🧠 本地一键部署你的 WhisperX 网页版 + API,支持说话人分离!
WhisperX 是一个非常强大的语音识别模型,还能实现说话人分离(Diarization)。 不过,官方版本只有命令行工具,对新手不太友好,也没提供 API。
于是我做了一个增强版:whisperx-api!它在原模型基础上,新增了:
- ✅ 本地网页界面 —— 打开浏览器就能用,上传文件一键转录
- ✅ OpenAI 兼容 API —— 可替代原 Whisper API,直接接入项目
- ✅ 说话人分离功能 —— 自动识别并标注不同说话人
- ✅ 一键启动 —— 使用
uv工具,环境配置自动完成
最终效果就像这样👇 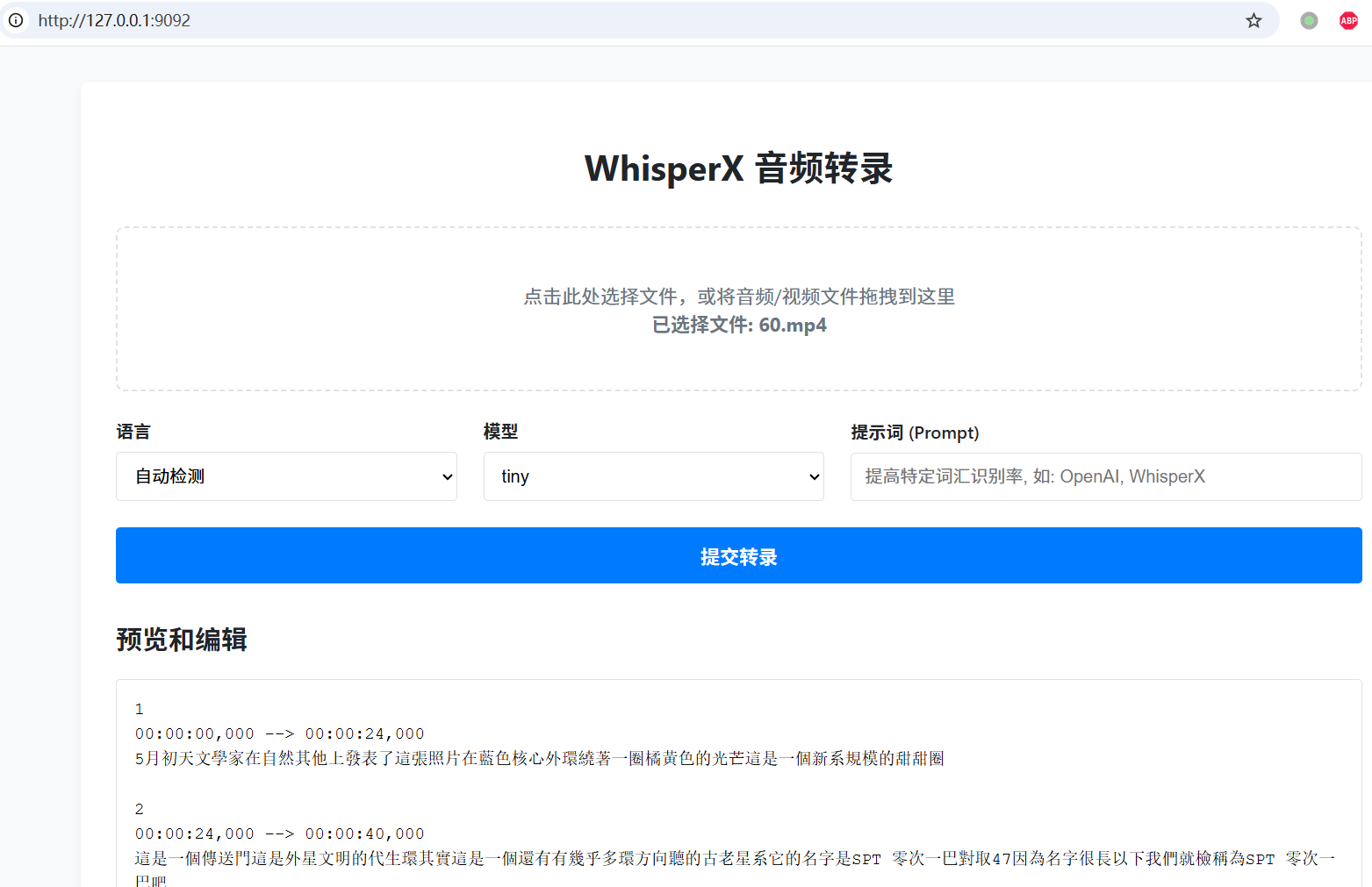
🧰 准备工作:上路前的“装备库”
在开始之前,请先准备以下几样装备👇
1️⃣ 一台电脑
- 推荐配置:NVIDIA 显卡(6GB 显存以上)。
- 没有显卡也没关系:CPU 也能运行,只是速度会慢一些。
2️⃣ 必备软件(新手重点看!)
