v3.83版更新说明
一:增强单视频翻译能力
一次仅选择一个视频时,在语音转录完成后,将弹出单独的字幕编辑窗口,你可在此对字幕进行修改,以便后续过程更准确。
语音识别阶段完成后,弹出字幕修改窗口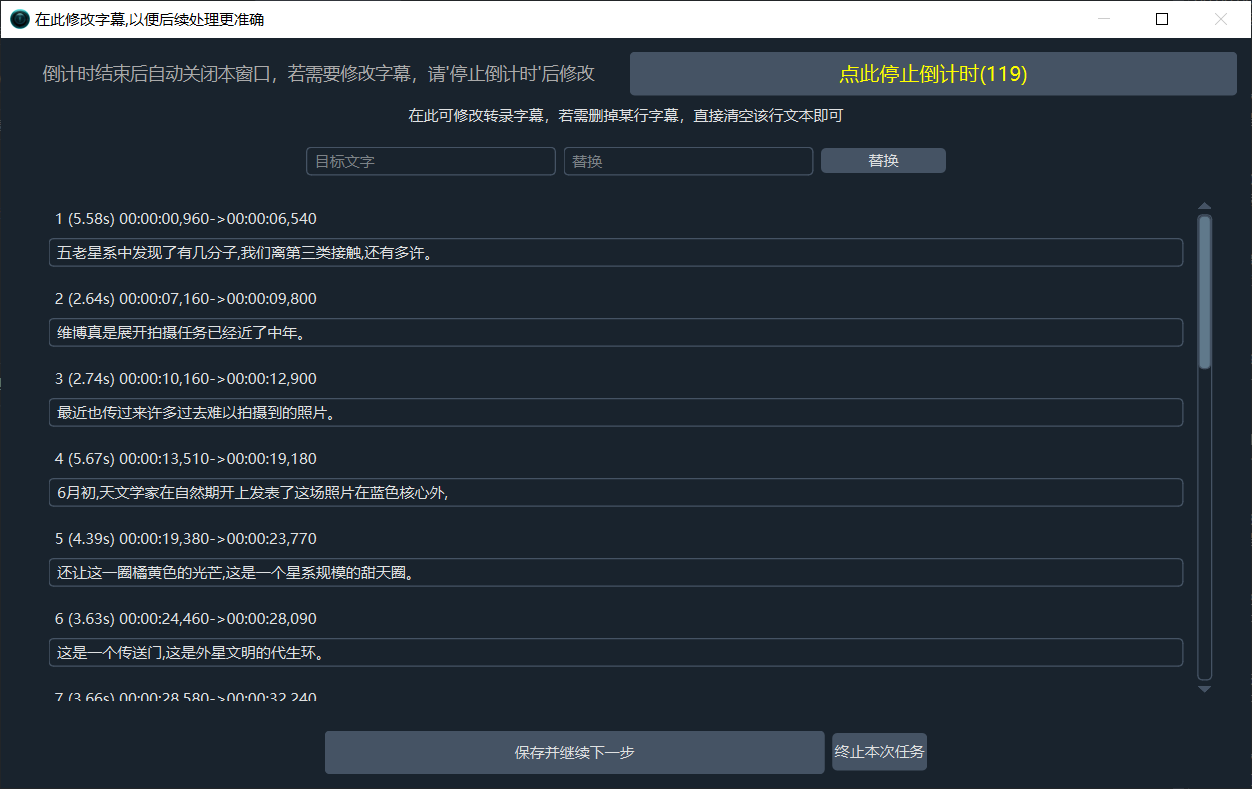
在字幕翻译完成后弹出的窗口中,你还可以为每行字幕单独指定一个发音角色,如果你选的语音识别渠道支持说话人识别,还可为每个说话人设置不同的发音角色
