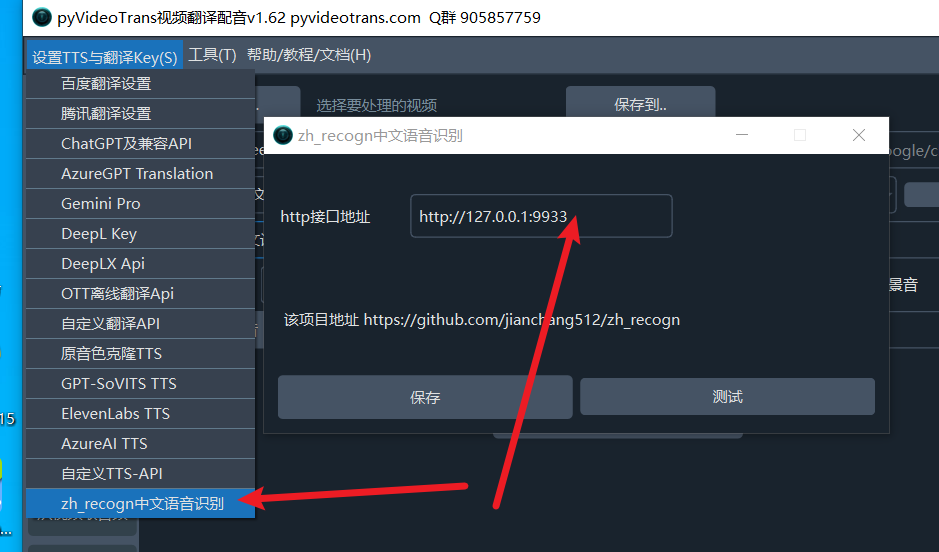
使用zh_recogn 中文语音识别
该识别方式仅仅支持中文语音,使用阿里魔塔社区模型,对中文支持效果较好,可弥补国外模型对中文支持的不足
使用方法
首先部署好 zh_recogn项目
然后启动。将地址(默认 http://127.0.0.1:9933) 填写到软件左上角菜单-设置-zh_recogn中文语音识别--地址中
然后软件界面中“faster模式”下拉框里选择 zh_recogn 即可。选择该项时,无需再选择模型和分割方式。 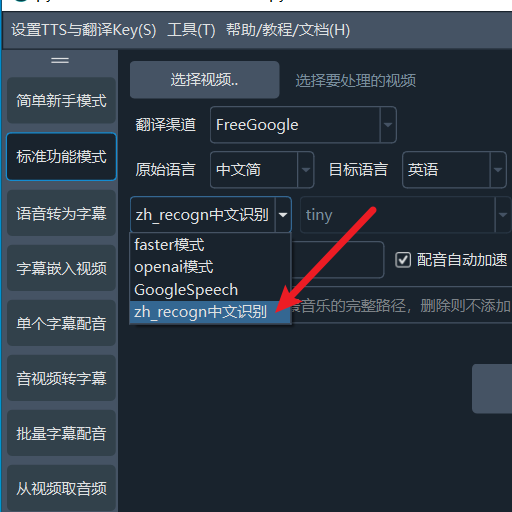
部署 zh_recogn 项目
源码部署
首先安装 python3.10/安装 git ,安装ffmpeg,windows上 下载ffmpeg.exe后放到本项目的ffmpeg文件夹内,mac使用
brew install ffmpeg安装创建个空英文目录,window上在该目录下打开cmd(Macos和Linux使用终端),执行命令
git clone https://github.com/jianchang512/zh_recogn ./继续执行
python -m venv venv,然后Windows中执行.\venv\scripts\activate,Macos和Linux中执行source ./venv/bin/activate继续执行
pip install -r requirements.txt --no-depsWindows和Linux如需cuda加速,继续执行,
pip uninstall torch torchaudio, 再执行pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu118启动项目
python start.py
预打包版/仅win10 win11
下载地址 https://github.com/jianchang512/zh_recogn/releases
下载后解压到英文目录,双击 start.exe
为减小打包体积,预打包版不支持CUDA,若需cuda加速,请源码部署
在 pyvideotrans项目中使用
首先升级 pyvideotrans 到v1.62+,然后左上角设置菜单-zh_recogn中文语音识别菜单点开,填写地址和端口,默认 "http://127.0.0.1:9933", 末尾不要加/api
API
api地址 http://ip:prot/api 默认 http://127.0.0.1:9933/api
python代码请求api示例
import requests
audio_file="D:/audio/1.wav"
file={"audio":open(audio_file,'rb')}
res=requests.post("http://127.0.0.1:9933/api",files=file,timeout=1800)
print(res.data)
[
{
line:1,
time:"00:00:01,100 --> 00:00:03,300",
text:"字幕内容1"
},
{
line:2,
time:"00:00:04,100 --> 00:00:06,300",
text:"字幕内容2"
},
]在 pyvideotrans 中填写时不要末尾添加 /api
web界面
注意事项
- 第一次使用将自动下载模型,用时会较长
- 仅支持中文语音识别
- set.ini文件中可修改绑定地址和端口