Parakeet-API: 高性能本地语音转录服务
这是什么
parakeet-api 是一个基于 NVIDIA Parakeet-tdt-0.6b 模型的本地语音转录服务。它的核心特点:
- 提供与 OpenAI API 兼容的接口,可直接对接 pyVideoTrans
- 内置简洁的 Web 用户界面,浏览器打开即可使用
- 转录结果为标准 SRT 字幕格式
- 完全本地运行,无需联网,无需付费,无隐私顾虑
- 适配
pyVideoTrans v3.72+
适用场景
- 需要离线进行语音识别的用户
- 对识别速度和准确率有较高要求的用户
- 不想依赖云端 API、注重数据隐私的用户
- 拥有 NVIDIA 显卡(GPU 加速效果显著)
前置条件
| 条件 | 说明 |
|---|---|
| NVIDIA 显卡(推荐) | 支持 CUDA 的显卡可大幅提升速度;无显卡也可用 CPU 模式(较慢) |
| FFmpeg | 用于音视频格式预处理 |
| Python 3.10 | 源码部署时需要 |
| pyVideoTrans v3.72+ | 使用本渠道的翻译工具版本要求 |
快速开始:下载整合包(推荐新手)
整合包无需安装 Python 和依赖,解压即用:
下载地址1(百度网盘): 从百度网盘下载
下载地址2(HuggingFace): 从HuggingFace.co下载
操作步骤
- 下载压缩包并解压到任意文件夹(路径中不要包含中文或空格)
- 双击
启动.bat文件 - 等待命令行窗口出现启动成功提示,浏览器会自动打开
启动成功界面:
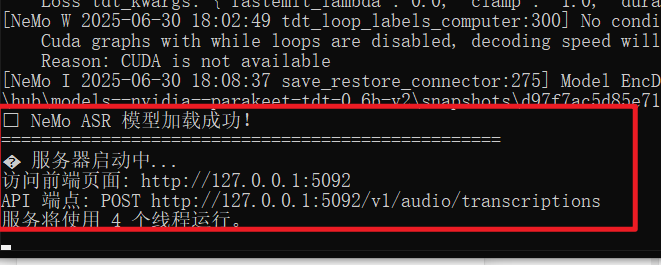
看到上图所示界面即表示启动成功。此时可以在浏览器中直接使用,也可以在 pyVideoTrans 中对接使用。
在 pyVideoTrans 中使用
Parakeet-API 可与视频翻译工具 pyVideoTrans (v3.72及以上版本) 无缝集成。
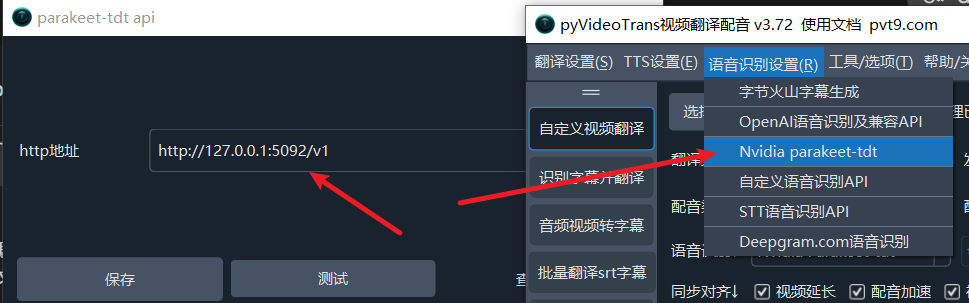
配置步骤
- 确保
parakeet-api服务正在本地运行(命令行窗口不要关闭) - 打开
pyVideoTrans软件 - 在菜单栏中,选择 语音识别(R) → Nvidia parakeet-tdt
- 在弹出的配置窗口中,将 "http地址" 设置为:
http://127.0.0.1:5092/v1 - 点击 "保存",即可开始使用
参数说明
| 参数 | 值 | 说明 |
|---|---|---|
| http地址 | http://127.0.0.1:5092/v1 | parakeet-api 的 API 端点地址 |
| api_key | 123456(任意值) | 程序内部固定使用,无需修改 |
常见连接错误
