GeminiAI兼容openai
GeminiAI 是一款对开发者非常友好的大模型,它不仅界面美观、功能强大,还提供每日相当高的免费额度,足以满足日常使用需求。
然而,它也存在一些不便之处,例如必须始终科学上网,且 API 与 OpenAI SDK 不兼容。
为了解决这些问题,并实现与 OpenAI 的兼容,我编写了一段 JavaScript 代码,并将其部署到 Cloudflare 上,绑定了自己的域名。这样一来,就可以在国内免科学上网使用 Gemini,同时也能兼容 OpenAI。在任何使用 OpenAI 的工具中,只需简单地替换 API 地址和密钥(SK)即可。
在 Cloudflare 上创建 Worker
如果你还没有 Cloudflare 账号,请先注册一个(免费)。注册地址是:https://dash.cloudflare.com/ 登录后,记得绑定你自己的域名,否则无法实现免代理访问。
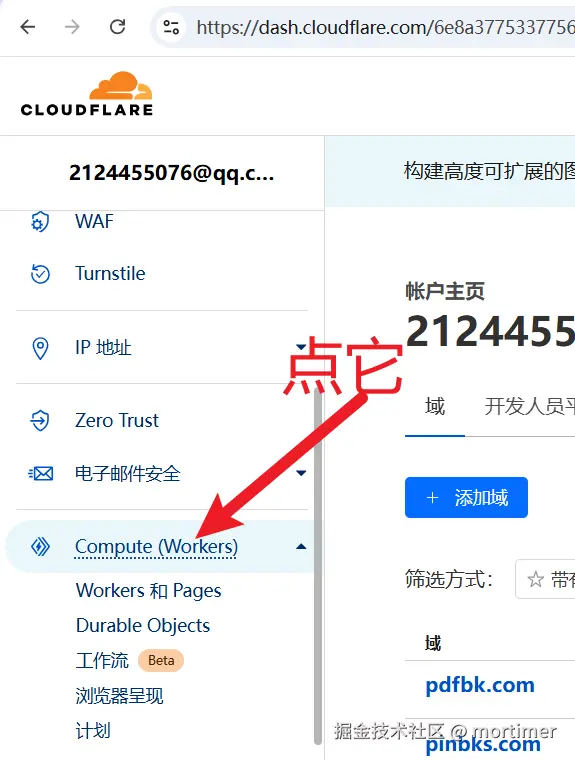
登录后,在左侧边栏找到 Compute (Workers) 并点击,然后单击 创建 按钮。
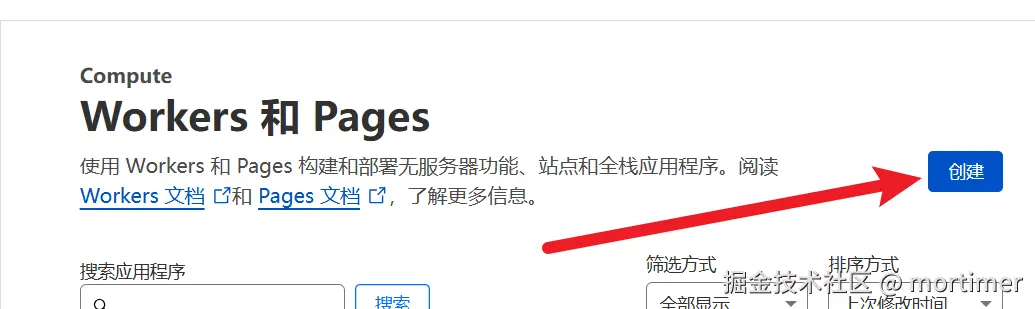
在出现的页面中点击 创建 Worker。
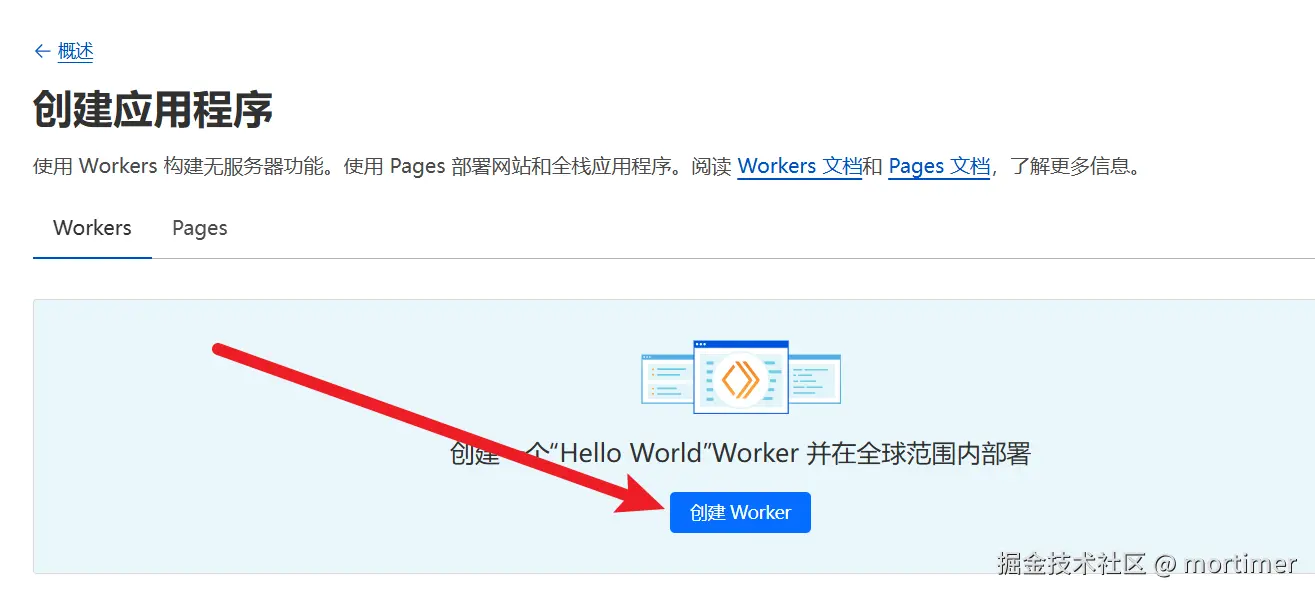
接着点击右下角的 部署,这样就完成了 Worker 的创建。
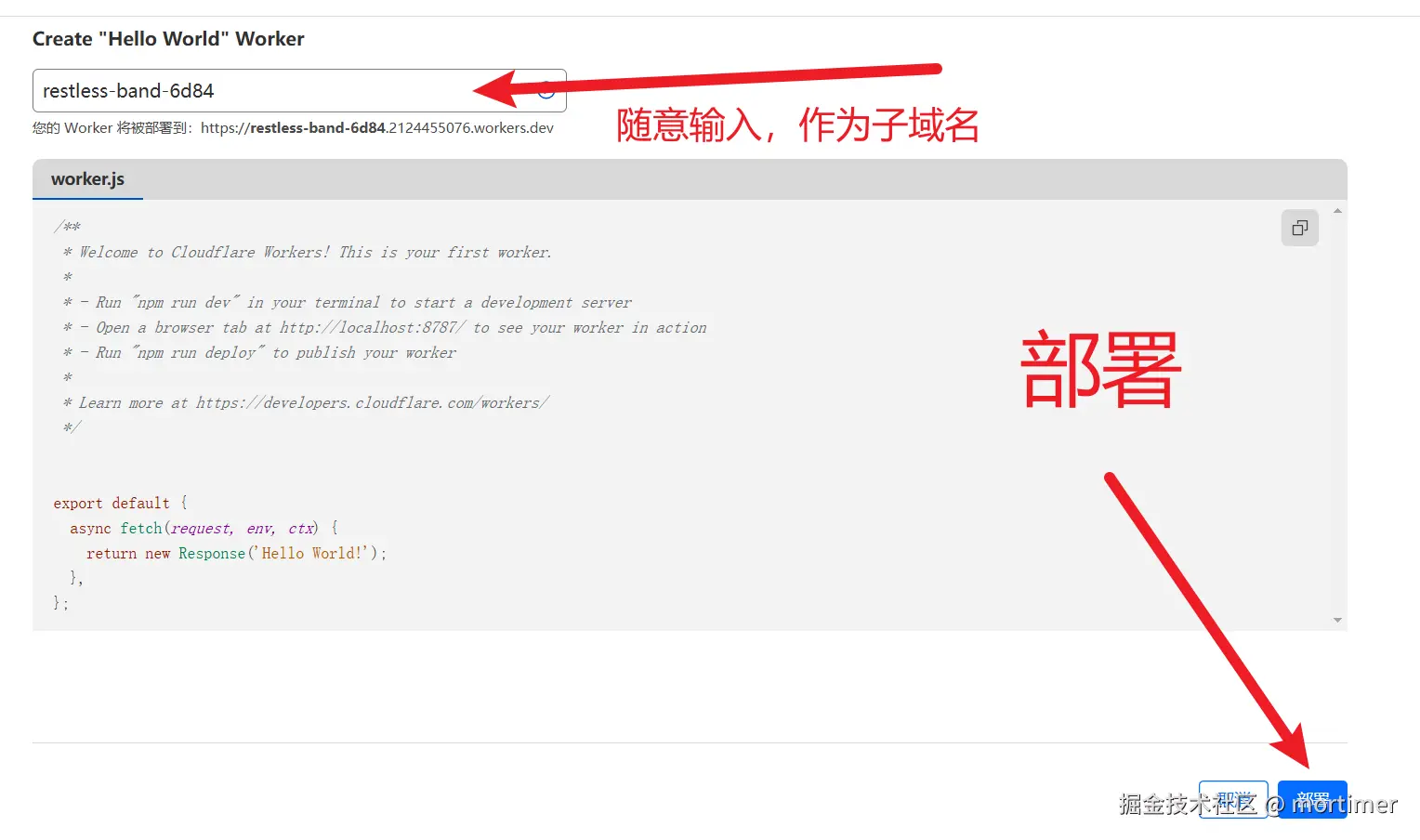
编辑代码
下面的代码是实现兼容 OpenAI 的关键,请复制它并替换 Worker 中默认生成的代码。
在刚才部署完成后的页面中,点击 编辑代码。

删除左侧的所有代码,然后复制下面的代码并粘贴,最后点击右上角的 部署。
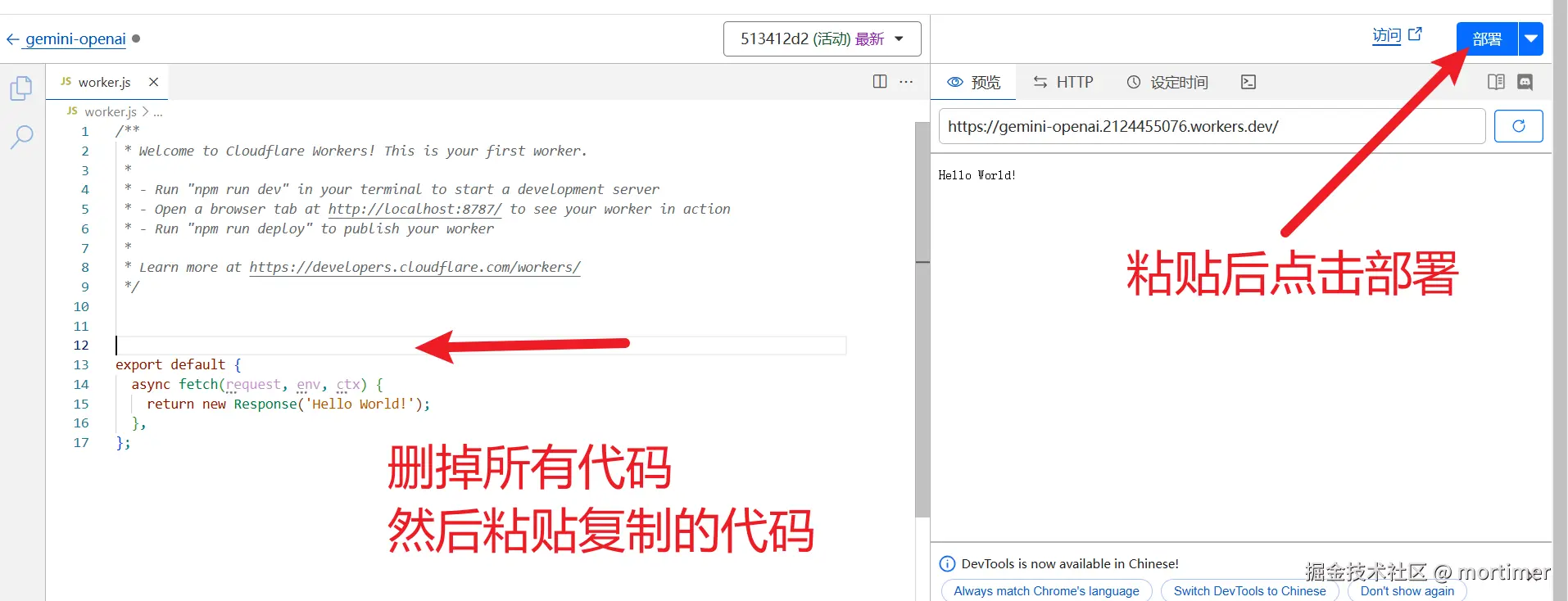
复制以下代码
export default {
async fetch (request) {
if (request.method === "OPTIONS") {
return handleOPTIONS();
}
const errHandler = (err) => {
console.error(err);
return new Response(err.message, fixCors({ status: err.status ?? 500 }));
};
try {
const auth = request.headers.get("Authorization");
const apiKey = auth?.split(" ")[1];
const assert = (success) => {
if (!success) {
throw new HttpError("The specified HTTP method is not allowed for the requested resource", 400);
