语音识别渠道:自定义语音识别 API
这是什么
自定义语音识别 API 是 pyVideoTrans 提供的一个通用接口,允许你对接任何自行搭建或第三方的语音识别服务。只要你的 API 符合规定的请求/响应格式,就可以在这个渠道中使用。
v3.56 版本起,该渠道还内置了对以下服务的特殊支持:
- Gladia —— 云端语音识别服务,自动处理上传和转录流程
- VibeVoice ASR —— 支持说话人分离的本地 ASR 服务
Gladia 的具体使用方法请查看:Gladia 使用教程
适用场景
- 已有自己的语音识别 API 服务
- 需要对接第三方语音识别平台(如 Gladia)
- 现有的内置识别渠道无法满足需求,需要自定义实现
前置条件
| 条件 | 说明 |
|---|---|
| 自建或第三方 API 服务 | 需要有一个符合格式要求的 API 端点 |
| API 密钥(如需要) | 部分服务需要密钥验证 |
在 pyVideoTrans 中使用
配置步骤
- 打开
pyVideoTrans软件 - 在菜单栏中,选择 语音识别(R) → 自定义语音识别 API
- 在弹出的配置窗口中填写相关信息
- 点击 "保存",即可开始使用
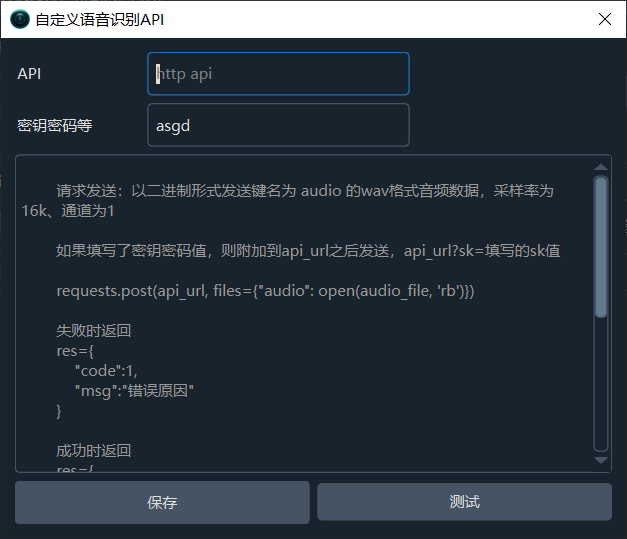
参数说明
| 参数 | 说明 |
|---|---|
| API 地址 | 你的 API 端点地址,必须以 http 开头 |
| API 密钥 | 如有密钥验证,在此填写。密钥会附加在 API 地址后以 ?sk=密钥值 发送 |
API 请求格式
pyVideoTrans 会向你填写的 API 地址发送 POST 请求:
requests.post(api_url, files={"audio": open(audio_file, 'rb')}, data={"language": "2位语言代码"})请求详情:
| 项目 | 说明 |
|---|---|
| 请求方式 | POST |
| 音频数据 | 键名为 audio,WAV 格式,采样率 16kHz,单声道 |
| 语言参数 | 键名为 language,2 位语言代码(如 zh、en) |
| 密钥传递 | 附加在 URL 后:api_url?sk=填写的sk值 |
API 响应格式
你的 API 需要返回 JSON 格式数据。
成功时返回:
{
"code": 0,
"data": "SRT格式的字幕字符串"
}失败时返回:
{
"code": 1,
"msg": "错误原因"
}
data字段可以是 SRT 格式的字符串,也可以是包含time和text字段的数组。
内置服务集成
Gladia 云端识别
当 API 地址包含 api.gladia.io 时,程序会自动切换为 Gladia 集成模式:
- 先将音频上传到 Gladia 服务器
- 然后发起转录请求
- 轮询获取转录结果
- 返回 SRT 格式字幕
使用步骤:
- 在 https://gladia.io/ 注册账号并获取 API Key
- 在 pyVideoTrans 的自定义语音识别 API 设置中:
- API 地址填写:
https://api.gladia.io - API 密钥填写:你的 Gladia API Key
- API 地址填写:
- 保存即可使用
VibeVoice ASR(支持说话人分离)
当 API 密钥中包含 vibevoice-asr 时,程序会自动切换为 VibeVoice ASR 集成模式:
- 使用
gradio_client库连接 VibeVoice 服务 - 自动将长音频按 60 分钟为单位分段处理
- 支持说话人分离功能,识别结果会自动标注说话人标签
- 说话人信息保存到缓存文件夹的
speaker.json文件中
使用步骤:
- 部署并启动 VibeVoice ASR 服务
- 在 pyVideoTrans 的自定义语音识别 API 设置中:
- API 地址填写:VibeVoice 服务的 Gradio 地址(如
http://127.0.0.1:7860) - API 密钥填写:
vibevoice-asr(包含此字符串即可触发特殊模式)
- API 地址填写:VibeVoice 服务的 Gradio 地址(如
- 保存即可使用
最佳配置建议
| 配置项 | 推荐值 | 说明 |
|---|---|---|
| 音频格式 | WAV 16kHz 单声道 | 最佳识别效果,程序会自动转换 |
| API 地址 | 以 http 开头 | 确保地址完整且可访问 |
| 重试机制 | 默认 2 次 | 网络不稳定时自动重试 |
| 语言 | 指定语言 | 比自动检测更准确 |
自建 API 示例
如果你需要自己搭建 API 服务,以下是一个简单的 Flask 示例:
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/recognize', methods=['POST'])
def recognize():
audio_file = request.files['audio']
language = request.form.get('language', 'zh')
# 在这里调用你的语音识别模型
# result = your_model.recognize(audio_file, language)
# 返回 SRT 格式字符串
srt_content = "1\n00:00:00,000 --> 00:00:05,000\n这是识别结果\n"
return jsonify({
"code": 0,
"data": srt_content
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)常见问题
Q:填写地址后提示连接失败?
A:请检查:
- API 地址是否以
http或https开头 - API 服务是否正在运行
- 端口是否正确,防火墙是否放行
Q:返回数据格式不对?
A:确保你的 API 返回的是标准 JSON 格式,且包含 code 和 data(或 msg)字段。参考上方的响应格式说明。
Q:如何使用 Gladia 服务?
A:API 地址填写 https://api.gladia.io,密钥填写你的 Gladia API Key。程序会自动识别并切换到 Gladia 集成模式。详细教程请查看 Gladia 使用教程。
Q:说话人分离不生效?
A:确保 API 密钥中包含 vibevoice-asr 字符串,且 VibeVoice ASR 服务正在运行。说话人分离功能需要服务端支持。
Q:音频识别结果为空?
A:检查音频格式是否为 WAV 16kHz 单声道。虽然程序会尝试自动转换,但建议提前将音频处理为标准格式以获得最佳效果。