说话人识别/分离
从 v3.93 版本后,支持说话人识别,支持4种不同模型,可在 菜单--工具--高级选项--语音识别参数区域调整
注意:受限于当前模型性能,说话人识别并不准确
软件界面中选中说话人识别复选框即可。
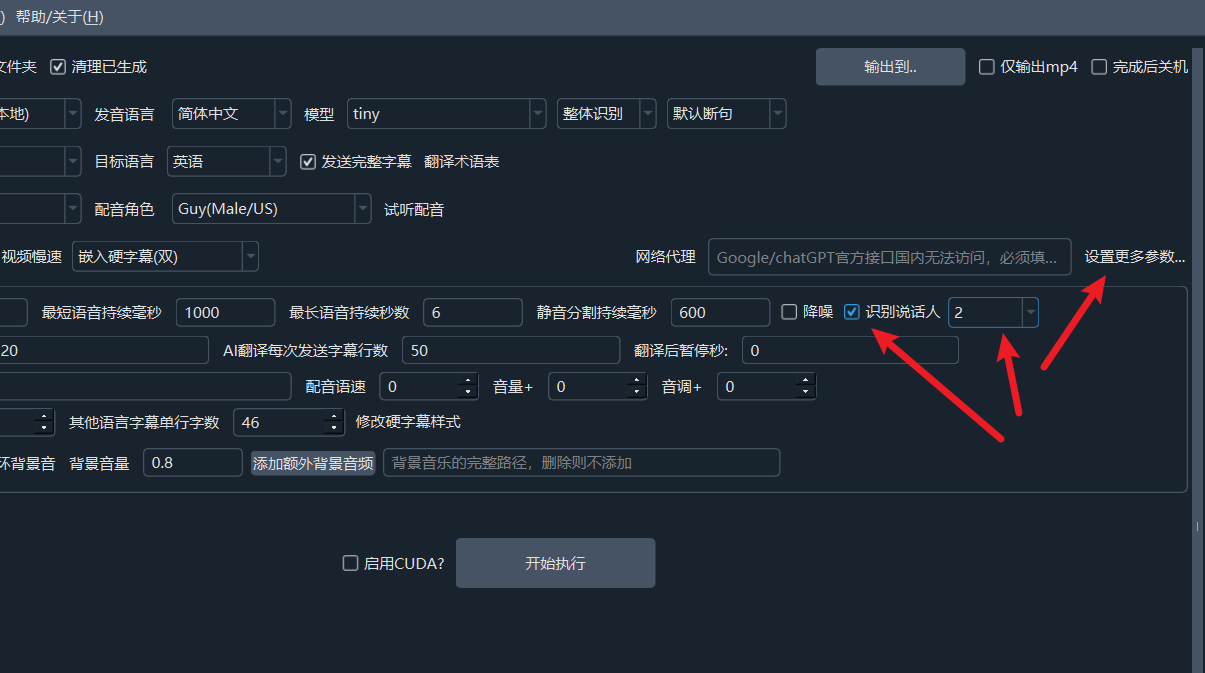 该复选框后边的数字是确定要识别的人数,默认不限制,如果你已知说话人,建议选择某个数字(2-10),将能提高识别准确度
该复选框后边的数字是确定要识别的人数,默认不限制,如果你已知说话人,建议选择某个数字(2-10),将能提高识别准确度
1. 默认 中英说话人分离模型
