本地视频硬字幕提取工具使用说明
在视频处理中,通过声音识别并自动生成字幕(如使用 Whisper 模型)目前已经非常方便。但如果视频中已经“烧录”了画面字幕(即硬字幕),想要将它们提取出来却并不容易:使用在线 OCR 接口容易遇到调用频率限制或报错,而付费服务的成本又比较高。
为了解决这个问题,本工具整合了两个优秀的开源项目,实现了一款全本地、完全离线的视频硬字幕提取工具。它可以直接识别视频画面中的文字,并自动生成 .srt 格式的字幕文件。目前支持 中、英、日、韩 4 种语言。
下载地址: https://pan.baidu.com/s/1FrBVmdXAQBtnTelONv8Wog?pwd=1234
必须解压在英文文件夹内,中文目录下可能出错
核心原理解析:
- VideoSubFinder:负责快速定位视频中出现硬字幕的画面并进行截图。
- PaddleOCR-json(基于百度 PaddleOCR):负责识别这些截图中的文字,并将其转化为文本。
主要功能
- 可视化区域选择:导入视频后,可以在预览画面中直接用鼠标框选字幕所在的区域,避免画面中其他文字(如台标、水印)的干扰。
- 支持 CUDA 显卡加速:提升文字识别的运行效率。
- 多语言识别:支持中文、英文、日文、韩文 4 种语言的硬字幕提取。
- 运行环境:目前仅支持 Windows 10 和 Windows 11 系统。
