一个完全在你自己电脑上运行的单文件的实时语音转文字工具——就像你的专属速记员:你说什么,它就记什么。

一眼看功能(快速了解)
- 🎤 实时转录:延迟极低(约 3 秒内),你说话即时看到文字。
- 📝 智能加标点:自动为停顿的句子补上逗号、句号、问号等,输出通顺段落。
- 🔐 纯本地运行:所有语音和文本都在本机处理,不上传到网络(首次需手动下载模型)。
- 📂 自动保存录音:程序会保存
.wav录音文件,方便复核。 - 📋 导出与复制:一键复制或导出为
.txt。
使用前的准备(三步走,面向小白)
第一步:安装 uv
如果你还没安装 uv,请参考我上一篇文章里的说明进行安装(此处不再赘述)。
本文后面包含完整单文件代码
app.py,也提供了app.py的下载链接
第二步:下载程序与模型文件
程序代码:把本文末尾的完整代码复制到一个新建的文本文档里,保存为
app.py。注意:在文件管理器里打开“查看”→勾选“显示扩展名”,确保文件确实名为
app.py而不是app.py.txt。模型:这是识别效果的“大脑”。请下载模型压缩包(手动点击或复制到浏览器打开):
https://github.com/jianchang512/stt/releases/download/0.0/realtimestt-models.7z下载后解压,取出以下 4 个文件放入下一步创建的
onnx文件夹:ctc.model.onnxdecoder.onnxencoder.onnxtokens.txt
提示:如果你忘记下载模型,程序首次运行会弹窗提示并自动将下载地址复制到剪贴板,方便你粘贴到浏览器下载。
第三步:整理文件夹结构
在电脑上新建一个文件夹,例如 语音转文字工具,按下面要求放文件:
语音转文字工具/
|- app.py
|- onnx/
|- ctc.model.onnx
|- decoder.onnx
|- encoder.onnx
|- tokens.txtapp.py放在根目录(不是onnx里)。onnx文件夹必须存在,且包含上面 4 个模型相关文件。- 程序会自动在根目录生成
output文件夹用于存储录音与文本备份。
启动程序(一步步来,很简单)
- 打开你放
app.py的文件夹。 - 在资源管理器地址栏中清空并输入
cmd,按回车 —— 会在该文件夹位置打开命令窗口。 - 在命令行中输入:
uv run app.pyuv 会创建运行环境并安装依赖(首次运行会比较慢,请耐心等候)。启动成功后会弹出程序界面(见下图):
界面与操作说明
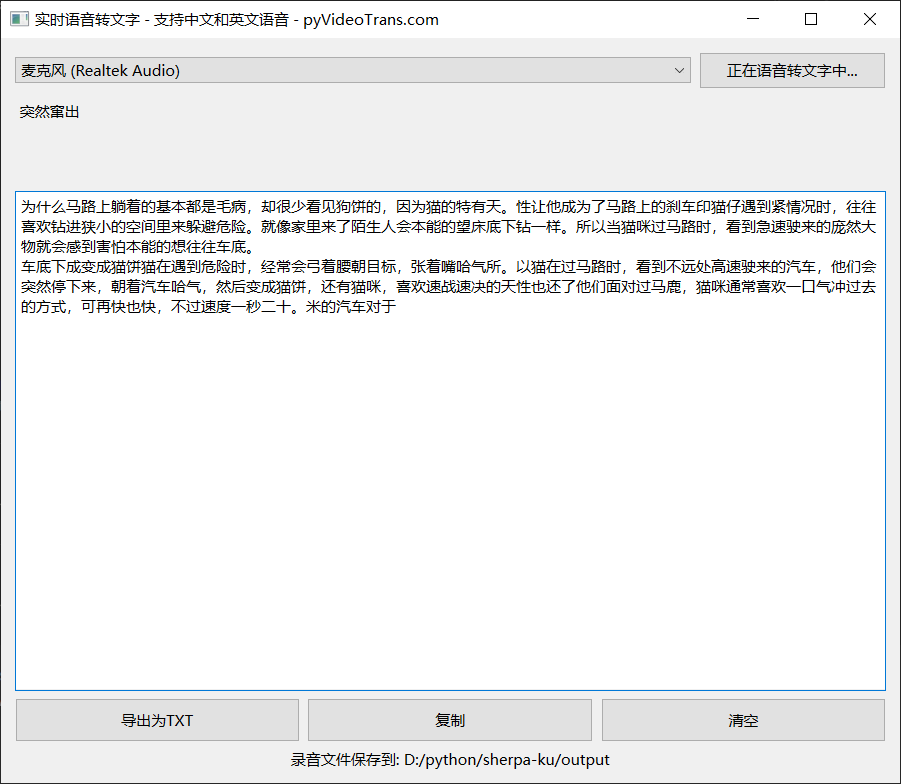
界面要点:
选择麦克风:程序自动列出系统检测到的麦克风设备,一般选择“默认”即可。
启动/停止按钮:点击 “启动实时语音转文字” 开始转录;再次点击则停止。
实时显示区:你说话时,这里显示「正在识别的临时文本」。
最终结果区:当系统检测到你停顿(约 2–3 秒)后,会将当前句子加上标点并放到这里,作为“已完成”段落。
功能按钮区:
- 导出为TXT:保存最终结果为
.txt文件。 - 复制:一键复制所有识别结果到剪贴板。
- 清空:清空结果区。
- 导出为TXT:保存最终结果为
录音文件位置显示:程序会在运行目录下创建
output文件夹保存.wav和.txt备份。点击路径即可打开文件夹查看。
运行细节与注意事项(避免踩雷)
- 采样率与设备:程序以 48 kHz 采样读取麦克风(内部会做必要转换)。如果你的麦克风被其他程序占用,可能无法开启,先关闭占用麦克风的应用。
- 模型必须就位:如果
onnx目录里缺少模型文件,程序会弹窗并自动把下载链接复制到你的剪贴板。 - 首次运行慢:
uv会在首次运行时安装依赖,时间视网络和电脑情况而定,耐心等待即可。 - 隐私:所有语音与文本都保存在你的机器上,不会上传网络。
- 口音、噪音:在普通话标准且环境安静的情况下识别效果最佳;噪声大或方言会降低准确率。
- 录音保存位置:
output文件夹内的*.wav文件和自动备份的*.txt文件可以用来回查或二次处理。
常见问题
Q:识别准确率如何? A:普通话、清晰发音、低噪环境下效果很好。口音重或背景噪声多时,准确率会下降。
Q:支持哪些语言? A:目前着重优化中文普通话,也能识别常见英文词汇或短语,但整体以中文为主。
Q:点击启动没反应怎么办? A:先确认
onnx文件夹里有模型文件(参见第三步);确认麦克风已接入且系统授权应用使用麦克风;检查uv run是否在正确文件夹内运行。Q:程序收费吗? A:完全免费。
小贴士(让你使用更顺手)
- 会议场景:把笔记本或麦克风靠近发言者,确保麦克风拾音质量。
- 备份:每次会议或重要录音后把
output文件夹里的.wav与.txt另存一份到云盘或外部硬盘。 - 自动化:如果你熟悉脚本,可以写个批处理或快捷方式直接在程序文件夹双击运行
uv run app.py。 - 将这个代码保存为
start.bat,即可实现双击start.bat快速启动
@echo off
call uv run app.py
pause完整程序代码(复制到 app.py 保存即可)
微信复制不方便时,也可以在浏览器中打开下载:
https://github.com/jianchang512/stt/releases/download/0.0/app.py
# /// script
# requires-python = "==3.12.*"
# dependencies = [
# "librosa>=0.11.0",
# "numpy>=2.3.4",
# "onnxruntime>=1.23.2",
# "pyside6>=6.10.0",
# "sherpa-onnx>=1.12.15",
# "sounddevice>=0.5.3",
# "soundfile>=0.13.1",
# ]
#
# [[tool.uv.index]]
# url = "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple"
#
# ///
import sys,os
import time
import threading
from pathlib import Path