该模型内置,开箱即用,无需特殊配置,中文模型为 models/onnx/3dspeaker_speech_eres2net_large_sv_zh-cn_3dspeaker_16k.onnx 英文模型models/onnx/nemo_en_titanet_small.onnx
2. 使用 pyannote 说话人分离模型 speaker-diarization-3.1
注意这是一个私有模型,你必须到该模型官方仓库填写信息同意协议,方可合法使用
确认你能访问 https://huggingface.co/pyannote/speaker-diarization-3.1 网站(该站国内已被墙),并拥有一个账号,如果没有,请免费注册并登陆
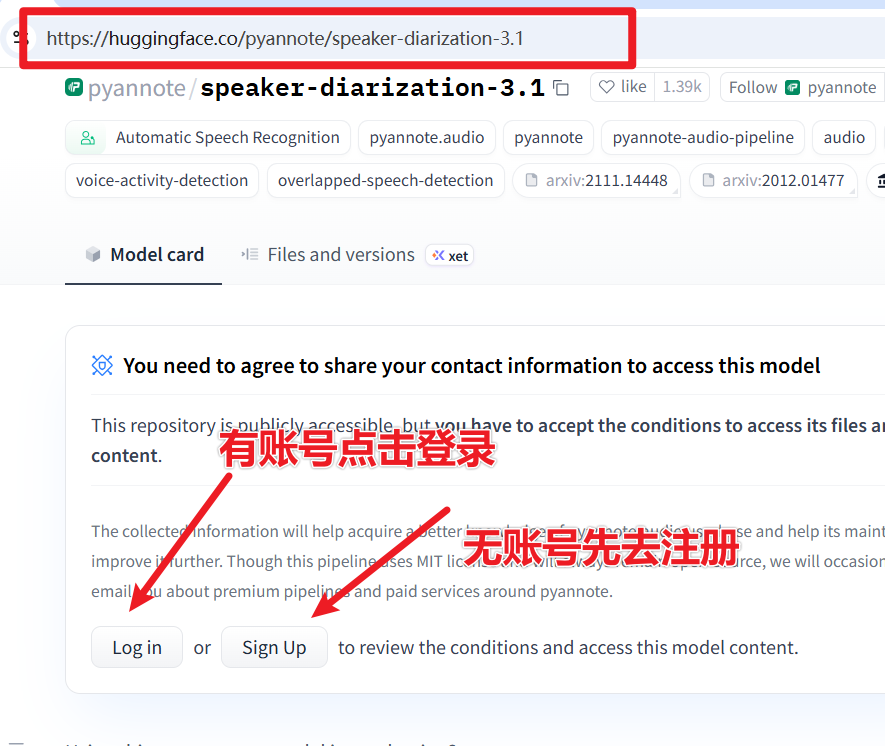