我们需要以下 2 个工具:
- uv:超快的 Python 包管理器,用它一条命令搞定环境。
- FFmpeg:强大的音视频处理工具,帮助格式转换。
⚠️ 提示:
uv和ffmpeg的安装参考我专门写的详细教程: 👉 https://xxxx.com)
3️⃣ 科学上网工具 (VPN / 代理)
WhisperX 需要从国外服务器下载模型。 请确保你的科学上网工具已开启并保持稳定,否则模型无法正常下载。
🚀 三步搞定,一键启动你的 AI 服务!
✅ 第 1 步:下载项目代码,仅app.py和index.html 2个文件
访问项目主页: https://github.com/jianchang512/whisperx-api
点击绿色的 “Code” → “Download ZIP” 下载压缩包并解压, 然后进入到含有 app.py 和 index.html 文件的文件夹内。
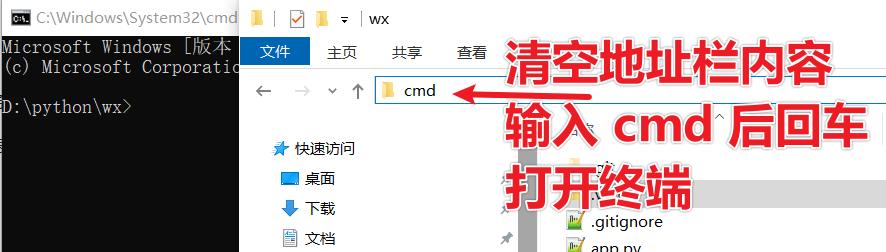
清空文件夹地址栏内容,输入cmd后回车打开黑色终端窗口。
✅ 第 2 步:获取下载“说话人识别”模型的通行证(不需要说话人功能可跳过)
说话人分离模型必须同意他们的协议才能下载,因此需要你先在 Hugging Face 网站上“签署协议”并获取访问令牌。这一步必须科学上网,否则无法打开该网站
① 注册并登录 Hugging Face