}
};
const { pathname } = new URL(request.url);
if(!pathname.endsWith("/chat/completions")){
return new Response("hello")
}
assert(request.method === "POST");
return handleCompletions(await request.json(), apiKey).catch(errHandler);
} catch (err) {
return errHandler(err);
}
}
};
class HttpError extends Error {
constructor(message, status) {
super(message);
this.name = this.constructor.name;
this.status = status;
}
}
const fixCors = ({ headers, status, statusText }) => {
headers = new Headers(headers);
headers.set("Access-Control-Allow-Origin", "*");
return { headers, status, statusText };
};
const handleOPTIONS = async () => {
return new Response(null, {
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "*",
"Access-Control-Allow-Headers": "*",
}
});
};
const BASE_URL = "https://generativelanguage.googleapis.com";
const API_VERSION = "v1beta";
// https://github.com/google-gemini/generative-ai-js/blob/cf223ff4a1ee5a2d944c53cddb8976136382bee6/src/requests/request.ts#L71
const API_CLIENT = "genai-js/0.21.0"; // npm view @google/generative-ai version
const makeHeaders = (apiKey, more) => ({
"x-goog-api-client": API_CLIENT,
...(apiKey && { "x-goog-api-key": apiKey }),
...more
});
const DEFAULT_MODEL = "gemini-2.0-flash-exp";