使用方法
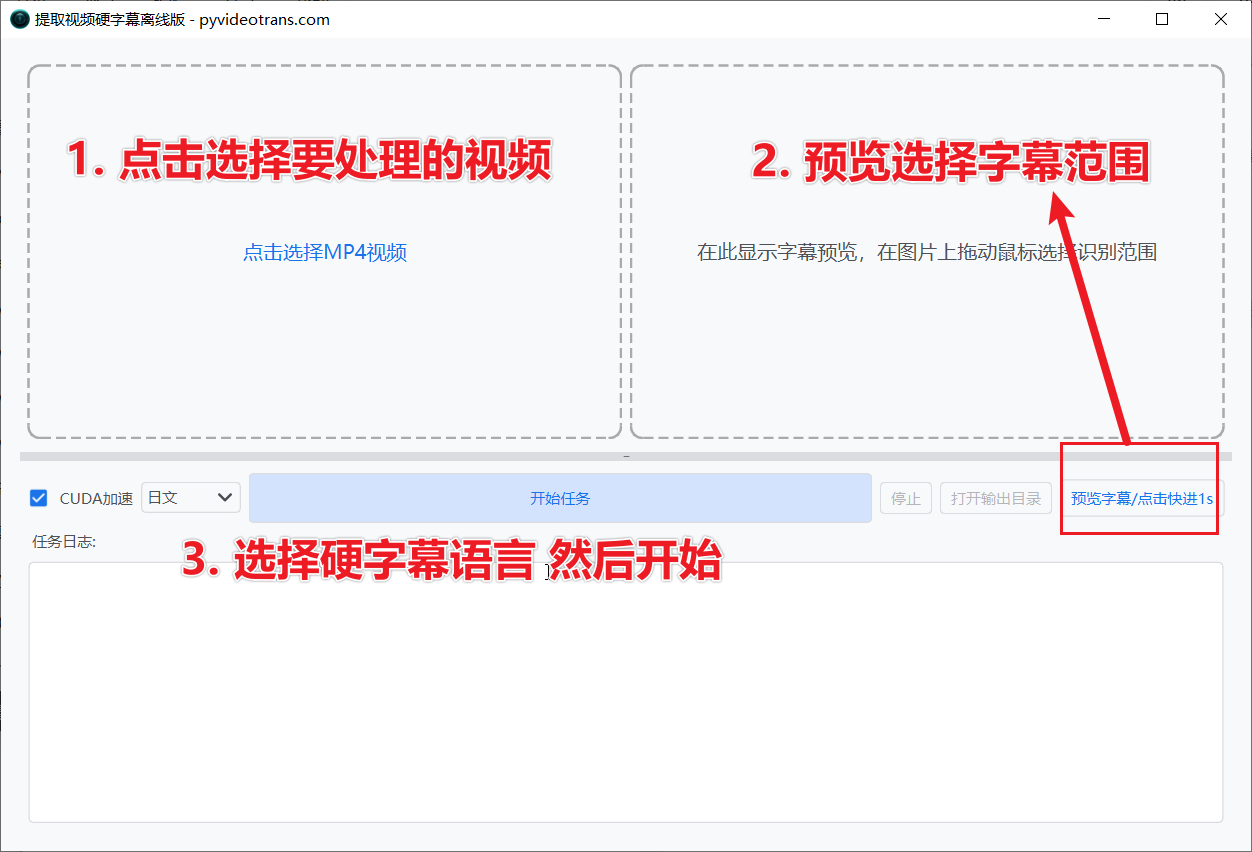
第一步:启动软件
下载并解压软件包,在解压后的文件夹中双击运行 ocrsp.exe。 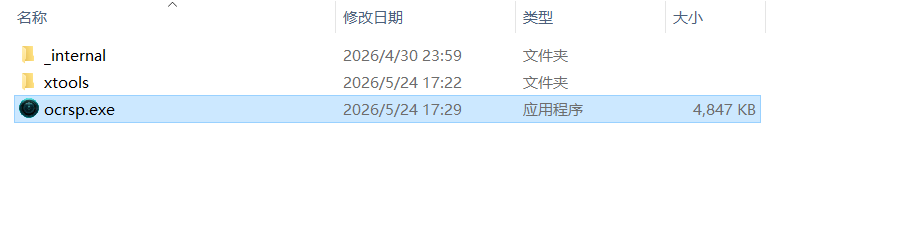
第二步:导入视频
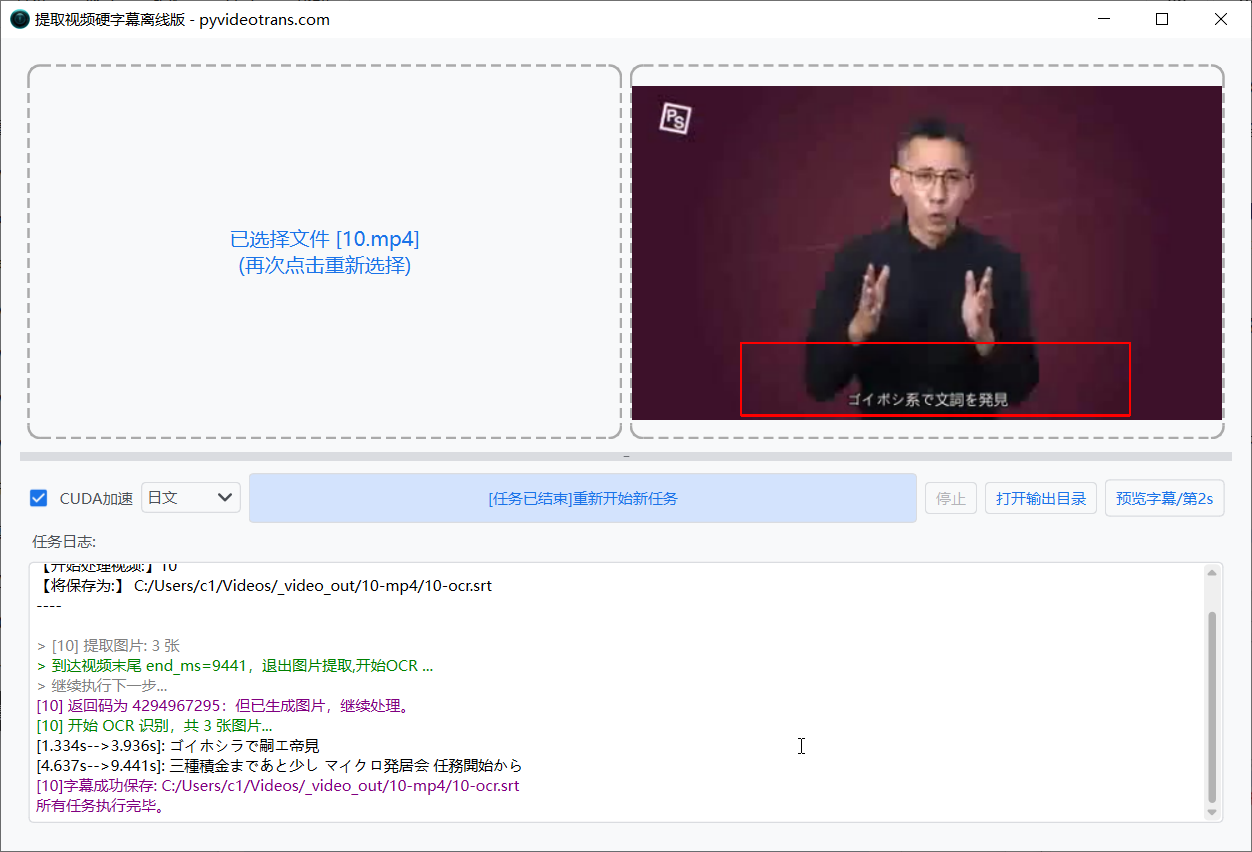