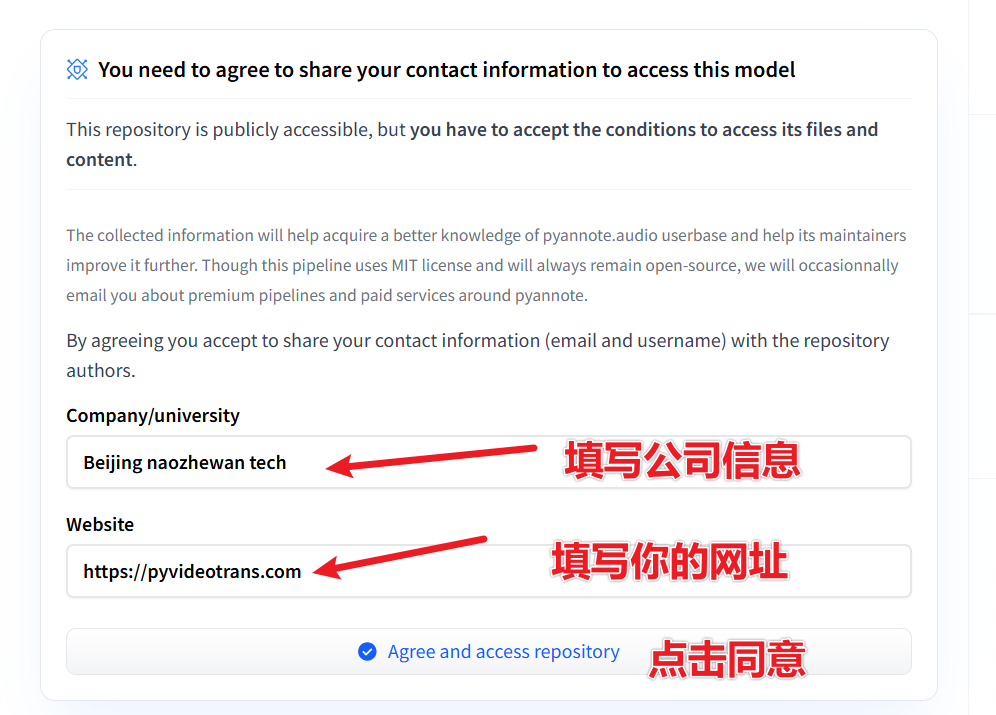
登录并打开该网址: https://huggingface.co/pyannote/speaker-diarization-3.1 ,如图填写相关信息,然后点击
Agree and access repository
- 然后访问这个网址:https://huggingface.co/settings/tokens/new?tokenType=read 随意填写一个英文名字,点击
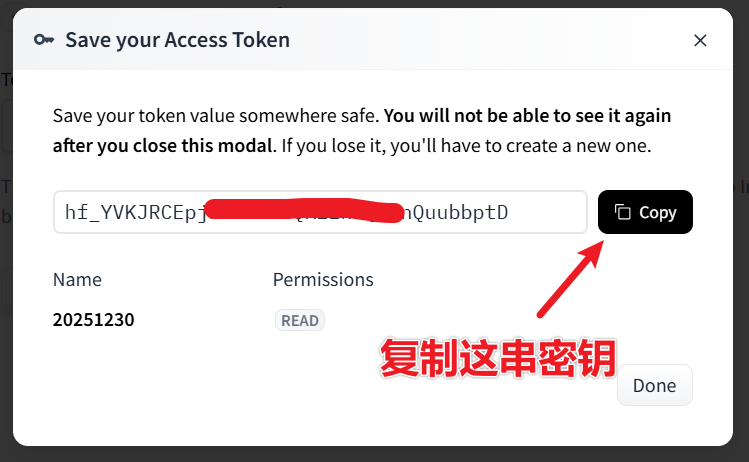
Create token,如下图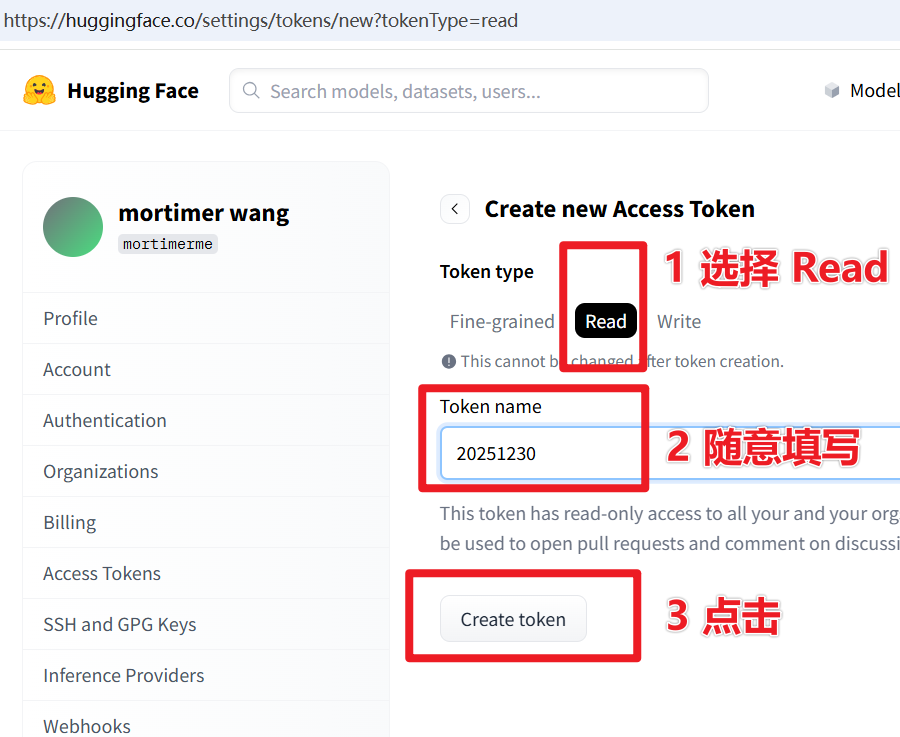
