整合包下载地址1: 从百度网盘下载
整合包下载地址2: 从HuggingFace.co下载
NVIDIA Parakeet 语音转录整合包使用说明
该整合包集成了NVIDIA开源的parakeet-ctc-1.1b(英文)和parakeet-tdt_ctc-0.6b-ja(日文)两个语音识别模型,用于将音视频文件转录为SRT格式的字幕。
目前,市面上可供选择的、效果较好的开源日语语音识别模型不多,NVIDIA的parakeet-tdt_ctc-0.6b-ja为日语内容的转录提供了一个可靠的选项。
此工具的特点是完全在用户本地计算机上运行,无需部署环境,下载解压双击可用。
工具功能
- 本地转录: 支持将英语和日语的音视频文件转录为文字。
- 生成SRT字幕: 转录结果可直接生成带时间戳的SRT字幕文件。
使用步骤
第一步:下载并启动程序
下载整合包并将其解压。在解压后的文件夹中,可以找到以下文件结构。
要运行程序,请双击名为 启动.bat 的文件。
第二步:等待模型下载
首次运行时,程序会自动下载所需的语音识别模型。此时会显示一个黑色命令行窗口,其中包含下载进度条。
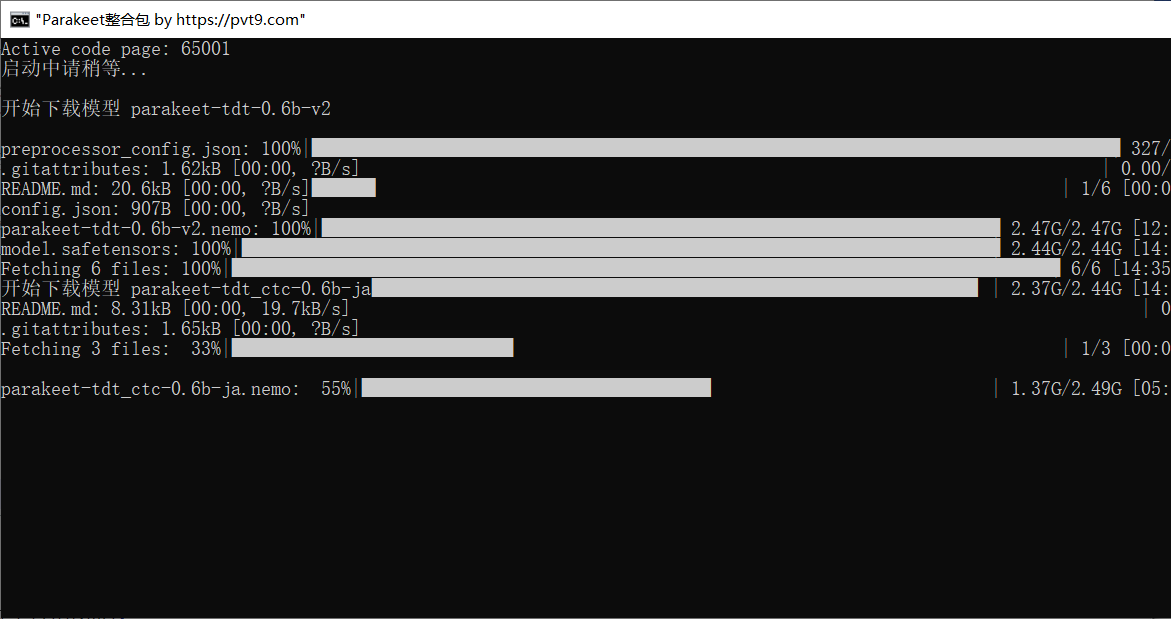
模型文件较大,下载过程需要连接互联网,并可能需要一些时间,具体时长取决于网络速度。下载完成后,程序会自动在默认浏览器中打开操作界面。
第三步:上传文件并执行转录
程序成功启动后,浏览器将显示以下界面。
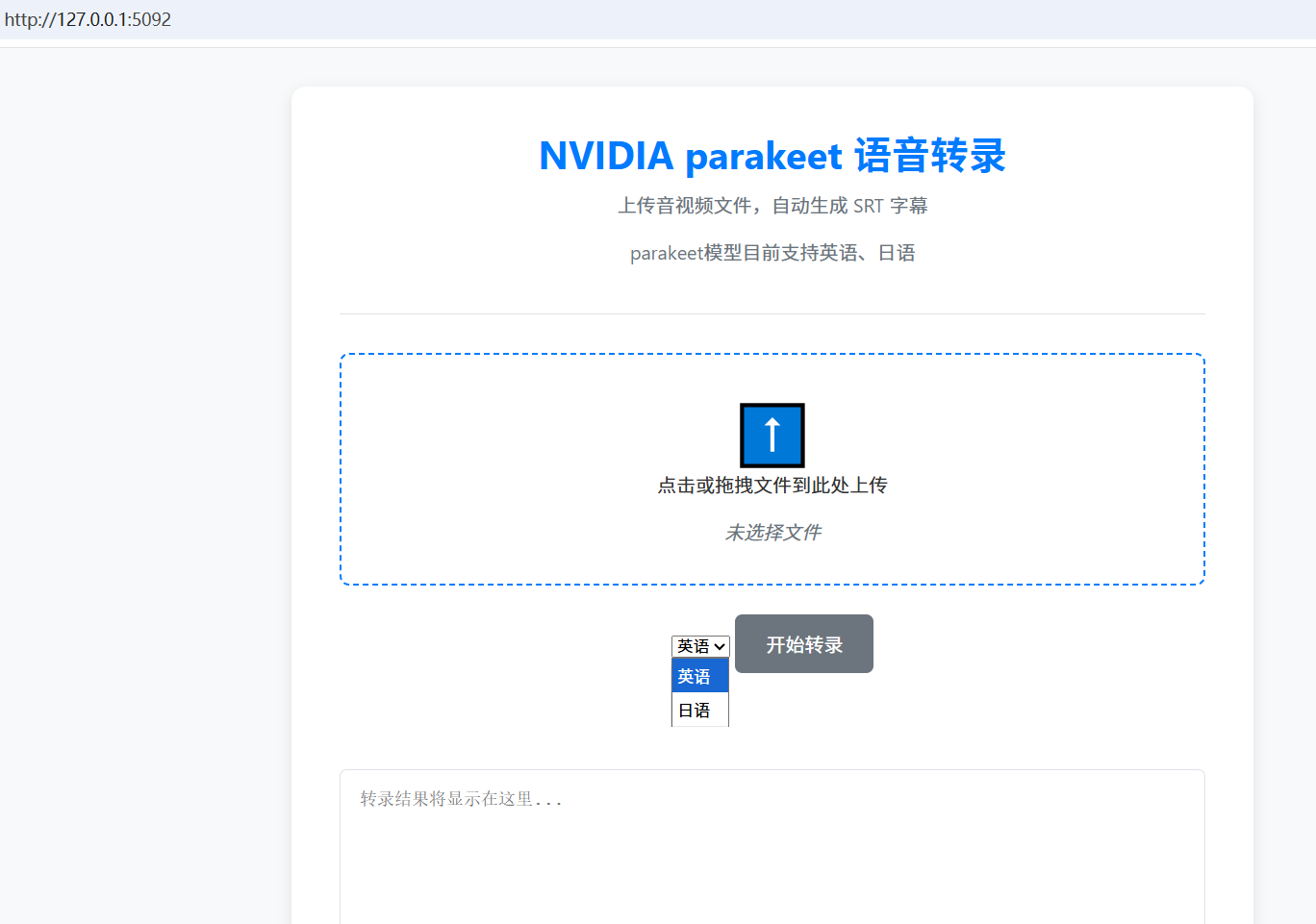
操作流程如下:
- 选择文件: 点击虚线框区域,或将音视频文件直接拖入该区域。
- 选择语言: 在下拉菜单中,根据源文件语言选择“英语”或“日语”。
- 开始转录: 点击 “开始转录” 按钮。
任务处理完成后,生成的SRT字幕内容会显示在下方的文本框中,并可供下载。
API 调用说明
对于有开发需求的用户,此整合包提供了一个兼容OpenAI Speech to Text API的本地接口。可以通过编程方式调用转录功能。
Python调用示例:
python
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:5092/v1",
api_key="any-key", # api_key可填写任意字符串
)
# 读取本地音频文件
with open("your_audio.mp3", "rb") as audio_file:
# 请求转录
srt_result = client.audio.transcriptions.create(
model="parakeet", # 模型名称固定为parakeet
file=audio_file,
prompt="en", # 指定语言:en为英语,ja为日语
response_format="srt" # 指定返回SRT格式
)
print(srt_result)```
### **总结**
这个工具包为处理英语和日语语音转录提供了一个本地化的解决方案。用户按照上述步骤操作,即可在自己的计算机上完成音视频到字幕的转换。