import sherpa_onnx
import onnxruntime
import numpy as np
import sounddevice as sd
import wave
from PySide6.QtWidgets import QApplication, QWidget, QVBoxLayout, QHBoxLayout, QComboBox, QPushButton, QPlainTextEdit, QFileDialog,QLabel
from PySide6.QtCore import QThread, Signal,Qt,QUrl
from PySide6.QtGui import QIcon, QCloseEvent,QDesktopServices
from PySide6.QtWidgets import QMessageBox
ROOT_DIR=Path(os.getcwd()).as_posix()
MODEL_DIR=f'{ROOT_DIR}/onnx'
OUT_DIR=f'{ROOT_DIR}/output'
Path(MODEL_DIR).mkdir(exist_ok=True)
Path(OUT_DIR).mkdir(exist_ok=True)
CTC_MODEL_FILE=f"{MODEL_DIR}/ctc.model.onnx"
PAR_ENCODER = f"{MODEL_DIR}/encoder.onnx"
PAR_DECODER = f"{MODEL_DIR}/decoder.onnx"
PAR_TOKENS = f"{MODEL_DIR}/tokens.txt"
class OnnxModel:
def __init__(self):
session_opts = onnxruntime.SessionOptions()
session_opts.log_severity_level = 3 # error level
self.sess = onnxruntime.InferenceSession(CTC_MODEL_FILE, session_opts)
self._init_punct()
self._init_tokens()
def _init_punct(self):
meta = self.sess.get_modelmeta().custom_metadata_map
punct = meta["punctuations"].split("|")
self.id2punct = punct
self.punct2id = {p: i for i, p in enumerate(punct)}
self.dot = self.punct2id["。"]
self.comma = self.punct2id[","]
self.pause = self.punct2id["、"]
self.quest = self.punct2id["?"]
self.underscore = self.punct2id["_"]
def _init_tokens(self):
meta = self.sess.get_modelmeta().custom_metadata_map
tokens = meta["tokens"].split("|")
self.id2token = tokens
self.token2id = {t: i for i, t in enumerate(tokens)}
unk = meta["unk_symbol"]
assert unk in self.token2id, unk
self.unk_id = self.token2id[unk]
def __call__(self, text: str) -> str:
word_list = text.split()
words = []
for w in word_list:
s = ""
for c in w:
if len(c.encode()) > 1:
if s == "":
s = c
elif len(s[-1].encode()) > 1:
s += c
else:
words.append(s)
s = c
else:
if s == "":
s = c
elif len(s[-1].encode()) > 1:
words.append(s)
s = c
else:
s += c
if s:
words.append(s)
ids = []
for w in words:
if len(w[0].encode()) > 1:
# a Chinese phrase:
for c in w:
ids.append(self.token2id.get(c, self.unk_id))
else:
ids.append(self.token2id.get(w, self.unk_id))
segment_size = 30
num_segments = (len(ids) + segment_size - 1) // segment_size
punctuations = []
max_len = 200
last = -1
for i in range(num_segments):
this_start = i * segment_size
this_end = min(this_start + segment_size, len(ids))
if last != -1:
this_start = last
inputs = ids[this_start:this_end]
out = self.sess.run(
[
self.sess.get_outputs()[0].name,
],
{
self.sess.get_inputs()[0]
.name: np.array(inputs, dtype=np.int32)
.reshape(1, -1),
self.sess.get_inputs()[1].name: np.array(
[len(inputs)], dtype=np.int32
),
},
)[0]