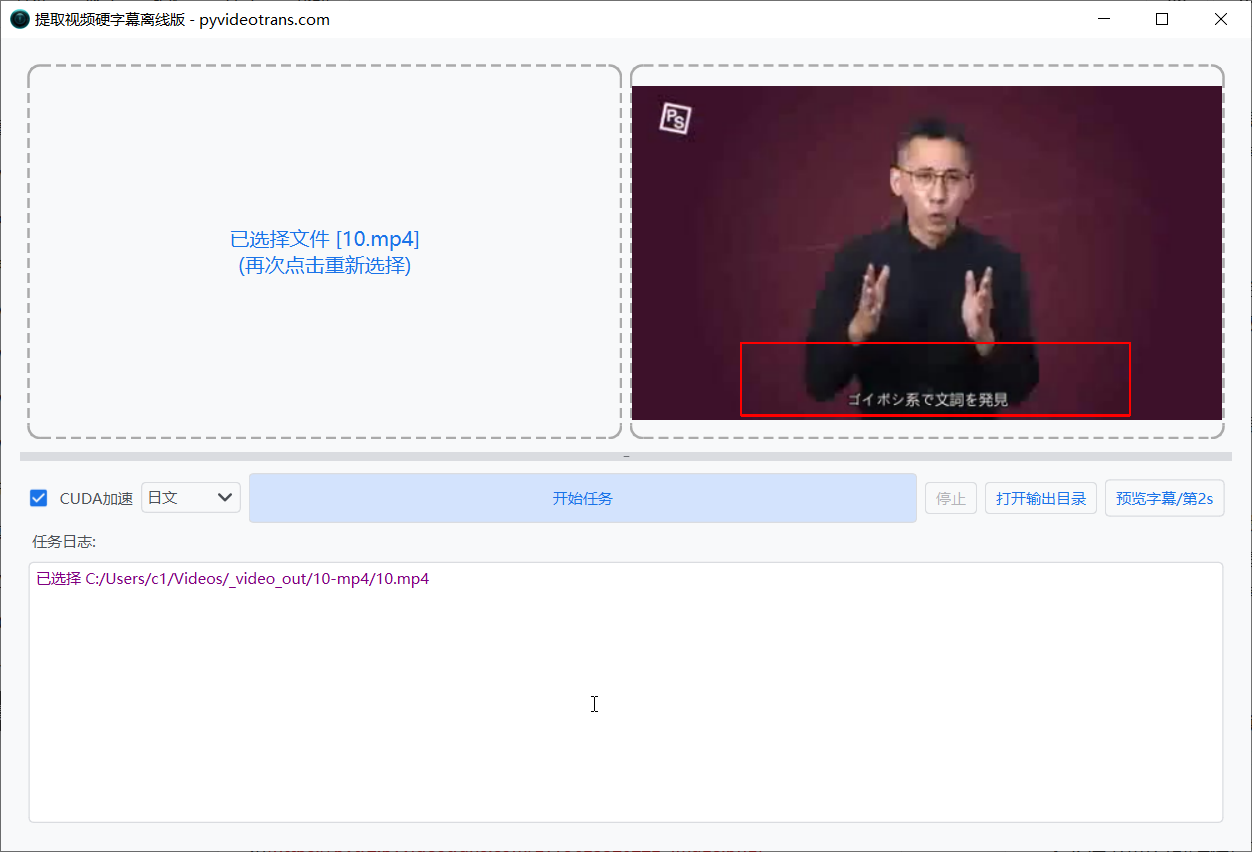
在软件界面左侧,点击选择需要处理的视频文件(请确保该视频中含有需要提取的硬字幕)。
第三步:框选字幕区域
- 在右侧的视频预览区域,按住鼠标左键并拖动,框选出字幕所在的范围。
- 为了确保框选区域准确,可以点击预览窗口下方的“步进”按钮微调视频画面。切换到其他时间点,确认字幕在不同位置都能被完整包含在框内。
第四步:开始提取