async function handleCompletions (req, apiKey) {
let model = DEFAULT_MODEL;
if(req.model.startsWith("gemini-")) {
model = req.model;
}
const TASK = "generateContent";
let url = `${BASE_URL}/${API_VERSION}/models/${model}:${TASK}`;
const response = await fetch(url, {
method: "POST",
headers: makeHeaders(apiKey, { "Content-Type": "application/json" }),
body: JSON.stringify(await transformRequest(req)), // try
});
let body = response.body;
if (response.ok) {
let id = generateChatcmplId();
body = await response.text();
body = processCompletionsResponse(JSON.parse(body), model, id);
}
return new Response(body, fixCors(response));
}
const harmCategory = [
"HARM_CATEGORY_HATE_SPEECH",
"HARM_CATEGORY_SEXUALLY_EXPLICIT",
"HARM_CATEGORY_DANGEROUS_CONTENT",
"HARM_CATEGORY_HARASSMENT",
"HARM_CATEGORY_CIVIC_INTEGRITY",
];
const safetySettings = harmCategory.map(category => ({
category,
threshold: "BLOCK_NONE",
}));
const fieldsMap = {
stop: "stopSequences",
n: "candidateCount",
max_tokens: "maxOutputTokens",
max_completion_tokens: "maxOutputTokens",
temperature: "temperature",
top_p: "topP",
top_k: "topK",
frequency_penalty: "frequencyPenalty",
presence_penalty: "presencePenalty",
};
const transformConfig = (req) => {
let cfg = {};
for (let key in req) {
