功能:批量语音转字幕
支持的视频格式
mp4/mov/avi/mkv/webm/mpeg/ogg/mts/ts支持的音频格式
wav/mp3/m4a/flac/aac
这是一个专门用于将 音频视频文件转录为文字或字幕的功能面板,有时你可能不想翻译视频,而仅仅想批量根据音视频生成字幕,那么这个功能再合适不过了。
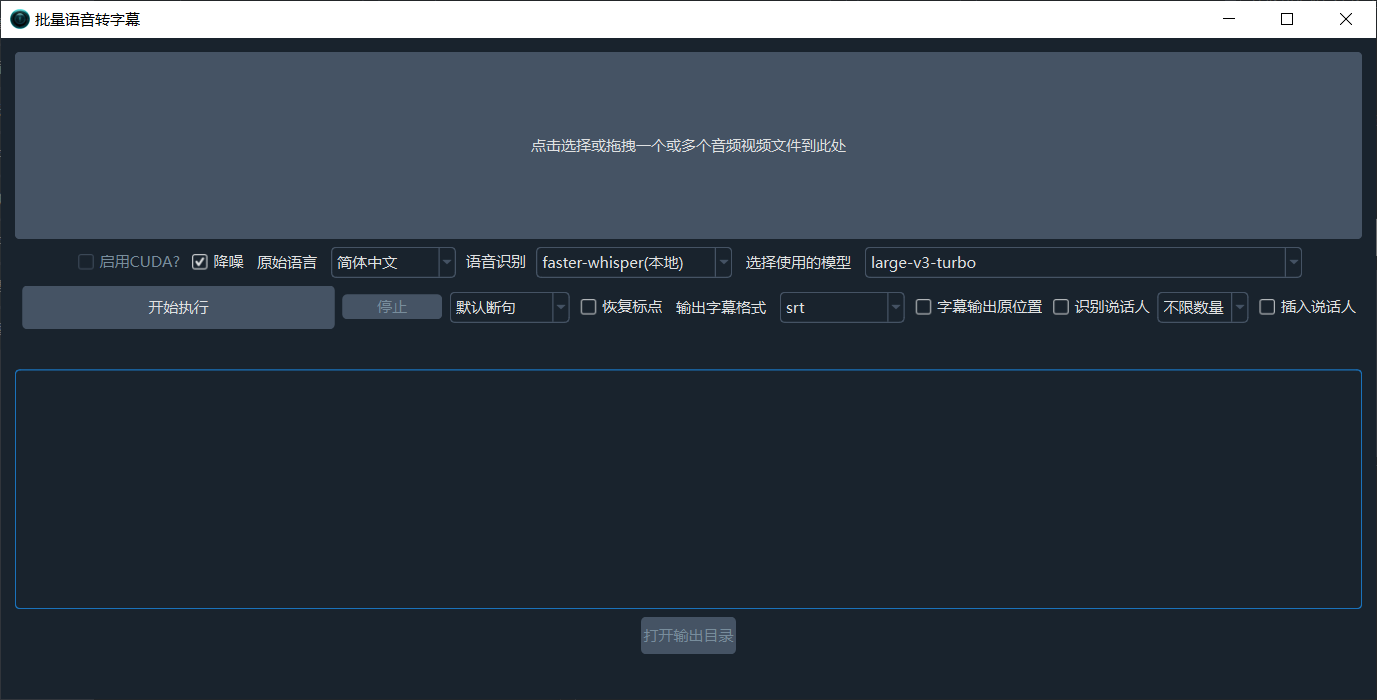
批量将视频或音频文件转录为 字幕或txt。只需拖入文件,设定好原始语言(说话语言)和识别模型,即可开始。支持 重新断句 和 降噪 、说话人识别等高级功能。
顶部大按钮,点击或拖拽进去想转录的音视频文件,可一个或多个
启用CUDA: windows或linux系统如果由英伟达显卡并配置了CUDA,可选中,将加快转录速度
原始语言:音视频中说话语言,请正确选择,否则转录必然出错,如果不确定,可下拉底部选择auto语音识别:在可选择使用哪个方式进行语音转录,无特殊需要,选择 faster-whsiper即可faster-whisper(本地):这是本地模型(第一次运行需在线下载模型),速度和质量都较好,如无特殊需要,可选它。它有十来个不同大小的模型可选,最小最快最节省系统资源的模型是tiny,但准确度很低,不建议使用,效果最好的是 large-v2/large-v3, 建议选择他们。.en结尾和distil-开头的模型只支持英语发音的视频使用。openai-whisper(本地):和上方模型基本类似,不过速度更慢一些,准确度可能略微高一点,同样建议选择 large-v2/large-v3 模型。