访问: https://huggingface.co/ 创建一个免费账户并登录。
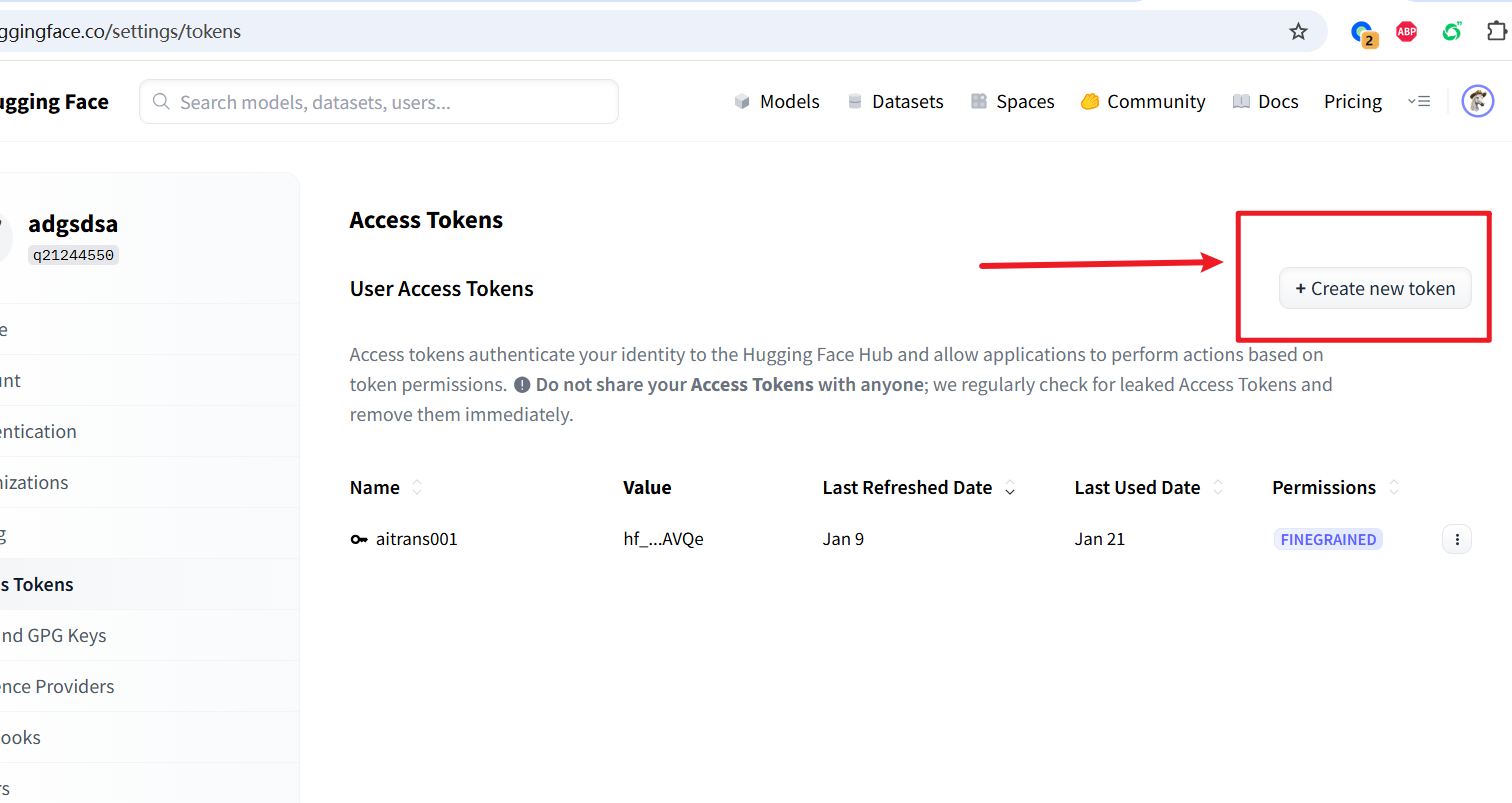
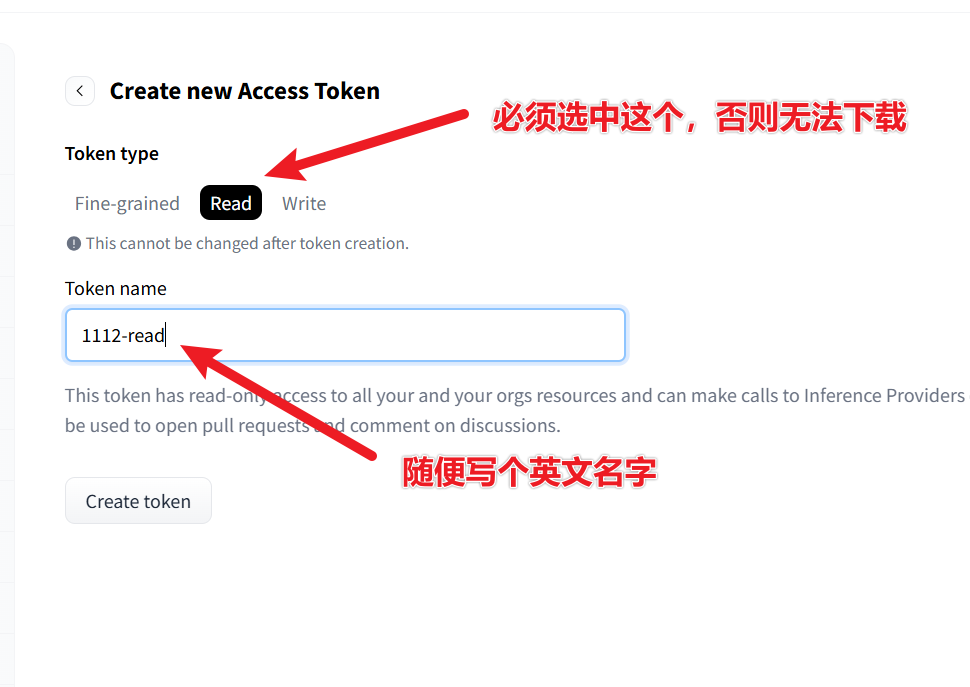
② 创建访问令牌(Token)
访问: https://huggingface.co/settings/tokens 点击 “New token” → 权限选择 read → 创建并复制这串以 hf_ 开头的令牌。
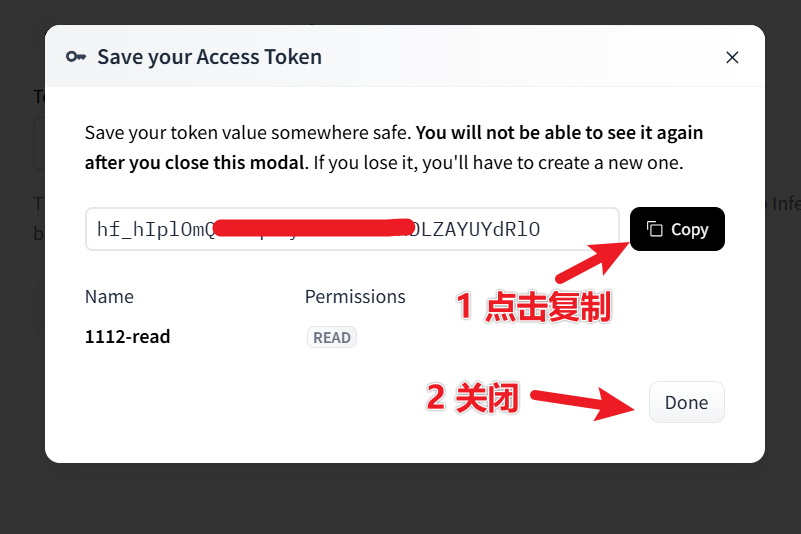
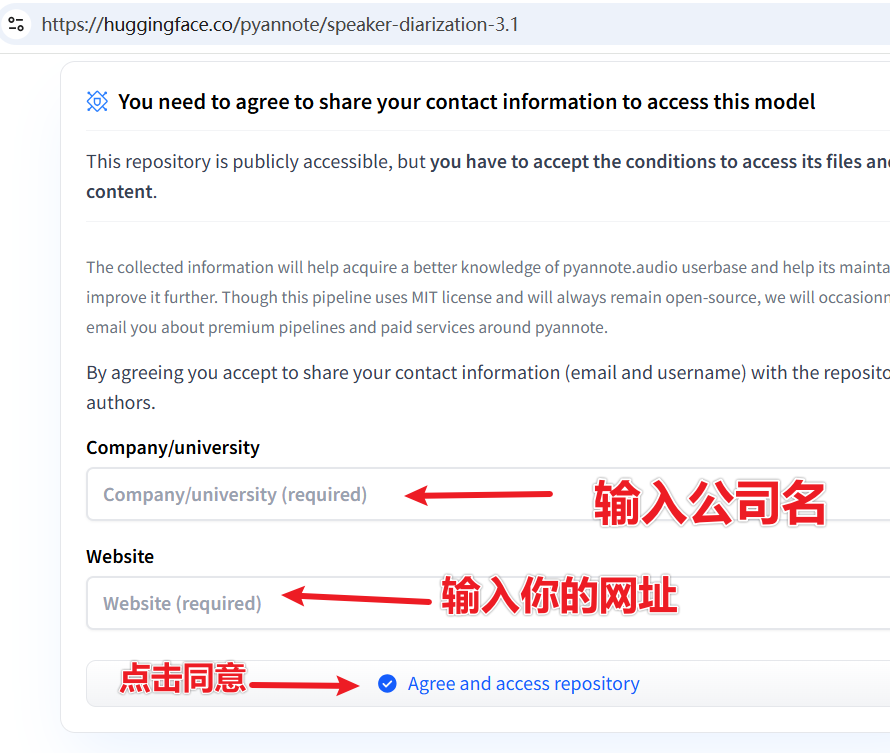