如果启动 pyVideoTrans 后提示连接失败,请检查:
- parakeet-api 是否已启动 —— 命令行窗口是否还在运行
- 端口是否正确 —— 默认端口为
5092,确认没有被其他程序占用 - 地址格式 —— 必须以
/v1结尾,即http://127.0.0.1:5092/v1 - 防火墙 —— 检查本地防火墙是否阻止了 5092 端口
源码部署方式
如果你想从源码部署,或者需要自定义配置,请按以下步骤操作。
安装与配置指南
本项目支持 Windows、macOS 和 Linux。请按照以下步骤进行安装和配置。
步骤 0:配置 Python 3.10 环境
如果你本机没有 Python 3,请照此教程安装: https://pvt9.com/_posts/pythoninstall
请确保安装的是 Python 3.10 版本,其他版本可能存在兼容性问题。
步骤 1:准备 FFmpeg
本项目使用 ffmpeg 进行音视频格式预处理。
Windows(推荐):
- 从 FFmpeg github 仓库下载 解压后得到
ffmpeg.exe - 将
ffmpeg.exe直接放置在本项目根目录(与app.py文件在同一级),程序会自动检测并使用它,无需配置环境变量
- 从 FFmpeg github 仓库下载 解压后得到
macOS(使用 Homebrew):
bashbrew install ffmpegLinux(Debian/Ubuntu):
bashsudo apt update && sudo apt install ffmpeg
步骤 2:创建 Python 虚拟环境并安装依赖
下载或克隆本项目代码到本地计算机(建议放在非系统盘的英文或数字文件夹内)
打开终端或命令行工具,进入项目根目录(Windows 上直接在文件夹地址栏里输入
cmd回车即可)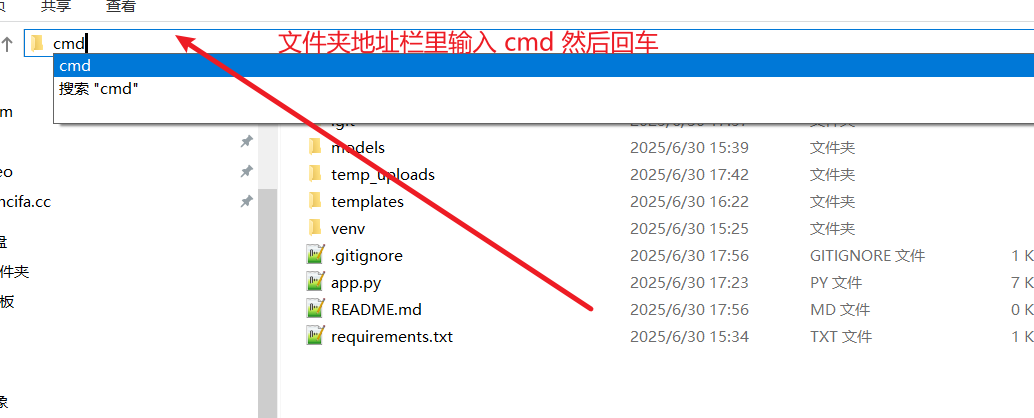
创建虚拟环境:
bashpython -m venv venv激活虚拟环境:
- Windows(CMD/PowerShell):
.\venv\Scripts\activate - macOS / Linux(Bash/Zsh):
source venv/bin/activate
- Windows(CMD/PowerShell):
安装依赖库:
如果您没有 NVIDIA 显卡(仅使用 CPU):
bashpip install -r requirements.txt如果您有 NVIDIA 显卡(使用 GPU 加速): a. 确保已安装最新的 NVIDIA 驱动 和相应的 CUDA Toolkit b. 卸载可能存在的旧版 PyTorch:
