配音渠道:F5-TTS
F5-TTS 是上海交通大学开源的 TTS 服务,默认支持中英文语音合成和声音克隆。
从 v4.04 版本起,F5-TTS 改为软件内置开箱可用,无需额外部署
除默认中英外,增加日、法、德、俄、意、西班牙、印地、阿拉伯语模型,这些模型均为社区维护(非F5-TTS官方) 更多语言模型地址查看F5-TTS官方分享
模型下载地址
第一次使用时自动下载模型,可能需要很长时间,有可能下载失败,若失败请点击下列地址,将看到的 .pt、.safetensors、.txt 文件下载后放入对应
模型存放文件夹内(若不存在则新建)
模型存放文件夹:
软件sp.exe所在目录/models/models--SWivid--F5-TTS/F5TTS_v1_Base
模型存放文件夹:
软件sp.exe所在目录/models/models--Jmica--F5TTS/JA_21999120
模型存放文件夹:
软件sp.exe所在目录/models/models--RASPIAUDIO--F5-French-MixedSpeakers-reduced
模型存放文件夹:
软件sp.exe所在目录/models/models--hvoss-techfak--F5-TTS-German
模型存放文件夹:
软件sp.exe所在目录/models/models--hotstone228--F5-TTS-Russian
- 意大利语模型(1.35G):https://huggingface.co/alien79/F5-TTS-italian/tree/main
模型存放文件夹:
软件sp.exe所在目录/models/models--alien79--F5-TTS-italian
模型存放文件夹:
软件sp.exe所在目录/models/models--jpgallegoar--F5-Spanish
模型存放文件夹:
软件sp.exe所在目录/models/models--SPRINGLab/F5-Hindi-24KHz
- 阿拉伯语模型(2.6G):https://huggingface.co/silma-ai/silma-tts/tree/main
模型存放文件夹:
软件sp.exe所在目录/models/models--silma-ai--silma-tts
配置参考音频
参考音频统一在菜单 → TTS设置 → 设置参考音频中处理。
操作步骤
- 打开「参考音频」设置界面
- 在「参考音频」文本框中填写以下格式的内容:
音频文件名#该音频文件中对应的文字- 将参考音频文件放置在 pyVideoTrans 项目根目录下的
f5-tts文件夹内(如该文件夹不存在请手动创建)
示例
假设你有一个音频文件 nverguo.wav,音频内容是「女儿国王说话」,则填写:
nverguo.wav#女儿国王说话
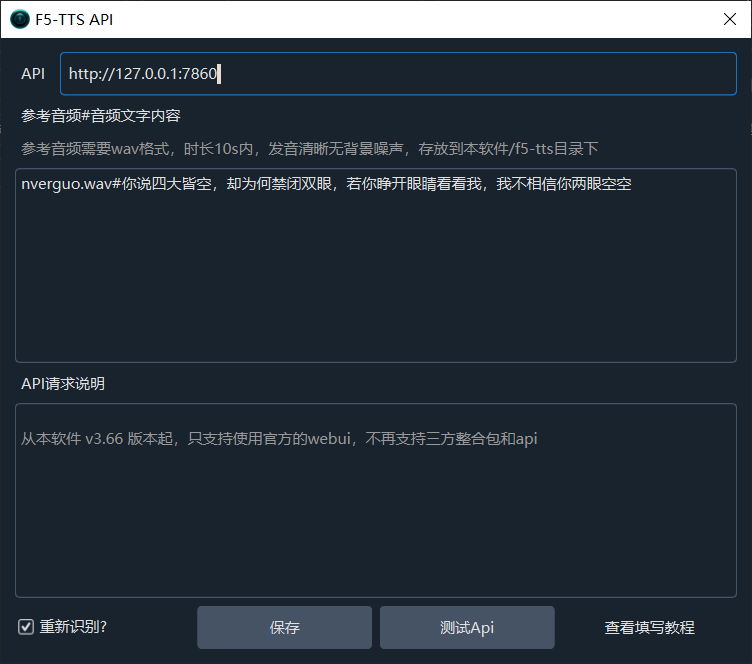
参考音频要求
| 项目 | 要求 |
|---|---|
| 格式 | WAV 格式(推荐),MP3 等格式也可 |
| 时长 | 3~10 秒 |
| 内容 | 发音清晰,无背景噪音 |
| 文字 | 必须与音频内容一致 |