How to Use the GPT-SoVITS API
First, upgrade your video translation and dubbing tool to the [latest version](link to latest version if available), then open the Settings menu and navigate to 'GPT-SoVITS API'.
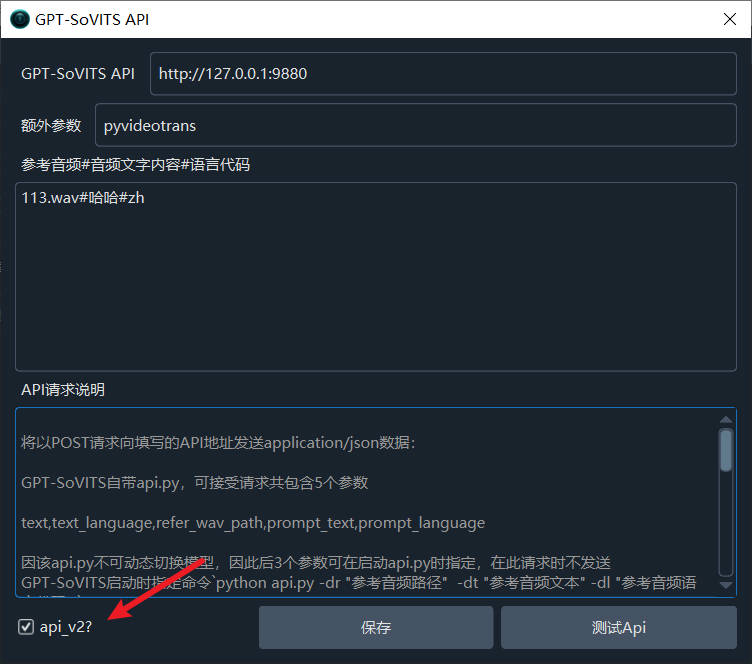
Fill in the corresponding information in the text fields below:
GPT-SoVITS API: Enter the GPT-SoVITS API address and port here. The default address for the included api.py is http://127.0.0.1:9880. If you're not deploying it locally, you'll need to modify the IP address accordingly and allow access from other machines. If you change the port, update it here as well.
Extra Parameters: Currently not in use. This field is mainly for redundancy, allowing users to provide additional information, such as which software is making the call. The default value is pyvideotrans.
Reference Audio#Audio Text Content#Language Code: This is the most crucial parameter, used to determine the synthetic voice's timbre.
api_v2?: If you intend to use the api_v2 interface, you must check this option.
If you have already specified the default "Reference Audio, Audio Text Content, Language Code" when starting GPT-SoVITS's api.py, then you don't need to specify them here. For example, if you executed a command similar to the following:
python api.py -dr 1.wav -dt "你好啊,我亲爱的朋友们,希望你们的每天都是美好愉快的" -dl zhIn that case, no specification is needed here, and the timbre of 1.wav will be directly used for replication.
If you haven't specified it, or if you are using api_v2.py, you must specify the reference audio.
Next, let's focus on how to fill in the reference audio.
Reference Audio Input Format
Each line is divided into 3 parts by the "#" symbol: Reference Audio Path#Reference Audio Text Content#Language Code
Part 1 is the path of the reference audio relative to GPT-SoVITS. For example, if you place 1.wav directly in the root directory of the GPT-SoVITS software (i.e., in the same directory as api.py), then you would enter 1.wav. If it's in the audio subdirectory within the root, you would enter audio/1.wav.
Note: The reference audio files should be placed in the GPT-SoVITS software directory, not in the video translation software's directory.
Part 2 is the text content of the audio, meaning what the person in the audio is saying. Fill this text in the second part.
Part 3 is the language code, indicating which language the speaker is using. Currently, only Chinese, English, and Japanese are supported. The code can only be one of zh|en|ja.
For example, if the content of my 1.wav audio is "你好啊,我亲爱的朋友们,希望你们的每天都是美好愉快的", then after filling it in, it would look like this:
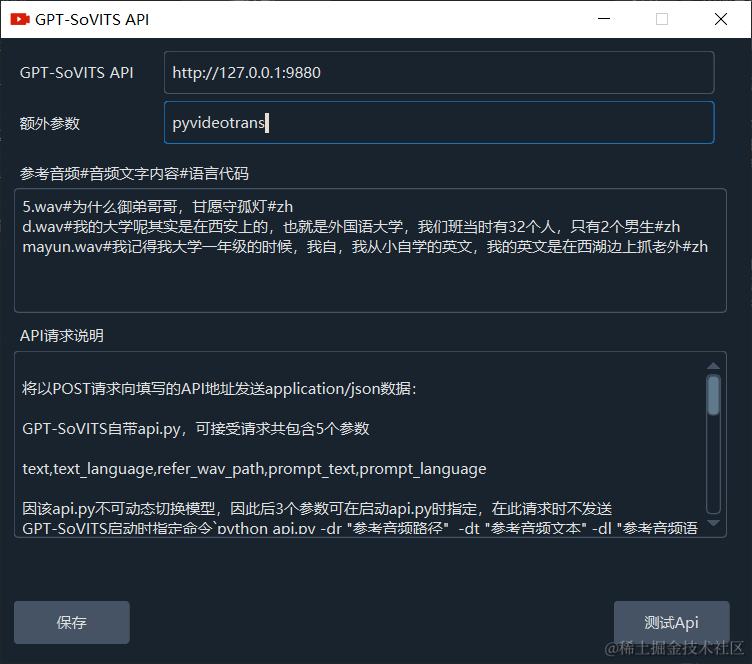
1.wav#你好啊,我亲爱的朋友们,希望你们的每天都是美好愉快的#zhYou can enter multiple entries, one per line, as shown in the example below:
5.wav#为什么御弟哥哥,甘愿守孤灯#zh
d.wav#我的大学呢其实是在西安上的,也就是外国语大学,我们班当时有32个人,只有2个男生#zh
mayun.wav#我记得我大学一年级的时候,我自,我从小自学的英文,我的英文是在西湖边上抓老外#zhThe overall effect after filling in is shown in the image:
After filling it in, you can test if it works. If there are no issues, go to the main interface, select "GPT-SoVITS" under TTS Type, and choose the available audio from the character list.
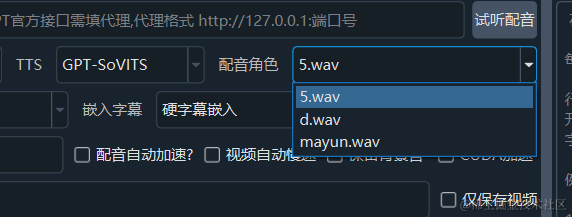
Of course, the prerequisite is that the GPT-SoVITS API service must be running correctly.
Starting the GPT-SoVITS API Service
Starting api.py
If you are using the Windows pre-packaged version, navigate to the GPT-SoVITS root directory, type cmd in the address bar and press Enter. Then, in the popped-up window, execute the command .\runtime\python api.py and wait for the success prompt.
Starting api_v2.py
python api_v2.py -a 127.0.0.1 -p 9880 -c GPT_SoVITS/configs/tts_infer.yaml
When using
api_v2.py, you must check theapi_v2checkbox at the bottom.