out = out[0] # remove the batch dim
out = out.argmax(axis=-1).tolist()
dot_index = -1
comma_index = -1
for k in range(len(out) - 1, 1, -1):
if out[k] in (self.dot, self.quest):
dot_index = k
break
if comma_index == -1 and out[k] == self.comma:
comma_index = k
if dot_index == -1 and len(inputs) >= max_len and comma_index != -1:
dot_index = comma_index
out[dot_index] = self.dot
if dot_index == -1:
if last == -1:
last = this_start
if i == num_segments - 1:
dot_index = len(inputs) - 1
else:
last = this_start + dot_index + 1
if dot_index != -1:
punctuations += out[: dot_index + 1]
ans = []
for i, p in enumerate(punctuations):
t = self.id2token[ids[i]]
if ans and len(ans[-1][0].encode()) == 1 and len(t[0].encode()) == 1:
ans.append(" ")
ans.append(t)
if p != self.underscore:
ans.append(self.id2punct[p])
return "".join(ans)
# Create recognizer
def create_recognizer():
encoder = PAR_ENCODER
decoder = PAR_DECODER
tokens = PAR_TOKENS
recognizer = sherpa_onnx.OnlineRecognizer.from_paraformer(
tokens=tokens,
encoder=encoder,
decoder=decoder,
num_threads=2,
sample_rate=16000,
feature_dim=80,
enable_endpoint_detection=True,
rule1_min_trailing_silence=2.4,
rule2_min_trailing_silence=1.2,
rule3_min_utterance_length=20, # it essentially disables this rule
)
return recognizer
# Worker thread for transcription
class Worker(QThread):
new_word = Signal(str)
new_segment = Signal(str)
ready = Signal()
def __init__(self, device_idx, parent=None):
super().__init__(parent)
self.device_idx = device_idx
self.running = False
self.sample_rate = 48000
self.samples_per_read = int(0.1 * self.sample_rate)
def run(self):
devices = sd.query_devices()
if len(devices) == 0:
return
print(f'使用麦克风: {devices[self.device_idx]["name"]}')
PUNCT_MODEL = OnnxModel()
recognizer = create_recognizer()
stream = recognizer.create_stream()
mic_stream = sd.InputStream(
device=self.device_idx,
channels=1,
dtype="float32",
samplerate=self.sample_rate
)
mic_stream.start()
timestamp = time.strftime("%Y%m%d_%H-%M-%S")
txt_file = open(f"{OUT_DIR}/{timestamp}.txt", 'a')
wav_file = wave.open(f"{OUT_DIR}/{timestamp}.wav", 'wb')
wav_file.setnchannels(1)
wav_file.setsampwidth(2) # int16
wav_file.setframerate(self.sample_rate)
self.ready.emit() # Emit ready signal after initialization
self.running = True
last_result = ""
while self.running:
samples, _ = mic_stream.read(self.samples_per_read)
samples_int16 = (samples * 32767).astype(np.int16)
wav_file.writeframes(samples_int16.tobytes())
samples = samples.reshape(-1)
stream.accept_waveform(self.sample_rate, samples)
while recognizer.is_ready(stream):
recognizer.decode_stream(stream)
is_endpoint = recognizer.is_endpoint(stream)
result = recognizer.get_result(stream)
if result != last_result:
self.new_word.emit(result)
last_result = result
if is_endpoint:
if result:
punctuated = PUNCT_MODEL(result)
txt_file.write(punctuated)
self.new_segment.emit(punctuated)
recognizer.reset(stream)
mic_stream.stop()
wav_file.close()
txt_file.close()
# Main GUI window
class RealTimeWindow(QWidget):
def __init__(self):
super().__init__()
self.setWindowTitle('实时语音转文字 - 支持中文和英文语音 - pyVideoTrans.com')
self.layout = QVBoxLayout(self)
# Microphone selection
self.mic_layout = QHBoxLayout()
self.combo = QComboBox()
self.populate_mics()
self.mic_layout.addWidget(self.combo)
self.start_button = QPushButton('启动实时语音转文字')
self.start_button.setCursor(Qt.PointingHandCursor)
self.start_button.setMinimumHeight(30)
self.start_button.setMinimumWidth(150)
self.start_button.clicked.connect(self.toggle_transcription)
self.mic_layout.addWidget(self.start_button)
self.layout.addLayout(self.mic_layout)
# Real-time text
self.realtime_text = QPlainTextEdit()
self.realtime_text.setReadOnly(True)
self.realtime_text.setStyleSheet("background: transparent; border: none;")
self.realtime_text.setMaximumHeight(80)
self.layout.addWidget(self.realtime_text)
# Text edit for segments
self.textedit = QPlainTextEdit()
self.textedit.setReadOnly(True)
self.textedit.setMinimumHeight(400)
self.layout.addWidget(self.textedit)
# Buttons layout
self.button_layout = QHBoxLayout()
self.export_button = QPushButton('导出为TXT')
self.export_button.clicked.connect(self.export_txt)
self.export_button.setCursor(Qt.PointingHandCursor)
self.export_button.setMinimumHeight(35)
self.button_layout.addWidget(self.export_button)
self.copy_button = QPushButton('复制')
self.copy_button.setMinimumHeight(35)
self.copy_button.setCursor(Qt.PointingHandCursor)
self.copy_button.clicked.connect(self.copy_textedit)
self.button_layout.addWidget(self.copy_button)
self.clear_button = QPushButton('清空')
self.clear_button.setMinimumHeight(35)
self.clear_button.setCursor(Qt.PointingHandCursor)
self.clear_button.clicked.connect(self.clear_textedit)
self.button_layout.addWidget(self.clear_button)
self.layout.addLayout(self.button_layout)
self.btn_opendir=QPushButton(f"录音文件保存到: {OUT_DIR}")
self.btn_opendir.setStyleSheet("background-color:transparent;border:0;")
self.btn_opendir.clicked.connect(self.open_dir)
self.layout.addWidget(self.btn_opendir)
self.worker = None
self.transcribing = False
def check_model_exist(self):
if not Path(PAR_ENCODER).exists() or not Path(CTC_MODEL_FILE).exists() or not Path(PAR_DECODER).exists():
reply = QMessageBox.information(self,'缺少实时语音转文字所需模型,请去下载',
f'模型下载地址已复制到剪贴板内,请到浏览器地址栏中粘贴下载\n\n为减小软件包体积,默认未内置模型,下载解压后,将其内的4个文件放到 {MODEL_DIR} 文件夹内'
