中文重新断句功能使用
Whisper 是当前主流的语音识别模型,但在中文识别方面仍有明显不足。相比英文语音识别,Whisper 的中文识别效果差距较大,不仅经常输出繁体字,还缺少标点符号,导致生成的字幕断句效果较差。即便通过返回的字符级时间戳重新断句,若音视频中缺乏明显的静音分割,结果仍不理想。
相对而言,阿里的 FunASR 系列模型在中文识别上表现出色,但它的支持语言范围有限,仅适用于中文,无法处理其他语言。
因此,在 v2.92 中引入了阿里的中文标点恢复模型。这个模型可以在中文识别结果中恢复标点符号,并根据标点和静音区间重新划分句子。由于新增的标点恢复模型,软件体积增加了约 400MB。
启用中文重新断句
在以下条件满足时,将自动使用该阿里中文标点模型对结果进行重新断句:
- 在主界面或音视频转字幕界面勾选“中文重新断句”选项;
- 音视频的发音语言为中文;
- 语音识别引擎选择为 “faster-whisper”、“openai-whisper” 或 “deepgram.com”;
- 分割模式选择为整体识别。
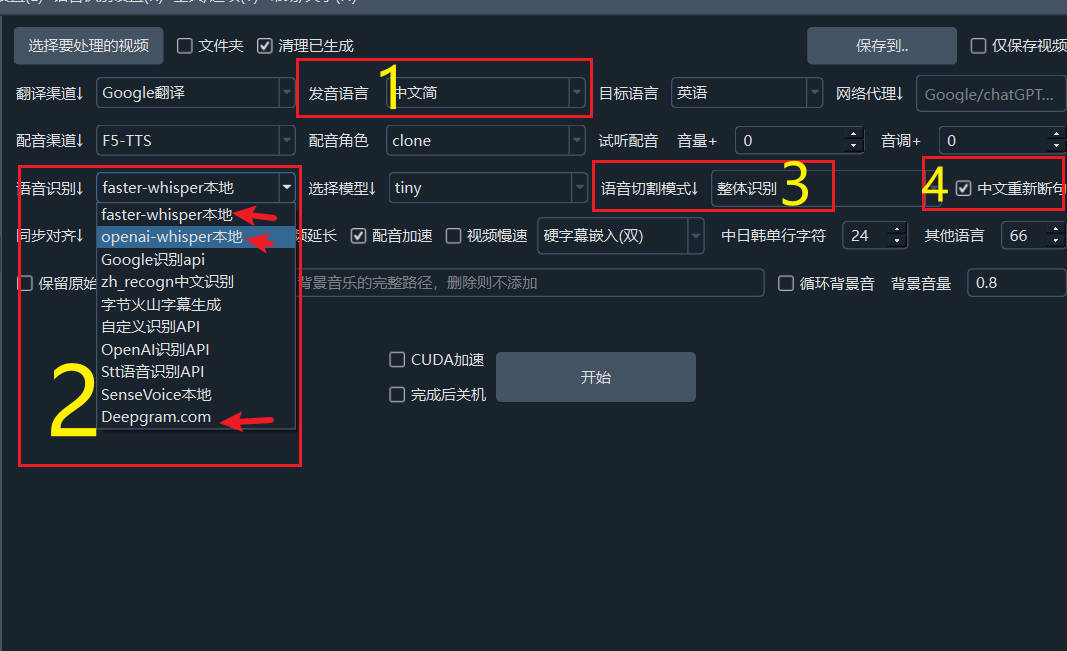
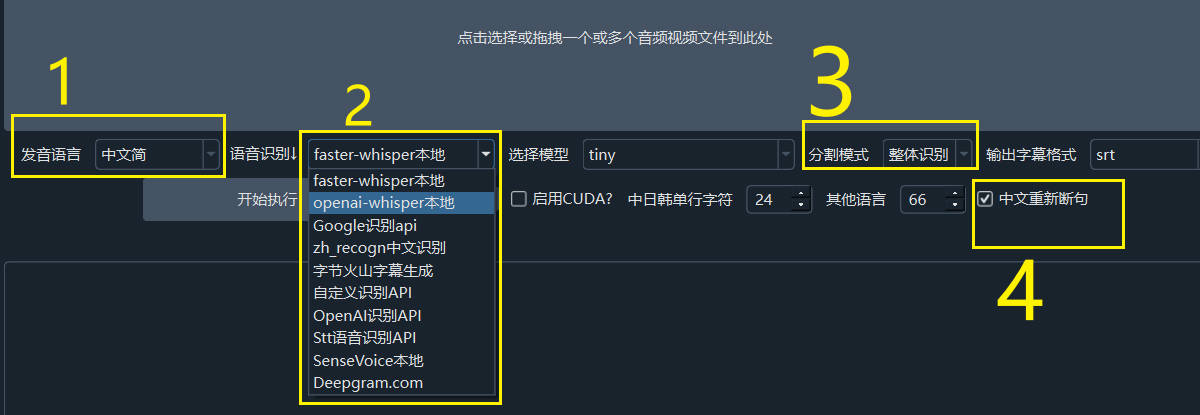
满足以上条件后,系统将在语音识别完成后,先恢复标点符号,再根据标点符号和静音区间重新划分句子,以提升字幕的准确性和可读性。