字幕翻译阶段完成后,弹出字幕修改和发音角色修改窗口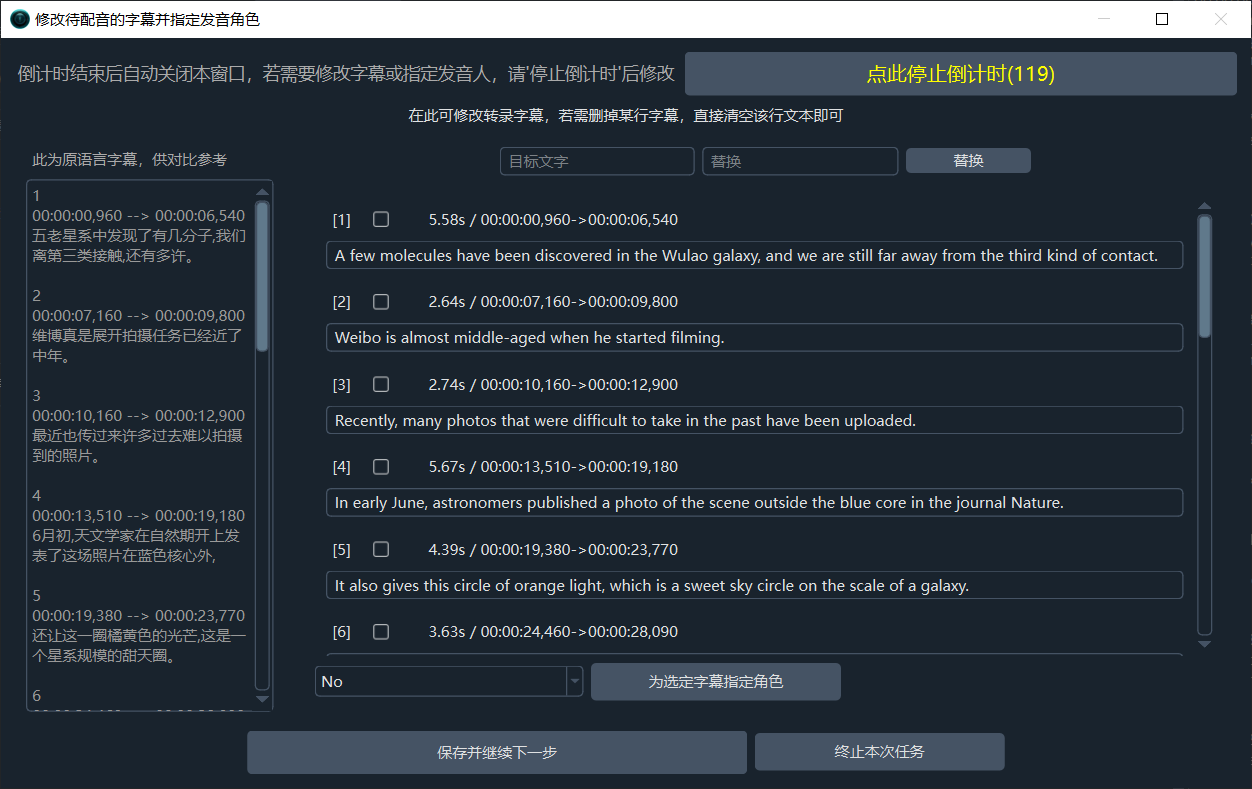
目前支持说话人识别的语音识别渠道有
- 字节语音识别大模型极速版
- GeminiAI大模型识别
- 阿里FunASR中文识别
- Deepgram.com
- OpenAI语音识别(必须是openai官方且模型是gpt-4o-transcribe-diarize)
二:配音渠道增加豆包语音合成大模型2.0