确认无误后,点击“开始”按钮。软件底部的日志窗口会实时显示处理进度,静待运行完成即可。
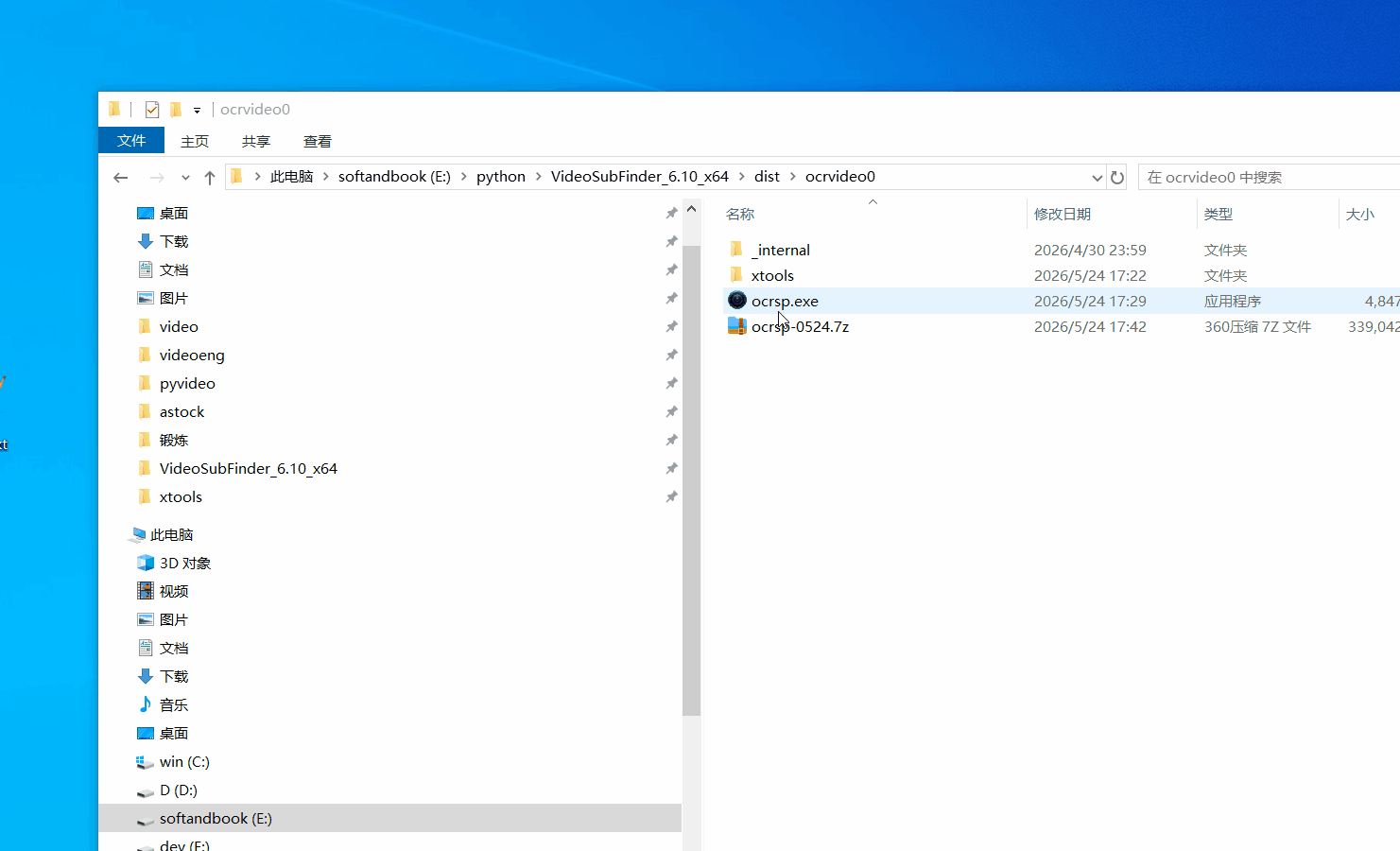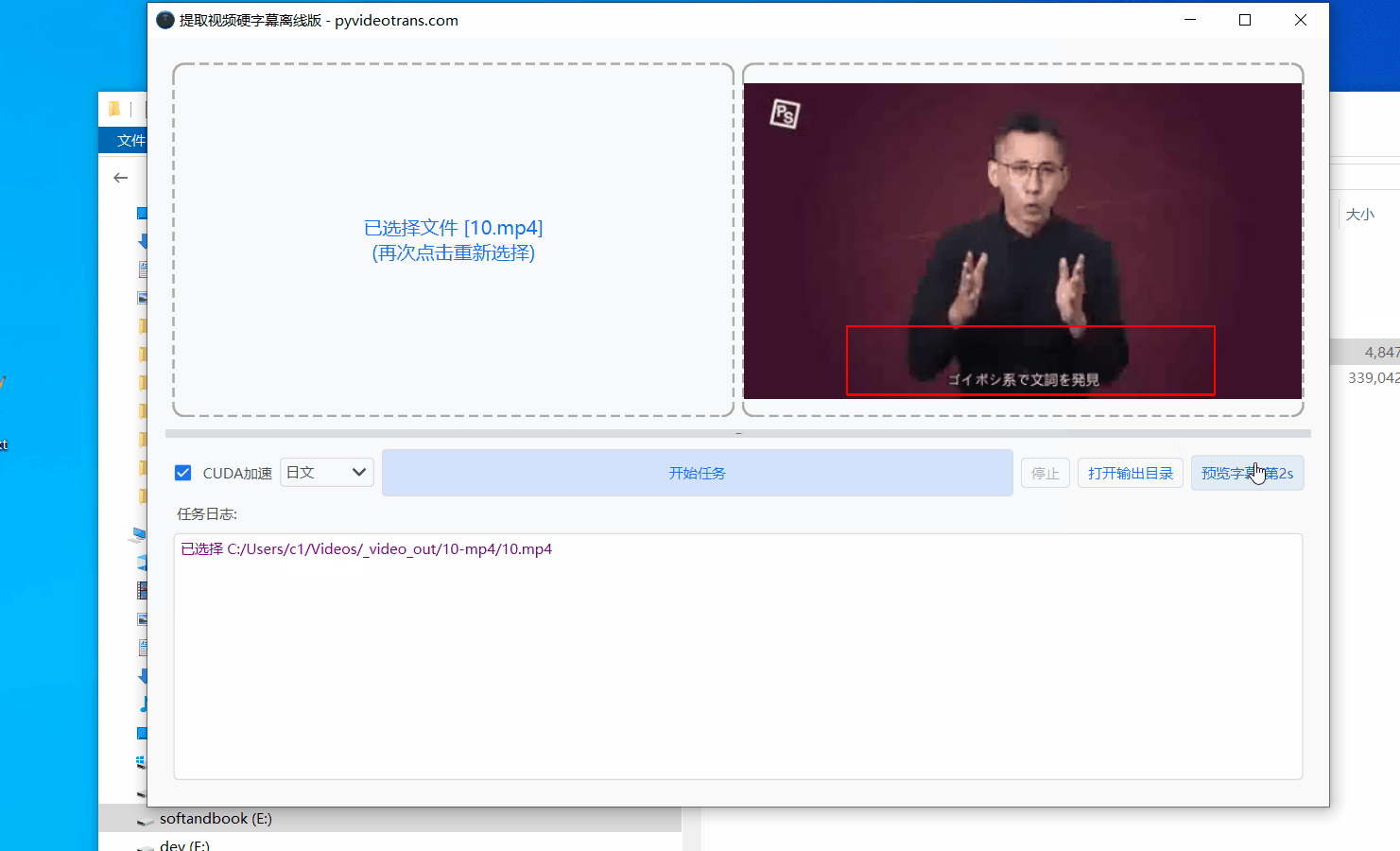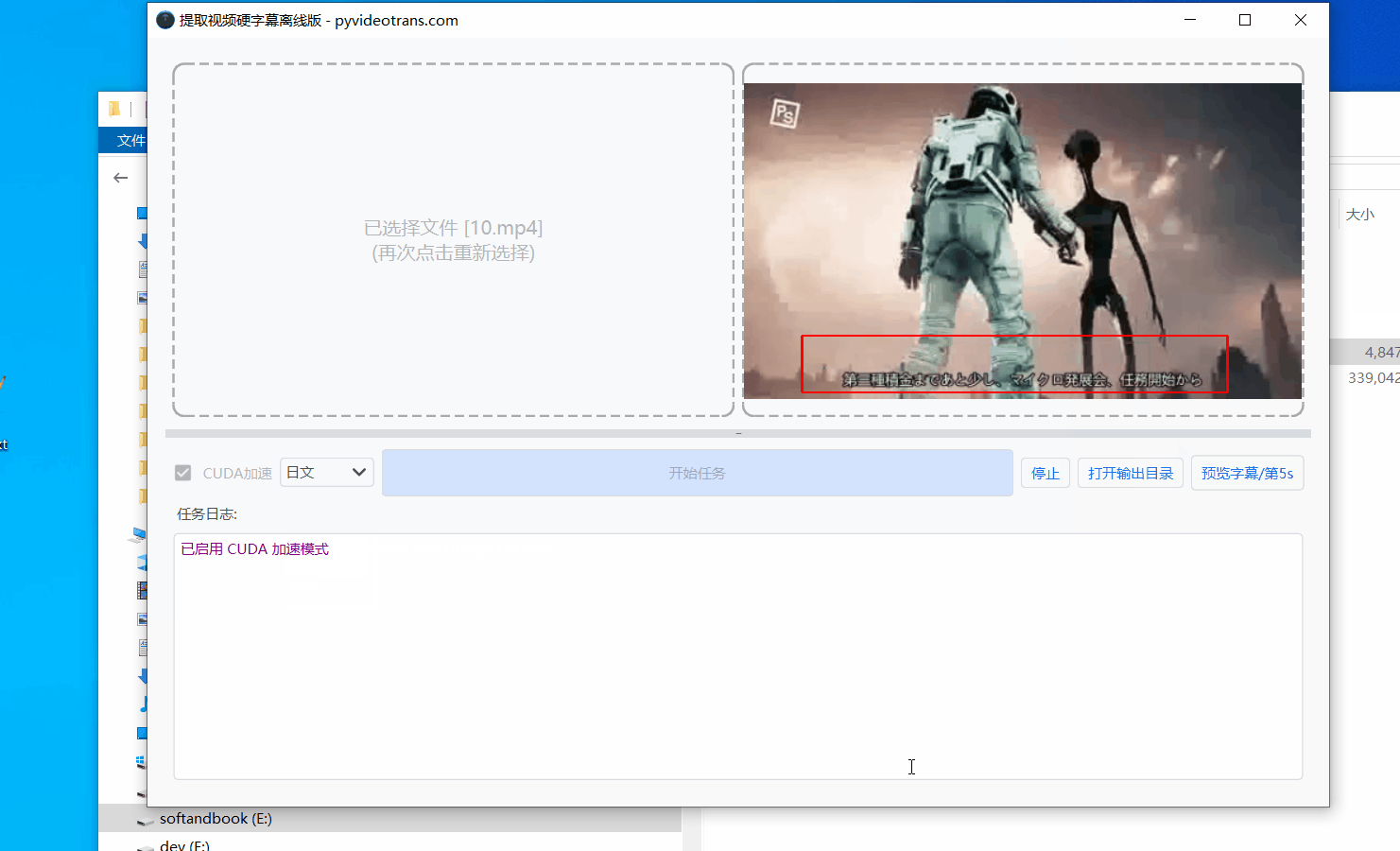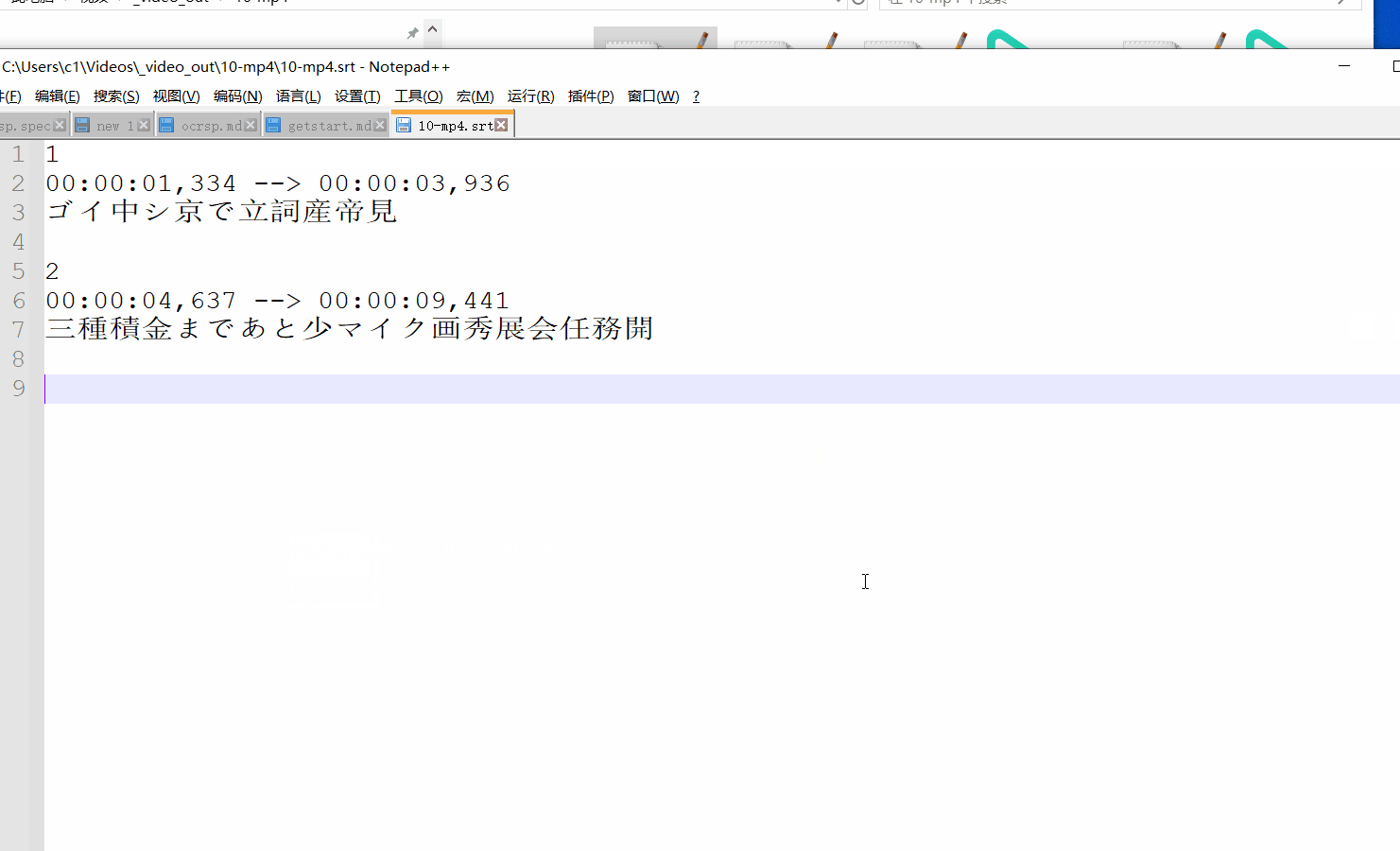
第五步:获取字幕
提取完成后,生成的字幕文件会以 [原视频名称]-ocr.srt 的命名方式,自动保存在该视频所在的文件夹下。
硬字幕抹除工具
- 另一个硬字幕提取工具 video-subtitle-extractor*
- 如需抹除删除硬字幕,推荐使用github开源项目video-subtitle-remover
致谢
本工具的实现离不开以下开源项目的支持,特此鸣谢: