什么是 FunASR 中文识别?
FunASR 是阿里巴巴达摩院开源的一套端到端语音识别模型,在中文语音识别场景下效果显著优于 whisper 系列模型。它基于 Sound-Stream 框架和大规模中文数据训练,对中文发音、方言口音、噪声环境等场景有很强的适应能力。
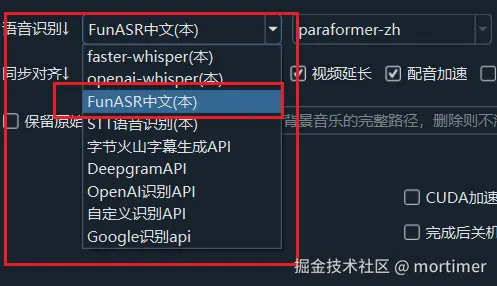
视频翻译软件中已集成 FunASR 作为 语音识别(ASR) 渠道之一,直接在软件中选择即可使用,无需额外部署外部服务。
前提条件
- 视频翻译软件版本 >= v2.97(早期版本需要手动部署
zh_recogn或SenseVoice服务) - 推荐使用 NVIDIA GPU:FunASR 模型在 CUDA 加速下运行速度最快;纯 CPU 也可运行但速度较慢
- 首次使用会自动从 modelscope.cn(国内模型托管平台)下载模型,需要网络连接
- 模型下载后会保存在软件目录下的
models/hub/文件夹中,后续使用无需重复下载
模型选择指南
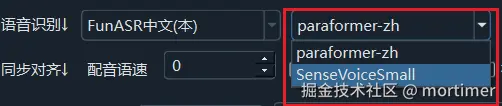
在语音识别中选择 FunASR中文识别 后,会出现多个模型选项:
| 模型名称 | 适用场景 | 说明 |
|---|---|---|
| paraformer-zh | 中文识别(推荐) | 效果和速度均为最佳,支持热词功能 |
| SenseVoiceSmall | 中文识别 | 轻量级模型,速度较快但精度略低于 paraformer |
| Fun-ASR-Nano-2512 | 中/英/日/粤语 | 适合混合语言或小语种场景 |
| Fun-ASR-MLT-Nano-2512 | 其他语言 | 适合英语、日语以外的其他语言 |
建议:如果你的视频主要是中文内容,优先选择 paraformer-zh,识别效果和速度都是最优的。
各模型详细说明
paraformer-zh(推荐)
这是 FunASR 中最经典的中文识别模型,基于 paraformer 架构,首次使用时会自动下载以下 4 个模型组件:
- ASR 模型:
speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404— 核心语音识别模型 - VAD 模型:
speech_fsmn_vad_zh-cn-16k-common— 语音端点检测,自动切分音频 - 标点模型:
punc_ct-transformer_zh-cn-common-vocab272727— 自动添加标点符号(所有模型都会下载此模型) - 说话人验证:
speech_campplus_sv_zh-cn_16k-common— 说话人特征提取
所有模型均来自 modelscope.cn,下载过程会显示进度,耐心等待即可。
SenseVoiceSmall
由阿里通义语音团队开发的轻量级多语言模型,首次使用时下载 iic/SenseVoiceSmall 模型。体积比 paraformer-zh 小,适合对速度要求较高但对精度要求不那么严格的场景。
Fun-ASR-Nano-2512
轻量级多语言模型,支持 中文、英文、日语、粤语 四种语言的识别。适合处理混合语言内容的视频。
Fun-ASR-MLT-Nano-2512
多语言扩展模型,支持除上述四种语言之外的 其他语言 识别。如果你的视频包含英语、日语以外的语言(如韩语、法语等),可以选择此模型。
使用步骤
第一步:选择识别渠道
在软件的 语音识别 设置中,选择 FunASR中文识别。
第二步:选择模型
根据你的视频语言选择合适的模型。中文视频选择 paraformer-zh。
第三步:等待模型下载(首次使用)
第一次使用某个模型时,软件会自动从 modelscope.cn 下载所需模型文件。下载过程会在软件界面显示进度。
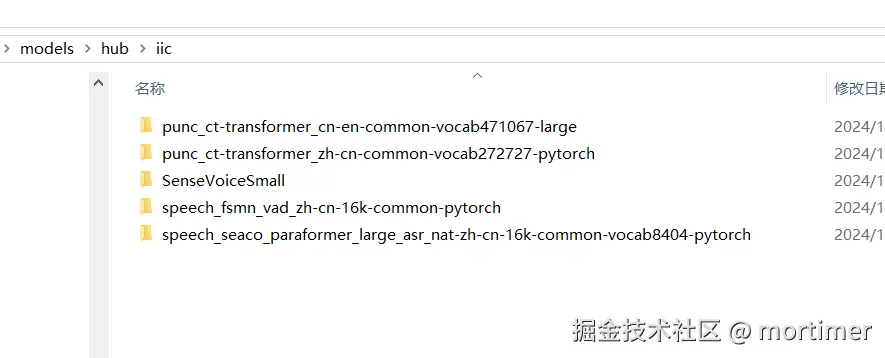
- 模型保存位置:软件目录下的
models/hub/文件夹 - 下载时间:根据网络速度,可能需要几分钟到几十分钟
- 下载完成后,后续使用无需重复下载
第四步:开始识别
模型下载完成后,直接点击开始,软件会自动进行语音识别。
配置建议(最佳实践)
- 使用 GPU 加速:确保系统已安装 CUDA,FunASR 会自动使用 GPU 加速,识别速度可提升数倍
- 选择正确的模型:
- 中文视频 → paraformer-zh(最佳效果)
- 中英混合 → paraformer-zh(已支持混合识别)
- 纯英文 → 建议使用 whisper 或 faster-whisper 系列
- 日语 → Fun-ASR-Nano-2512 或 Fun-ASR-MLT-Nano-2512
- 利用热词功能:paraformer-zh 支持热词设置,可以在软件中设置专业术语、人名等热词,提升识别准确率
- 首次使用预留时间:第一次使用某个模型需要下载,请确保网络畅通,耐心等待下载完成
常见错误与排查
下载失败或下载卡住
- 原因:网络连接 modelscope.cn 不稳定
- 解决:检查网络连接,尝试重启软件重新下载。如果持续失败,可以手动从 modelscope.cn 下载对应模型文件,放入
models/hub/目录
识别结果为空或乱码
- 原因:模型选择不匹配音频语言
- 解决:确认选择了与视频语言匹配的模型(中文视频选 paraformer-zh)
识别速度很慢
- 原因:使用 CPU 运行或未启用 GPU 加速
- 解决:检查是否安装了 CUDA 和对应版本的 PyTorch,确保 GPU 可用
提示模型文件缺失
- 原因:模型文件不完整或损坏
- 解决:删除
models/hub/下对应模型的文件夹,重新启动软件让其重新下载
标点符号缺失
- 注意:标点模型(
punc_ct-transformer_zh-cn-common-vocab272727)在选择任何 FunASR 模型时都会自动下载,如果标点效果不佳,请确认该模型已完整下载
所有模型下载地址
- https://modelscope.cn/models/iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/files
- https://modelscope.cn/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch/files
- https://modelscope.cn/models/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/files
- https://modelscope.cn/models/damo/speech_campplus_sv_zh-cn_16k-common/files
- https://modelscope.cn/models/FunAudioLLM/Fun-ASR-MLT-Nano-2512/files
- https://modelscope.cn/models/FunAudioLLM/Fun-ASR-Nano-2512/files
- https://modelscope.cn/models/iic/SenseVoiceSmall/files