const matchedKey = fieldsMap[key];
if (matchedKey) {
cfg[matchedKey] = req[key];
}
}
cfg.responseMimeType = "text/plain";
return cfg;
};
const transformMsg = async ({ role, content }) => {
const parts = [];
if (!Array.isArray(content)) {
parts.push({ text: content });
return { role, parts };
}
for (const item of content) {
switch (item.type) {
case "text":
parts.push({ text: item.text });
break;
case "input_audio":
parts.push({
inlineData: {
mimeType: "audio/" + item.input_audio.format,
data: item.input_audio.data,
}
});
break;
default:
throw new TypeError(`Unknown "content" item type: "${item.type}"`);
}
}
if (content.every(item => item.type === "image_url")) {
parts.push({ text: "" });
}
return { role, parts };
};
const transformMessages = async (messages) => {
if (!messages) { return; }
const contents = [];
let system_instruction;
for (const item of messages) {
if (item.role === "system") {
delete item.role;
system_instruction = await transformMsg(item);
} else {
item.role = item.role === "assistant" ? "model" : "user";
contents.push(await transformMsg(item));
}
}
if (system_instruction && contents.length === 0) {
contents.push({ role: "model", parts: { text: " " } });
}
return { system_instruction, contents };
};
const transformRequest = async (req) => ({