③ 同意模型使用协议(必须勾选!)
依次访问下面两个模型页面并同意协议:
- https://huggingface.co/pyannote/speaker-diarization-3.1
- https://huggingface.co/pyannote/segmentation-3.0
进入页面后,填写显示的2个文本框,然后点击按钮提交。
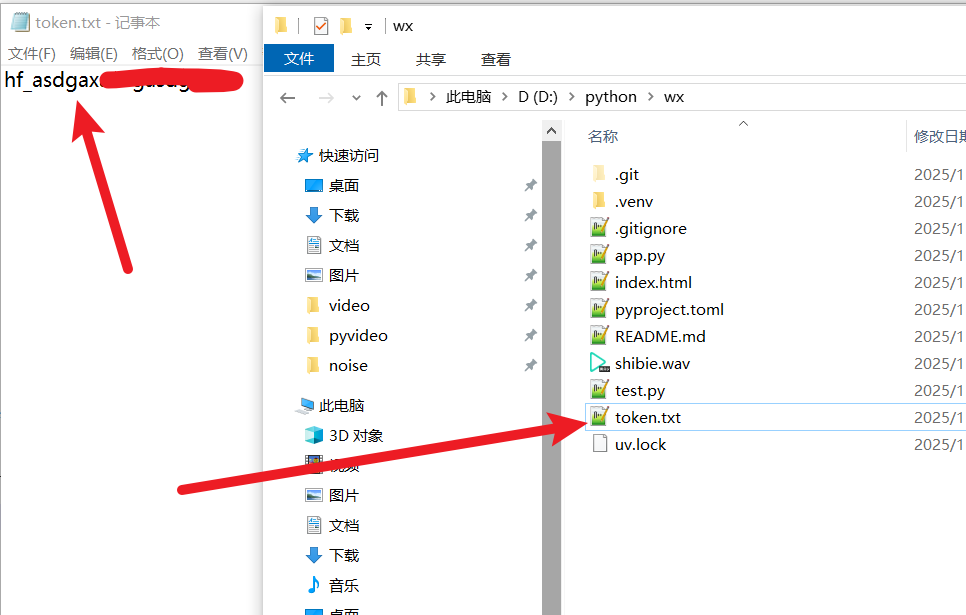
④ 保存令牌
回到你的 whisperx-api 项目文件夹, 新建一个文件 token.txt, 把刚复制的 hf_ 开头的令牌粘贴进去并保存。
✅ 第 3 步:一键启动!
