视频翻译软件的核心原理是:根据视频中的说话声音识别出文字,然后将文字翻译为目标语言文字,再将翻译后的文字进行配音,最后将配音、文字嵌入视频。
可以看到第一步就是从视频中的说话声识别出文字,识别精确度直接影响到后续翻译和配音。
faster模式
推荐使用,这是基于OpenAI的开源whisper转换后的模型,就如名字所暗示的,识别速度更快,也不降低准确度。
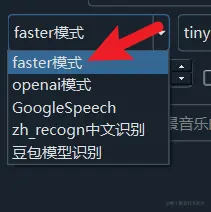
选择faster模式后,即可在右侧选择要使用的模型,默认内置tiny模型,这是最小的一个模型,效果效果也最不精确。
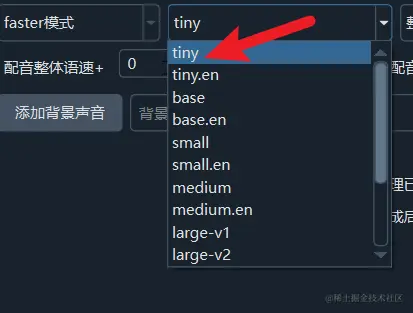
tiny--base--small--medium--large 模型尺寸越来越大,同样识别精确度也越来越高。
对于中文视频,建议至少选择medium模型,模型下载地址在 https://pyvideotrans.com/model
.en后缀的模型和distil开头的模型,只可用于英文视频。
模型右侧还有一个整体识别下拉框,下拉会显示均等分割,一般无特殊需要选择整体识别即可,如果你需要将音频分割为相等时长的各部分,比如想每个字幕时长都是10s,那么可以选择均等分割。并在菜单--工具/高级设置--高级设置--VAD参数部分设置片段时长秒数。
为加快任务速度,在Windows和Linux上,如果有英伟达显卡,可配置安装CUDA和cuDNN环境后,启用CUDA加速,将能明显提高执行速度。
CUDA和cuDNN安装教程见: https://pyvideotrans.com/gpu.html