三:语音识别渠道增加字节语音识别大模型极速版API
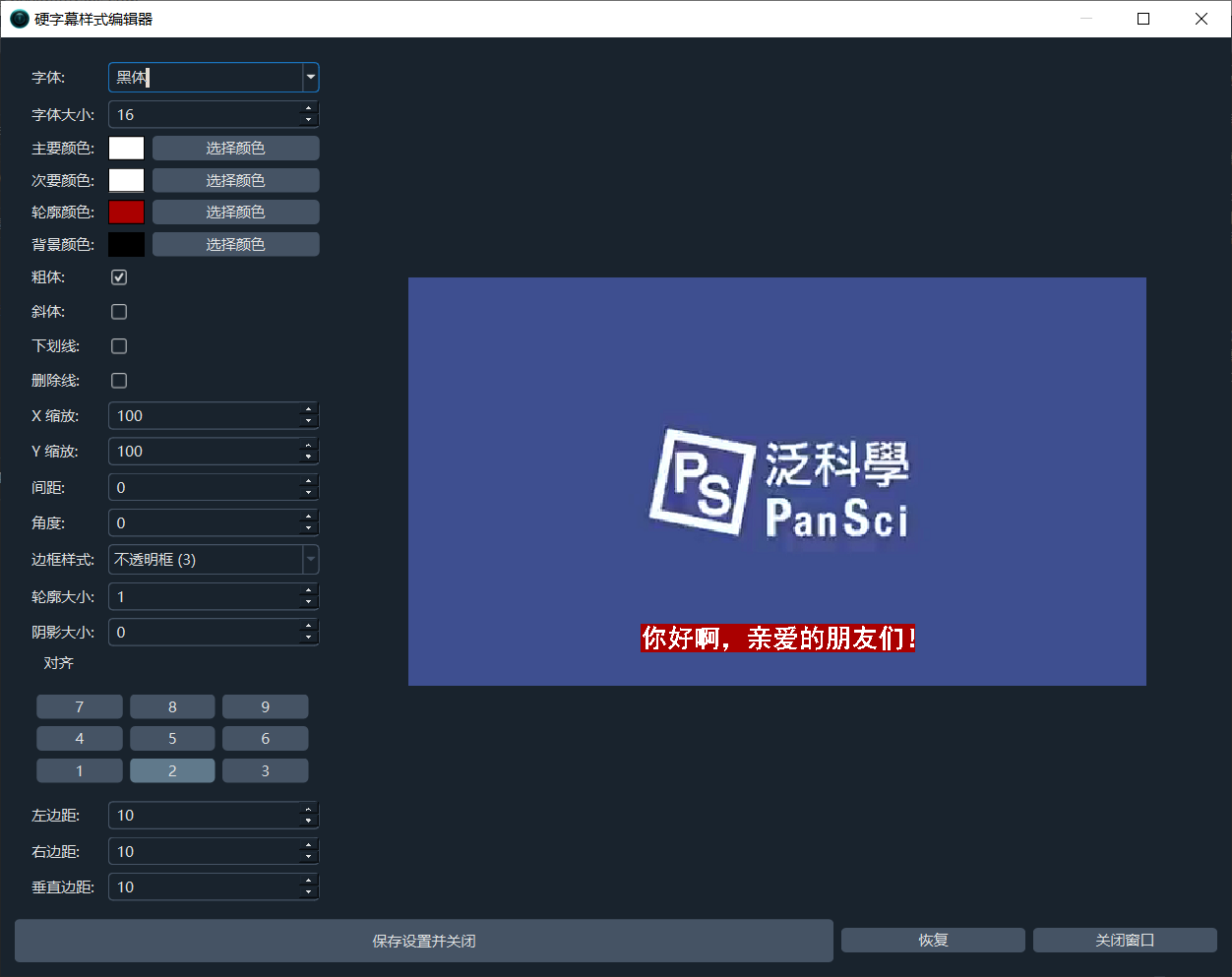
四:增强 硬字幕样式修改和预览功能
软字幕样式由播放器控制,不可调整,硬字幕在嵌入视频前可进行修改调整,点击主界面中的硬字幕样式调整,即弹出修改和预览界面
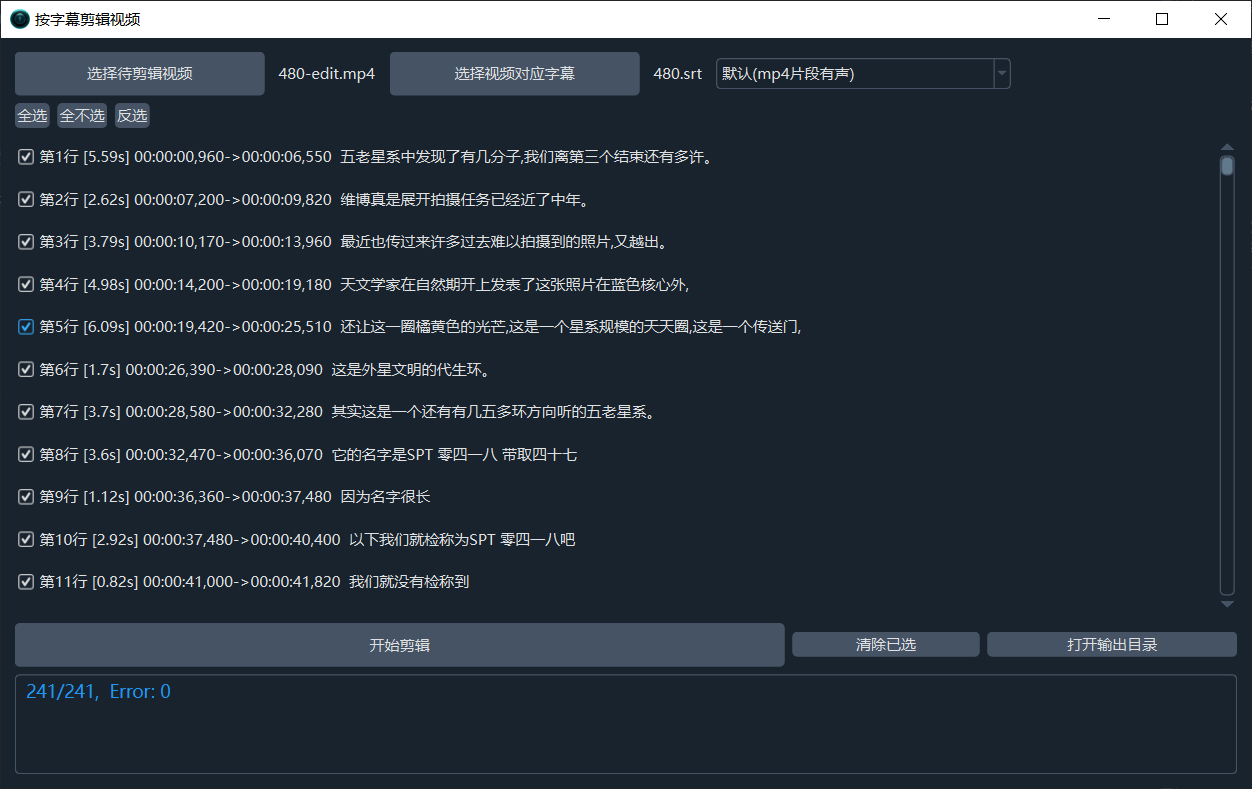
五:增加按字幕剪辑视频功能
如果想根据字幕剪出对应片段,可使用该功能
六:其他优化
- 优化视频慢速算法,增强时间精度
- 选中
清理已生成并且输出目录内存在文件时,增加确认框 - 优化UI布局,按照
语音识别--字幕翻译--字幕配音顺序重新调整 - 修改 语音识别渠道、翻译渠道、配音渠道下拉菜单中各个渠道的排列顺序
- 优化获取ffmpeg硬件编码方式,不再每次启动都测试,而是仅测试一次,除非删掉
videotrans/codec.json缓存文件 - ffmpeg处理时增加
-threads 0参数,增强多核支持