)
QApplication.clipboard().setText('https://github.com/jianchang512/stt/releases/download/0.0/realtimestt-models.7z')
return False
return True
def open_dir(self):
QDesktopServices.openUrl(QUrl.fromLocalFile(OUT_DIR))
def populate_mics(self):
devices = sd.query_devices()
input_devices = [d for d in devices if d['max_input_channels'] > 0]
if not input_devices:
print("未找到任何可用麦克风")
sys.exit(0)
default_idx = sd.default.device[0]
default_item = 0
for i, d in enumerate(input_devices):
self.combo.addItem(d['name'], d['index'])
if d['index'] == default_idx:
default_item = i
self.combo.setCurrentIndex(default_item)
def toggle_transcription(self):
if self.check_model_exist() is not True:
return
if not self.transcribing:
self.realtime_text.setPlainText('请稍等...')
device_idx = self.combo.currentData()
self.worker = Worker(device_idx)
self.worker.new_word.connect(self.update_realtime)
self.worker.new_segment.connect(self.append_segment)
self.worker.ready.connect(self.update_realtime_ready)
self.worker.start()
self.start_button.setText('正在语音转文字中...')
self.transcribing = True
else:
if self.worker:
self.worker.running = False
self.worker.wait()
self.worker = None
self.start_button.setText('启动实时转录')
self.transcribing = False
remaining_text = self.realtime_text.toPlainText().strip()
if remaining_text:
self.textedit.appendPlainText(remaining_text)
scrollbar = self.textedit.verticalScrollBar()
scrollbar.setValue(scrollbar.maximum())
self.realtime_text.clear()
def update_realtime(self, text):
self.realtime_text.setPlainText(text)
scrollbar = self.realtime_text.verticalScrollBar()
scrollbar.setValue(scrollbar.maximum())
def update_realtime_ready(self):
self.realtime_text.setPlainText('请说话...')
def append_segment(self, text):
self.textedit.appendPlainText(text)
scrollbar = self.textedit.verticalScrollBar()
scrollbar.setValue(scrollbar.maximum())
def export_txt(self):
text=self.textedit.toPlainText().strip()
if not text:
return
file_name, _ = QFileDialog.getSaveFileName(self, "Save TXT", "", "Text files (*.txt)")
if file_name:
if not file_name.endswith(".txt"):
file_name += ".txt"
with open(file_name, 'w', encoding='utf-8') as f:
f.write(text)
def copy_textedit(self):
text = self.textedit.toPlainText()
QApplication.clipboard().setText(text)
def clear_textedit(self):
self.textedit.clear()
def closeEvent(self, event: QCloseEvent):
if self.transcribing:
self.toggle_transcription()
super().closeEvent(event)
if __name__ == "__main__":
app = QApplication(sys.argv)
window = RealTimeWindow()
window.show()
sys.exit(app.exec())你可以马上开始
按上面的三步准备文件,运行 uv run app.py 就能启动。如果遇到问题,先检查 onnx 文件是否完整、麦克风是否被系统识别、以及 uv 是否成功安装。