...await transformMessages(req.messages),
safetySettings,
generationConfig: transformConfig(req),
});
const generateChatcmplId = () => {
const characters = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
const randomChar = () => characters[Math.floor(Math.random() * characters.length)];
return "chatcmpl-" + Array.from({ length: 29 }, randomChar).join("");
};
const reasonsMap = {
"STOP": "stop",
"MAX_TOKENS": "length",
"SAFETY": "content_filter",
"RECITATION": "content_filter"
};
const SEP = "\n\n|>";
const transformCandidates = (key, cand) => ({
index: cand.index || 0,
[key]: {
role: "assistant",
content: cand.content?.parts.map(p => p.text).join(SEP) },
logprobs: null,
finish_reason: reasonsMap[cand.finishReason] || cand.finishReason,
});
const transformCandidatesMessage = transformCandidates.bind(null, "message");
const transformCandidatesDelta = transformCandidates.bind(null, "delta");
const transformUsage = (data) => ({
completion_tokens: data.candidatesTokenCount,
prompt_tokens: data.promptTokenCount,
total_tokens: data.totalTokenCount
});
const processCompletionsResponse = (data, model, id) => {
return JSON.stringify({
id,
choices: data.candidates.map(transformCandidatesMessage),
created: Math.floor(Date.now()/1000),
model,
object: "chat.completion",
