GPT-SoVITS API 使用方法
首先升级视频翻译配音工具到 最新版,然后打开 设置菜单-GPT-SoVITS API
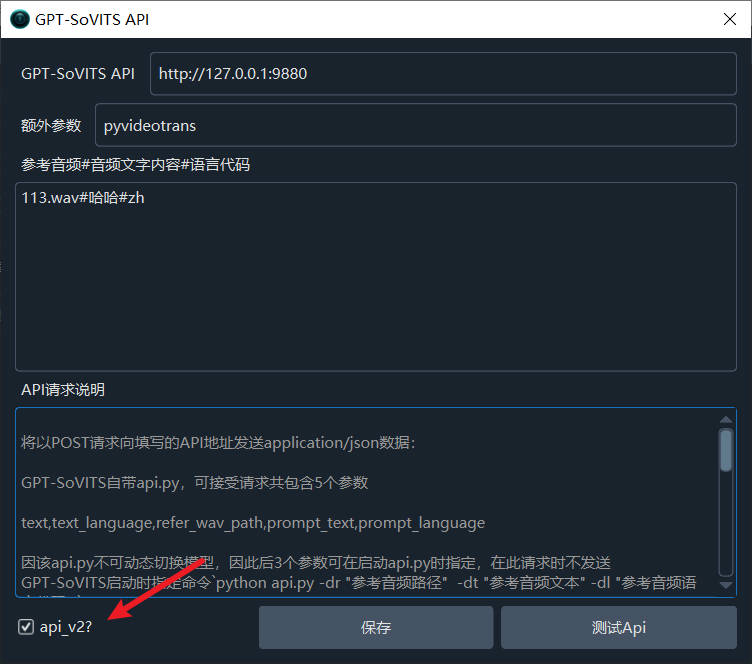
在以下几个文本框中填写相应内容
GPT-SoVITS API: 这里填写 GPT-SoVITS 的 api 地址和端口,自带的 api.py 默认地址是 http://127.0.0.1:9880 , 如果你不是本机部署,ip相应要修改,并允许其他机器访问,如果更改了接口,这里相应也需要修改。
额外参数: 目前暂未用到,主要用于冗余,以方便某些用户希望获取更多信息,比如是什么软件调用的,所以这里加了一个冗余,默认值为 pyvideotrans
参考音频#音频文字内容#语言代码: 这个是最重要的参数,用来决定合成什么音色。
api_v2?:如果你打算使用 api_v2 接口,必须选中该项
如果你在启动GPT-SoVITS的api.py时,已经指定了默认的 “参考音频、音频文字内容、语言代码”,那么这里可以无需指定。比如你执行的是下面类似指定:
python api.py -dr 1.wav -dt "你好啊,我亲爱的朋友们,希望你们的每天都是美好愉快的" -dl zh那么这里无需指定,会直接使用 1.wav 这个音频的音色来复制。
如果你没有指定,或者使用的是api_v2.py,就必须指定参考音频。
接下来重点讲下如何填写参考音频。
参考音频填写格式
每行以符号“#”分为3个部分 参考音频路径#参考音频的文本内容#语言代码
第一部分 是参考音频相对于 GPT-SoVITS 的路径,假如你直接将参考音频 1.wav 放在了 GPT-SoVITS 软件的根目录下,即和api.py在同一目录,那么参考音频填写1.wav,如果你放在了根目录下的audio目录下,那么填写audio/1.wav.
注意哦,参考音频是放在GPT-SoVITS软件目录中的,可不是在视频翻译软件中
第二部分 是音频里的文字内容,即里面的人说的是什么,将文字填写在第二部分。
第三部分 是语言代码,即这个说话人用什么语言说话的,目前只支持中日英语言,代码只可填写zh|en|ja三者之一。
比如我的音频1.wav里的内容是 "你好啊,我亲爱的朋友们,希望你们的每天都是美好愉快的",那么我填写后效果就是
1.wav#你好啊,我亲爱的朋友们,希望你们的每天都是美好愉快的#zh
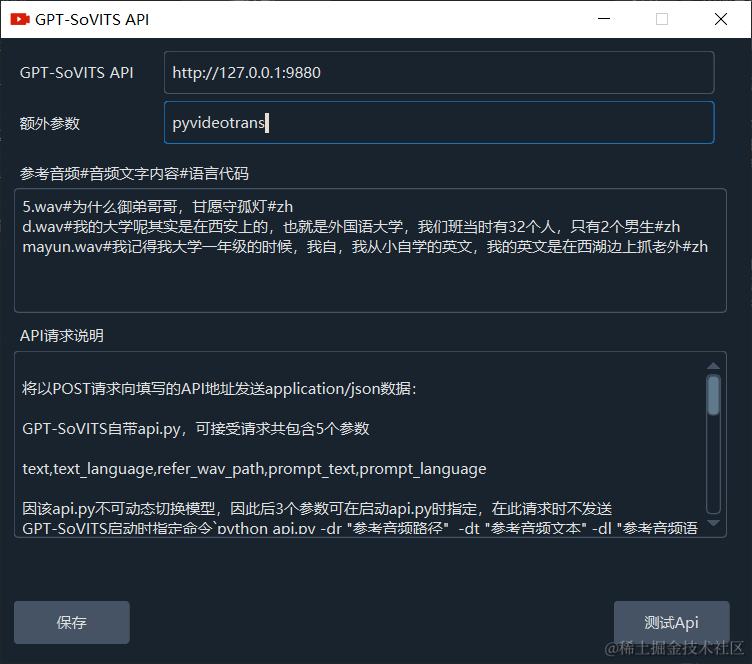
可填写多个,每行一个,如下面示例
5.wav#为什么御弟哥哥,甘愿守孤灯#zh
d.wav#我的大学呢其实是在西安上的,也就是外国语大学,我们班当时有32个人,只有2个男生#zh
mayun.wav#我记得我大学一年级的时候,我自,我从小自学的英文,我的英文是在西湖边上抓老外#zh填写后的整体效果如图
填写后,就可以测试下是否可以了。没问题后去主界面TTS类型里选择“GPT-SoVITS”,角色列表里选择能填写的音频。
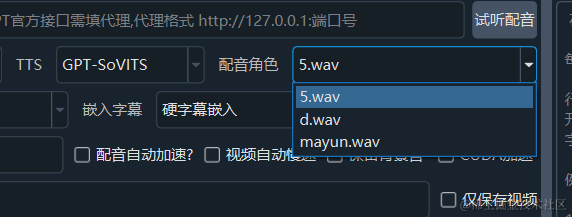
当然前提是必须正确启动 GPT-SoVITS api服务
启动 GPT-SoVITS API服务
启动api.py
如果你是用的Window预打包版,进入GPT-SoVITS根目录后,地址栏输入cmd回车,然后在弹出的窗口中执行命令 .\runtime\python api.py启动等待提示成功。
启动 api_v2.py
python api_v2.py -a 127.0.0.1 -p 9880 -c GPT_SoVITS/configs/tts_infer.yaml
使用 api_v2.py 必须选中底部的
api_v2复选框