确保你的cmd终端仍在 app.py 所在文件夹中,然后执行:
uv run app.py首次运行时,uv 会自动下载所有依赖并自动加载模型。 根据网络速度,这可能需要几分钟到十几分钟,请耐心等待。
当你看到类似下图的输出,就代表启动成功啦👇 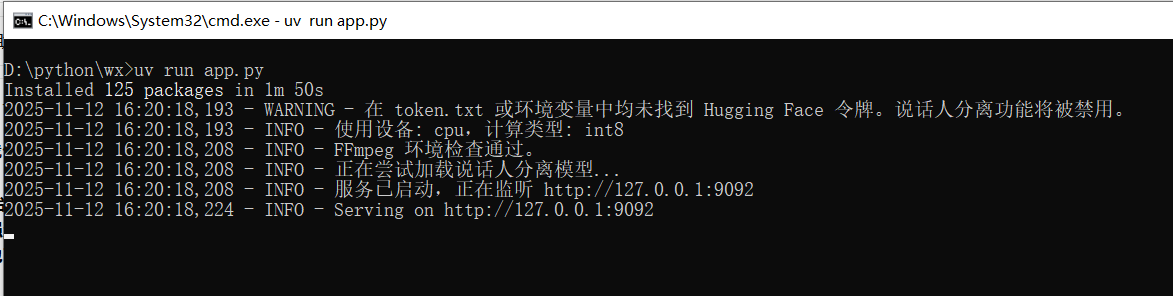
浏览器会自动打开这个地址: http://127.0.0.1:9092
你将看到简洁漂亮的网页界面👇 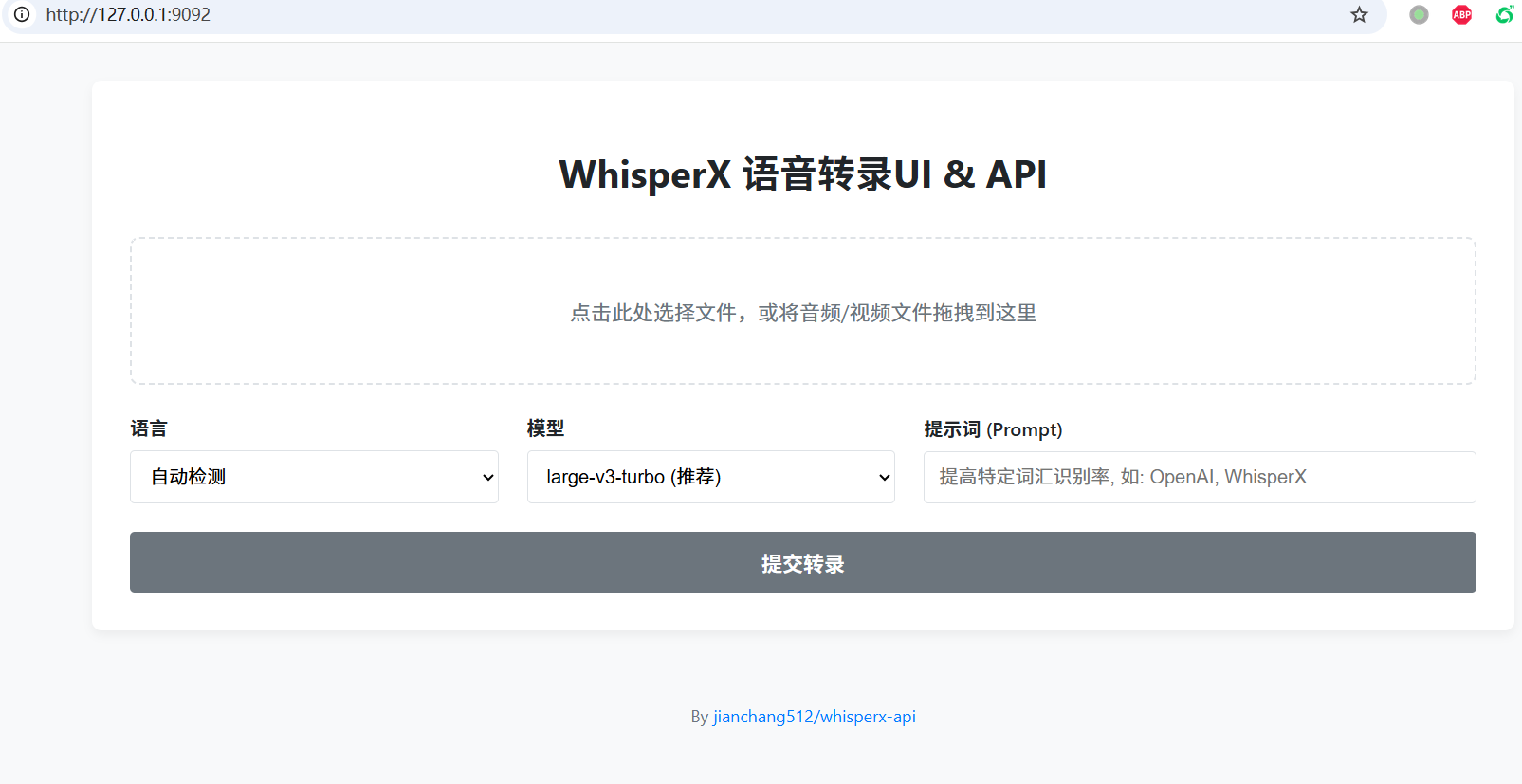
💡 使用指南
现在你可以通过两种方式使用它👇
🌐 方式一:网页操作界面
上传文件 点击或拖拽音频 / 视频文件到虚线框中。
设置选项
- 语言:知道语言就选对应语言,不确定选“自动检测”。
- 模型:越大越准,但越慢。推荐
large-v3-turbo。 - 提示词 (Prompt):可填写人名、术语等提高识别率,如
OpenAI, WhisperX, PyTorch。
开始转录 点击 “提交转录”,等待处理完成。
查看与下载 结果会显示在下方,可直接编辑后点击 “下载 SRT 文件” 保存。
⚙️ 方式二:API 调用(适合开发者)
完全兼容 OpenAI 的接口格式!
示例代码(保存为 test_api.py):
import base64
from openai import OpenAI
# 注意:base_url 是你的本地服务地址
client = OpenAI(base_url='http://127.0.0.1:9092/v1', api_key='any-string-will-work')
audio_path = "shibie.wav"