usage: transformUsage(data.usageMetadata),
});
};绑定域名
部署完成后,会有一个 Cloudflare 提供的二级子域名,但该域名在国内无法正常访问,因此需要绑定你自己的域名才能实现免代理访问。
部署完成后,点击左侧的 返回。

然后找到 设置 -- 域和路由,点击 添加。
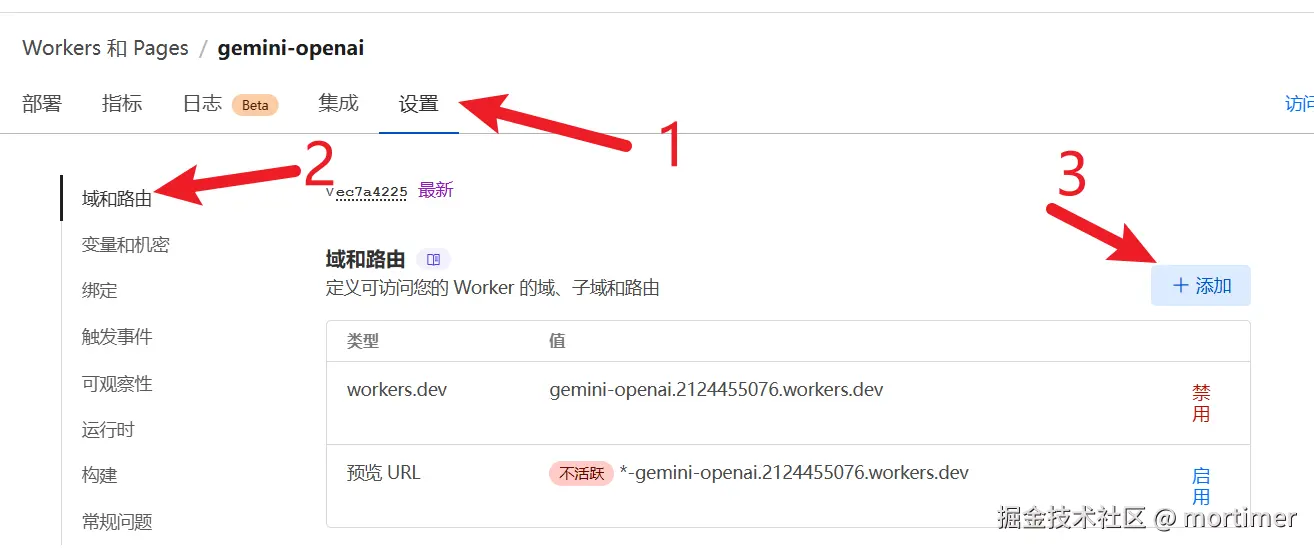
如下图所示,添加你已经托管在 Cloudflare 的域名。
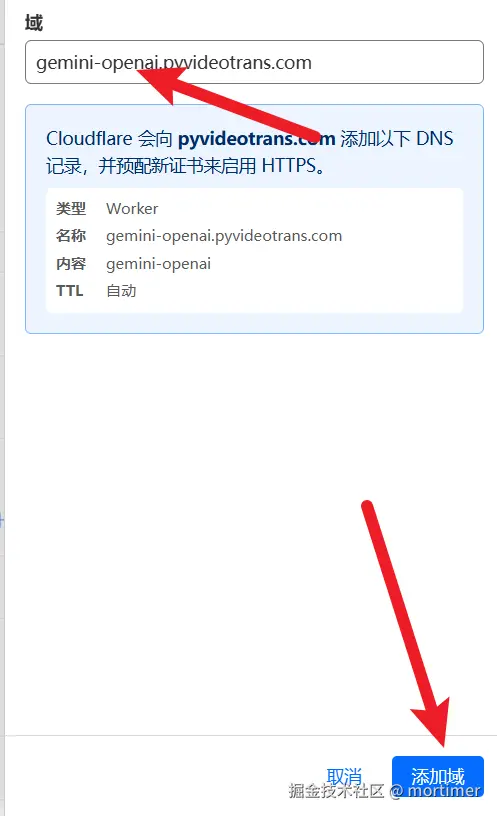
完成后,即可使用该域名访问 Gemini。
使用 OpenAI SDK 访问 Gemini
from openai import OpenAI, APIConnectionError
model = OpenAI(api_key='Gemini的API Key', base_url='https://你的自定义域名.com')
response = model.chat.completions.create(
model='gemini-2.0-flash-exp',
messages=[
{
'role': 'user',
'content': '你是谁'},
]
)
print(response.choices[0])返回如下:
Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='我是一个大型语言模型,由 Google 训练。\n', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None))在其他兼容 OpenAI 的工具中使用
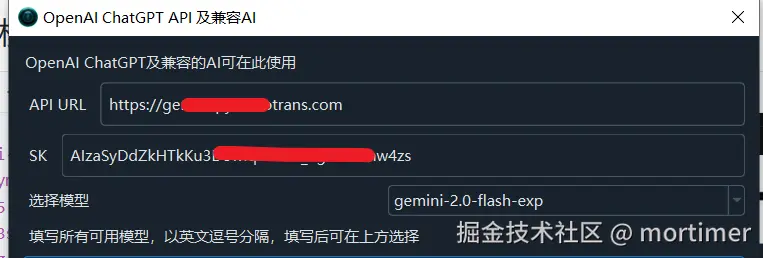
找到该工具配置 OpenAI 信息的位置,将 API 地址改为你在 Cloudflare 中添加的自定义域名,将 SK 改为你的 Gemini API Key,模型填写 gemini-2.0-flash-exp。
直接使用 requests 访问
如果你不使用 OpenAI SDK,也可以直接使用 requests 库进行访问。
import requests
payload={
"model":"gemini-1.5-flash",
"messages":[{
"role":"user",
"content":[{"type":"text","text":"你是谁?"}]
}]
}
res=requests.post('https://xxxx.com/chat/completions',headers={"Authorization":"Bearer 你的Gemini API Key","Content-Type":"application:/json"},json=payload)
print(res.json())输出如下:
