志实时显示 8 个阶段进度
- 完成后按钮恢复,视频预览区可在线播放,文件区可下载
四、与桌面版对比
| 功能 | WebUI | 桌面版 |
|---|---|---|
| 视频翻译完整流程 | ✅ | ✅ |
| API 渠道(需先用桌面版配置) | ✅ | ✅ |
| 高级选项配置 | ✅ | ✅ |
| 实时交互编辑字幕 | ❌ | ✅ |
| 批量处理 | ❌ | ✅ |
| 视频预览播放 | ✅ | ❌ |
| 远程访问 / Docker | ✅ | ❌ |
五、常见问题
Q: 启动报错 No module named gradiouv sync --extra webui
Q: Docker 如何持久化配置-v ./data/output:/app/output -v ./data/config:/app/videotrans
Q: Docker 如何使用 GPU 安装 nvidia-container-toolkit 后:docker run --gpus all ...
Q: 如何使用 API 渠道 先用桌面版配置好 API 地址和 SK,WebUI 自动读取 params.json
Q: 如何创建公网链接uv run webui.py --share,控制台输出临时 *.gradio.live 链接