with open(audio_path, "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="tiny", # 可选 'tiny', 'base', 'large-v3' 等
file=audio_file,
response_format="diarized_json"
)
for segment in transcript.segments:
speaker = segment.get('speaker', 'Unknown')
start_time = segment['start']
end_time = segment['end']
text = segment['text']
print(f"[{start_time:.2f}s -> {end_time:.2f}s] Speaker: {speaker}, Text: {text}")❓ 常见问题 (FAQ)
Q: 启动时报 “FFmpeg not found”? A: 没安装或未加入系统环境变量。 请重新检查 “必备软件” 部分的安装步骤。
Q: 转录按钮点了没反应? A: 第一次运行会下载模型,请耐心等待。 如果报错,请查看终端日志,通常是科学上网工具未开启或不稳定。
Q: 为什么没有 [Speaker1]、[Speaker2]? A:
- 音频中只有一个人说话时不会显示。
- 或者你的 Hugging Face Token 配置错误、协议未同意,请重查 第 2 步。
Q: 处理速度太慢? A: 如果是 CPU 模式,确实较慢。 有 NVIDIA 显卡的用户速度会快数十倍。
🎉 恭喜! 你现在已经拥有一个完全本地化、带网页界面、支持说话人分离的语音转录服务!
赶快试试转录你的播客、会议录音或访谈视频吧~ 祝你玩得开心!🎧💬