pip uninstall -y torchc. 安装与您的 CUDA 版本匹配的 PyTorch(以 CUDA 12.6 为例):bashpip install torch --index-url https://download.pytorch.org/whl/cu126
步骤 3:启动服务
在已激活虚拟环境的终端中,运行以下命令:
python app.py首次运行会自动下载模型(约 1.2GB),请耐心等待,下载完成后会自动启动。
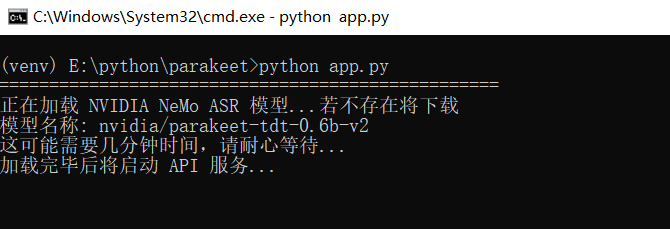
如果出现一堆提示信息,无需介意,等待即可:
启动成功界面:
看到上图界面即表示服务启动成功。
使用方法
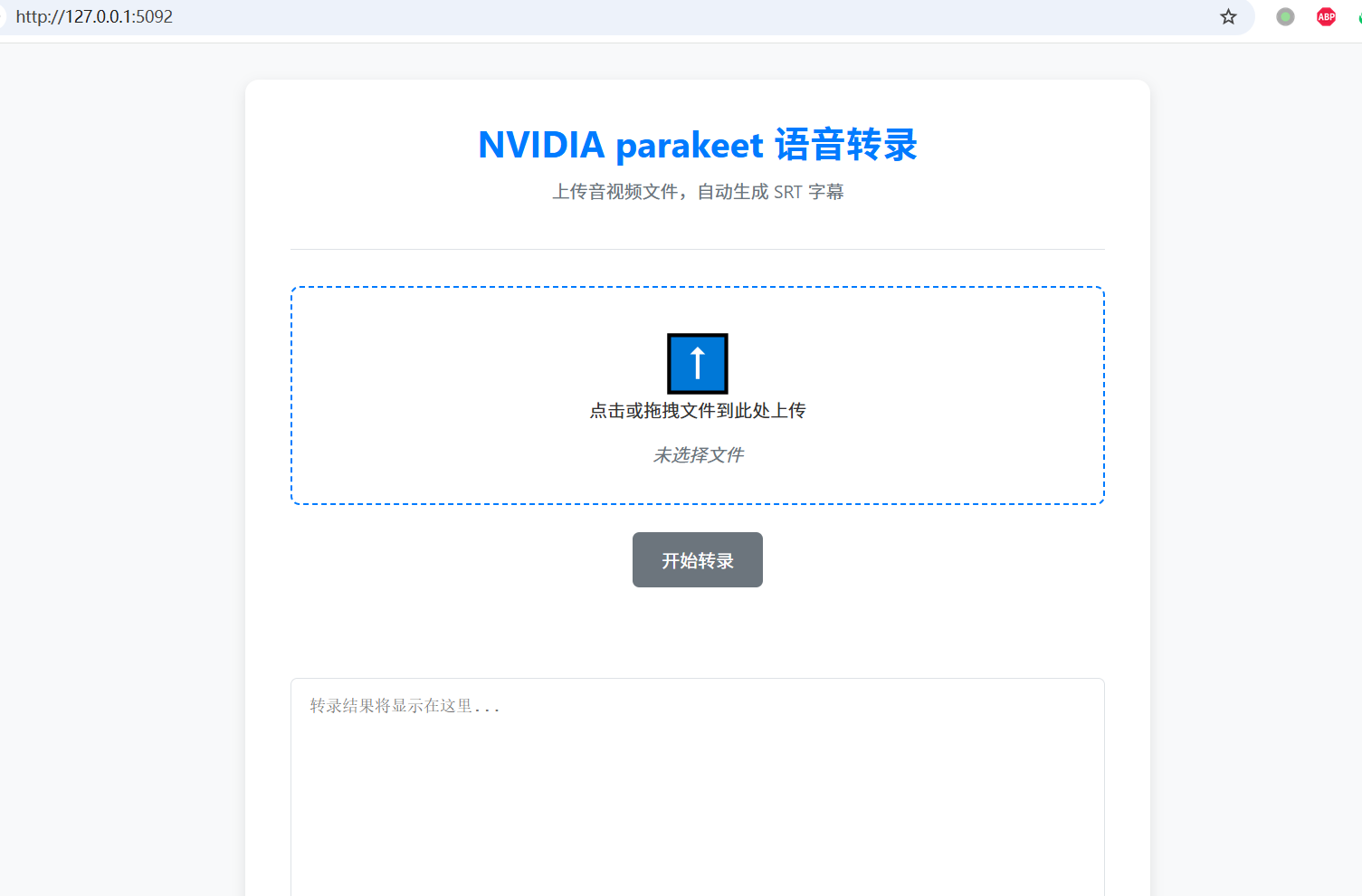
方法 1:使用 Web 界面
- 在浏览器中打开:http://127.0.0.1:5092
- 拖拽或点击上传您的音视频文件
- 点击 "开始转录",等待处理完成即可在下方看到并下载 SRT 字幕
方法 2:API 调用(Python 示例)
使用 openai 库可以轻松调用本服务:
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:5092/v1",
api_key="any-key",
)
with open("your_audio.mp3", "rb") as audio_file:
srt_result = client.audio.transcriptions.create(
model="parakeet",
file=audio_file,
response_format="srt"
)
print(srt_result)最佳配置建议
| 配置项 | 推荐值 | 说明 |
|---|---|---|
| 模型 | parakeet_srt_words | 默认模型,识别精度高 |
| 计算设备 | GPU(CUDA) | 有 NVIDIA 显卡时强烈推荐,速度提升数十倍 |
| 音频格式 | WAV 16kHz 单声道 | 最佳识别效果,其他格式程序会自动转换 |
| 初始提示词 | 根据内容填写 | 可提高特定领域术语的识别准确率 |
常见问题
Q:启动时报错 "CUDA out of memory"?
A:显存不足。尝试以下方法:
- 关闭其他占用显存的程序
- 使用较小的模型
- 切换为 CPU 模式运行
Q:转录结果时间轴错乱?
A:检查输入音频是否有问题。建议先用 FFmpeg 将音频转换为标准 WAV 格式(16kHz、单声道)再进行转录。
Q:整合包启动后浏览器没有自动打开?
A:手动在浏览器中访问 http://127.0.0.1:5092 即可。如果无法访问,检查命令行窗口是否有报错信息。
Q:如何查看支持哪些语言?
A:Parakeet 模型主要支持英语识别。对于中文等其他语言,建议使用其他识别渠道(如 faster-whisper)。