阿里FunASR(本地):阿里的本地识别模型,对中文支持效果较好,如果你的原始视频是中文说话,可尝试使用它,同样第一次需在线下载模型- 此外还支持 字节火山字幕生成、OpenAI语音识别、Gemini语音识别、阿里Qwen3-ASR语音识别等多种在线API及本地模型
- 全部语音识别渠道说明点击查看
选择模型:模型越大越准确,但速度越慢消耗资源越多。
降噪:若选中,将在语音识别之前,先一步对语音中的噪声进行消除,识别准确度将得到提升
识别说话人:若选中,将在语音识别结束后,尝试识别区分说话人(准确度有限),后边的数字代表预先设定想识别出几个说话人,若提前确定,将增加准确度,默认不限制,
插入说话人:若选择,将在字幕文本开头插入说话人标识,例如
[spk0]默认断句|本地重新断句|LLM重新断句: 可选择默认断句或使用大语言模型对识别出的文字进行智能断句和标点优化,或基于标点符号和时长对识别出的文字进行本地算法重新。
输出格式:默认以srt字幕格式输出转录结果,可选txt 、vtt、ass
整体识别和批量推理:
整体识别将使用内置VAD对语音活动进行检测和区分,断句效果较佳,批量推理按照设定的最大语音持续时长将语音切分,然后每次16份同时识别,速度更快,但断句略微差点。字幕输出原位置:若选中将把转录结果放在原始音视频同文件夹内
打开输出目录:点击该按钮,将打开转录结果保存目录,保存文件名字和原始音视频同名
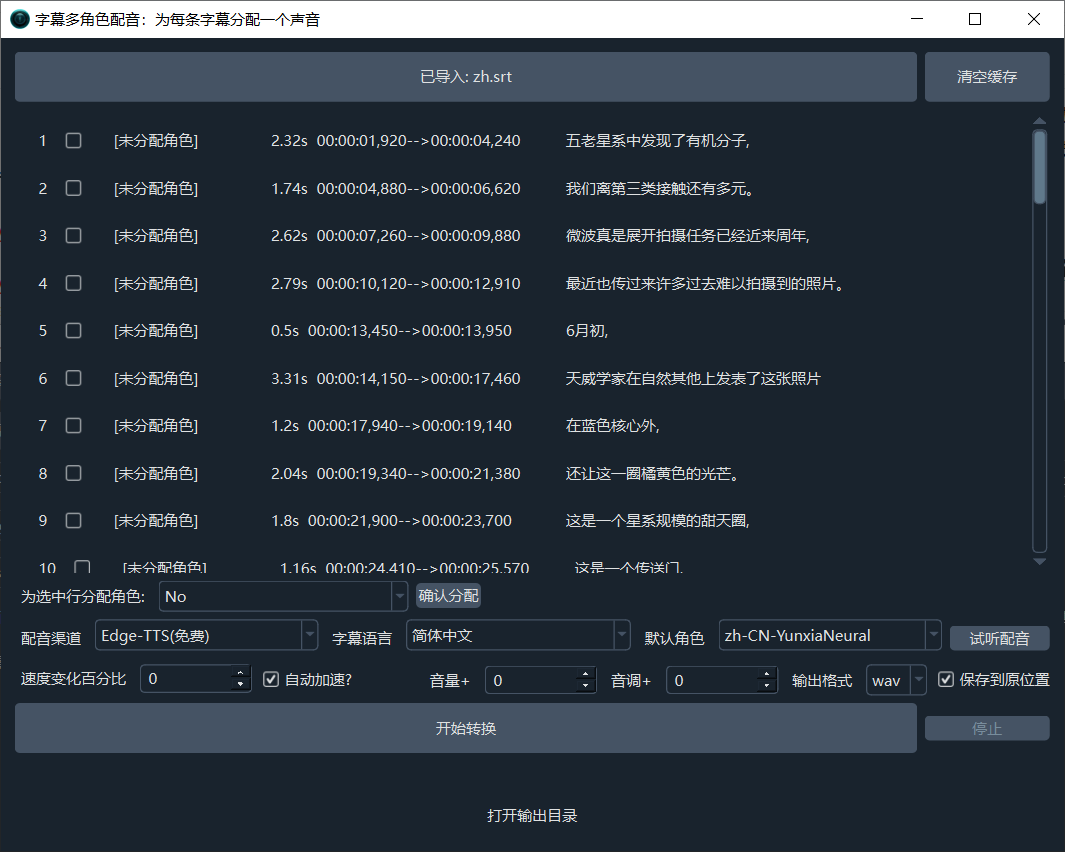
功能:字幕多角色配音/语音合成
支持配音的字幕或文本格式:
srt
同批量为字幕配音功能类似,所不同的是:该功能支持为每行字幕单独指定一个发音人,实现多角色配音。