语音识别中的VAD参数调整
在视频翻译的语音识别阶段创建的字幕有时很长,几十秒甚至几分钟,而有时却又很短,不到1秒,这些均可由调节VAD参数进行优化
VAD 是什么
Silero VAD 是一个高效的语音活动检测(VAD)工具,它可以识别音频中是否包含语音,并将语音部分从静音或噪音中分离出来。Silero VAD 可以与其他语音识别库(如 Whisper)结合使用,以便在语音识别之前或之后先行检测和分割语音片段,优化识别效果。

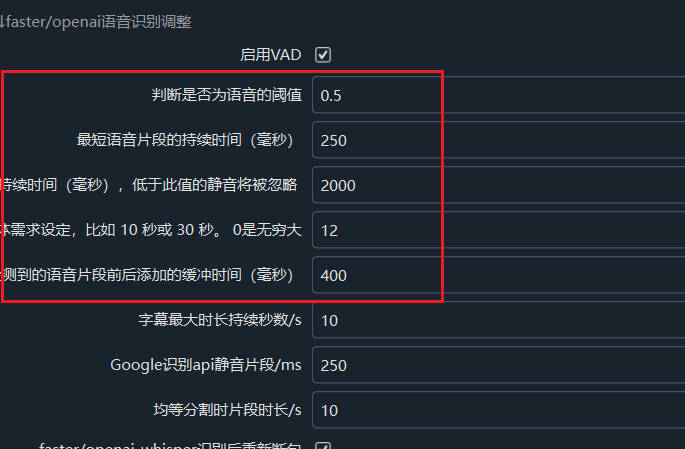
在faster-whisper中默认使用VAD做语音分析与切割,主要涉及到下面四个参数来控制调节切割识别效果。这些参数用于控制语音和静音的判断和切割。下面是对各参数的详细解释和设置建议:
threshold (阈值)
含义: 表示语音的概率阈值,Silero VAD 会输出每个音频片段的语音概率。高于该值的概率被认为是语音(SPEECH),低于该值的概率被认为是静音或背景噪音。
设置建议:默认值为 0.5,这在大多数情况下是适用的。但针对不同的数据集,你可以调整这个值以更精确地区分语音和噪音。如果你发现误判太多,可以尝试将其调高到 0.6 或 0.7;如果语音片段丢失过多,则可以降低至 0.3 或 0.4。
min_speech_duration_ms (最小语音持续时间,单位:毫秒)
含义: 如果检测到的语音片段长度小于这个值,则该语音片段会被丢弃。目的是去除一些短暂的非语音声音或噪音。
设置建议:默认值为 250 毫秒,适合大多数场景。你可以根据需要调整,如果语音片段过短容易被误判为噪音,可以增加该值,例如设置为 500 毫秒。
max_speech_duration_s (最大语音持续时间,单位:秒)
含义: 单个语音片段的最大长度。如果语音片段超过这个时长,则会尝试在 100 毫秒以上的静音处进行分割。如果没有找到静音位置,则会在该时长前强行分割,避免过长的连续片段。
设置建议:默认是无穷大(不限制),如果需要处理较长的语音片段,可以保留默认值;但如果你希望控制片段长度,比如处理对话或分段输出,可以根据具体需求设定,比如 10 秒或 30 秒。
min_silence_duration_ms (最小静音持续时间,单位:毫秒)
含义: 当检测到语音结束后,会等待的静音时间。如果静音持续时间超过该值,才会分割语音片段。
设置建议:默认值是 2000 毫秒(2 秒)。如果你希望更快速地检测和分割语音片段,可以减小这个值,比如设置为 500 毫秒;如果希望更宽松地分割,可以将其增大。
speech_pad_ms (语音填充时间,单位:毫秒)
含义: 在检测到的语音片段前后各添加的填充时间,避免语音片段切割得太紧凑,可能会切掉一些边缘的语音。
设置建议:默认值是 400 毫秒。如果你发现切割后的语音片段有缺失部分,可以增大该值,比如 500 毫秒或 800 毫秒。反之,如果语音片段过长或包含过多的无效部分,可以减少这个值。
这些参数的具体设置需要根据你使用的语音数据集和应用场景进行调优,合理的配置可以显著提升 VAD 的表现。
以上几个参数可在 菜单--工具/选项--高级选项--faster/openai进行修改调整 也可在主界面中语音识别后选择
faster-whisper本地后,点击左侧“语音识别”文字,将在下方显示这几个参数的修改文本框
总结:
threshold:可以根据数据集调整,默认值 0.5 较为通用。
min_speech_duration_ms 和 min_silence_duration_ms:决定了语音片段的长度和静音分割的敏感度,根据应用场景微调。
max_speech_duration_s:防止长语音片段不合理增长,通常要根据具体应用设置。
speech_pad_ms:为语音片段添加缓冲,避免片段被过度切割。具体数值的选择取决于您的音频数据和对语音分割的需求。
声音越干净清晰没有噪声,识别效果越好,再精心调制的参数也不如背景干净的声音效果好