在弹出的密钥界面中,复制这串密钥,如下图
- 打开 pyVideoTrans 软件,点击菜单--工具--高级选项--找到 说话人分离 选项,在下拉菜单中选择
pyannote,并在Huggingface token中填写你刚刚复制的密钥,如下图
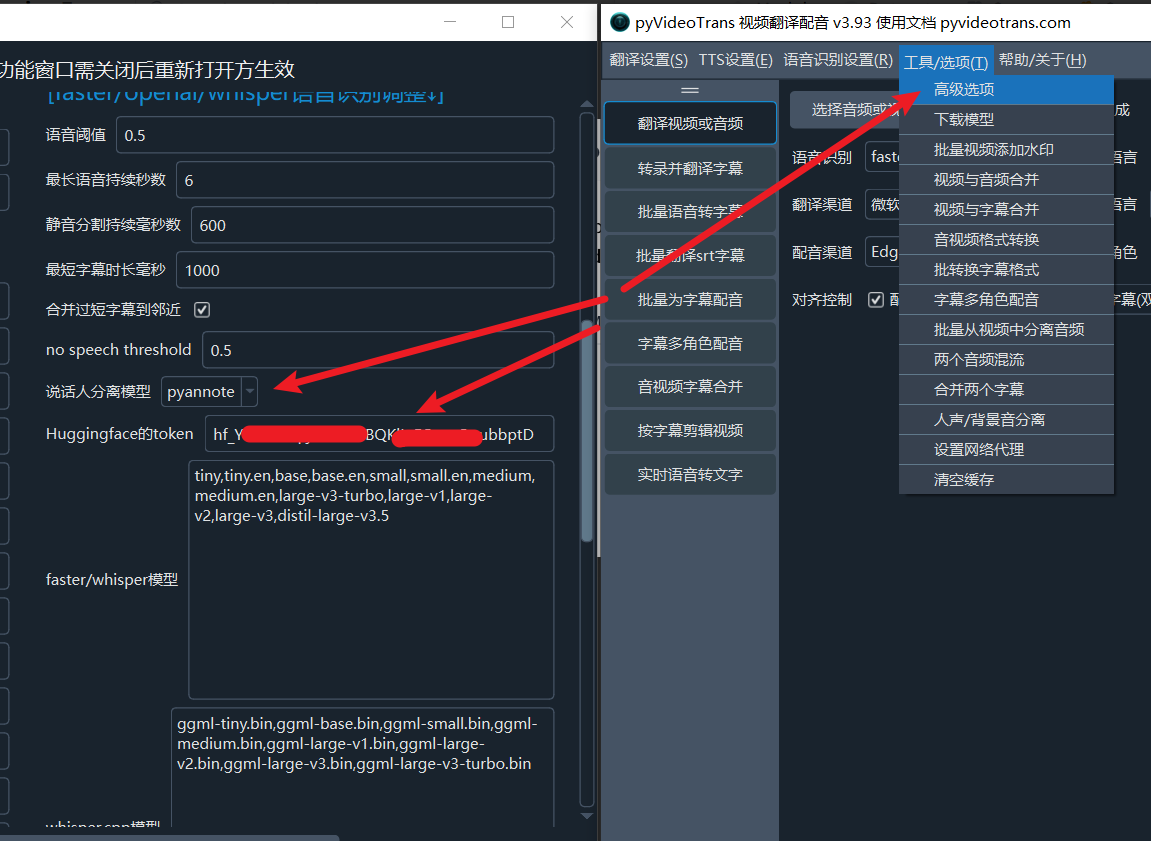
点击保存,就可以使用了
3. 使用 reverb 说话人模型
该模型是 pyannote 的一个变体,使用和要求类似,具体查看 https://huggingface.co/Revai/reverb-diarization-v1
4. 使用阿里的 CAM++ 说话人识别模型
第一次使用将在线下载,支持中文和英文语音