pyVideoTrans FAQ and Solutions
To help you better use pyVideoTrans, we have compiled the following common questions and their solutions.
There are many links in Menu Bar -- Help/About, such as model download addresses, CUDA configuration, etc. Try clicking them when encountering problems.
Part 1: Installation and Startup Issues
1. After double-clicking sp.exe, the software won't open or takes a long time to respond?
This is usually normal, please do not worry.
- Reason: This software is based on
PySide6. The main interface contains many components, and initialization takes time during the first load. Depending on your computer's performance, the startup time may range from 5 seconds to 2 minutes. - Solution:
- Wait patiently: Please wait for a while after double-clicking.
- Check security software: Some antivirus software or security guards may block the program startup. Please try temporarily closing them or adding this software to the trust/whitelist.
- Check file path: Ensure the path where the software is stored only contains English letters and numbers, and does not contain Chinese characters, spaces, or special symbols. For example,
D:\pyVideoTransis a good path, whileD:\program file\Video Toolsmay cause problems. - Upgrade package issue: If you cannot start after overwriting with an upgrade package, it indicates an operation error. Please re-download the full software package, unzip it, and then overwrite it with the new upgrade package.
2. What to do if prompted for missing python310.dll at startup?
This issue indicates that you only downloaded the upgrade patch package, not the main program.
- Solution:
- Please go to the official website to download the Full Software Package.
- Unzip the full package to a specified directory.
- Then download the latest upgrade patch package and overwrite it into the full package's directory.
3. Does the software need to be installed?
This software is a portable version and does not need installation. After downloading the full package and unzipping it, double-click sp.exe to run it directly.
4. Why does antivirus software report a virus or block it?
- Reason: This software is packaged using
PyInstallerand does not have commercial digital signature certification. Some security software will trigger risk warnings based on this, which is a common false positive. - Solution:
- Add to trust: Add this software to your antivirus software's trust zone or whitelist.
- Run from source: If you are a developer, you can also choose to deploy and run directly from the source code to completely avoid this issue.
5. Does the software support Windows 7?
No. Many core components depended on by the software no longer support Windows 7.
Part 2: Core Functions and Settings
6. How to improve speech recognition accuracy?
Recognition accuracy mainly depends on the model size you choose.
- Model Selection: In "faster" or "openai" mode, the larger the model, the higher the accuracy, but the slower the processing speed and the greater the resource consumption.
tiny: Smallest size, fastest speed, but lower accuracy.base/small/medium: Performance and resource consumption are balanced; these are commonly used options.large-v3: Largest size, best effect, highest hardware requirements.
- Optimization Settings: Click
Menu -- Tools -- Advanced Options.
Find the faster/openai speech recognition adjustment section and make the following changes:
- **Voice Threshold** set to `0.5`
- **Min Duration/ms** set to `0`
- **Max Voice Duration/sec** set to `5`
- **Silence Split ms** set to `140`
- **Voice Padding** set to `0`
- Model Download: All models can be downloaded from the official website: pyvideotrans.com/model
7. Why has the video clarity/quality decreased after processing?
Any operation involving re-encoding will inevitably lead to video quality loss. If you wish to maintain the original image quality as much as possible, please ensure the following conditions are met:
- Original Video Format: Use H.264 (libx264) encoded MP4 files which have the best compatibility.
- Disable Slow Processing: In the function options, do not check "Video Auto Slow".
- No Hard Subtitles: Choose not to embed subtitles, or only embed soft subtitles. Hard subtitles force the entire video to be re-encoded.
- No Audio or Duration Changes: Do not perform dubbing, or if dubbing, disable the video end extension feature.
- Advanced Options - Video Output Quality Control: The default number is 23. You can lower it to 18 or lower (minimum 0). The lower the number, the higher the output video quality, but the file size will also be larger.
- Advanced Options - Output Video Compression Rate: Default is
fast. You can selectsloworslower; the quality will be higher, but output time will increase. - Advanced Options - 264/265 Encoding: Default is
264. Select265for higher output video quality.
8. Why is the output video huge?
- Modify Advanced Options - Video Output Quality Control to 25-51. The larger the number, the smaller the output video size, but the quality decreases accordingly.
- Advanced Options - 264/265 Encoding: Select 265. At the same quality, 265 has a smaller size.
9. How to configure a network proxy?
Some translation or dubbing services (such as Google, OpenAI, Gemini) cannot be accessed directly in some regions and require a network proxy.
- Setting Method: In the "Network Proxy Address" text box on the main interface, fill in your proxy service address.
- Format Requirement: Usually in the format of
http://127.0.0.1:10808orsocks5://127.0.0.1:10808(the port number depends on your proxy client settings). - Important Note: If you do not understand proxies or do not have an available proxy service, please leave this blank. Incorrect settings will cause all network functions (including domestic services) to fail.
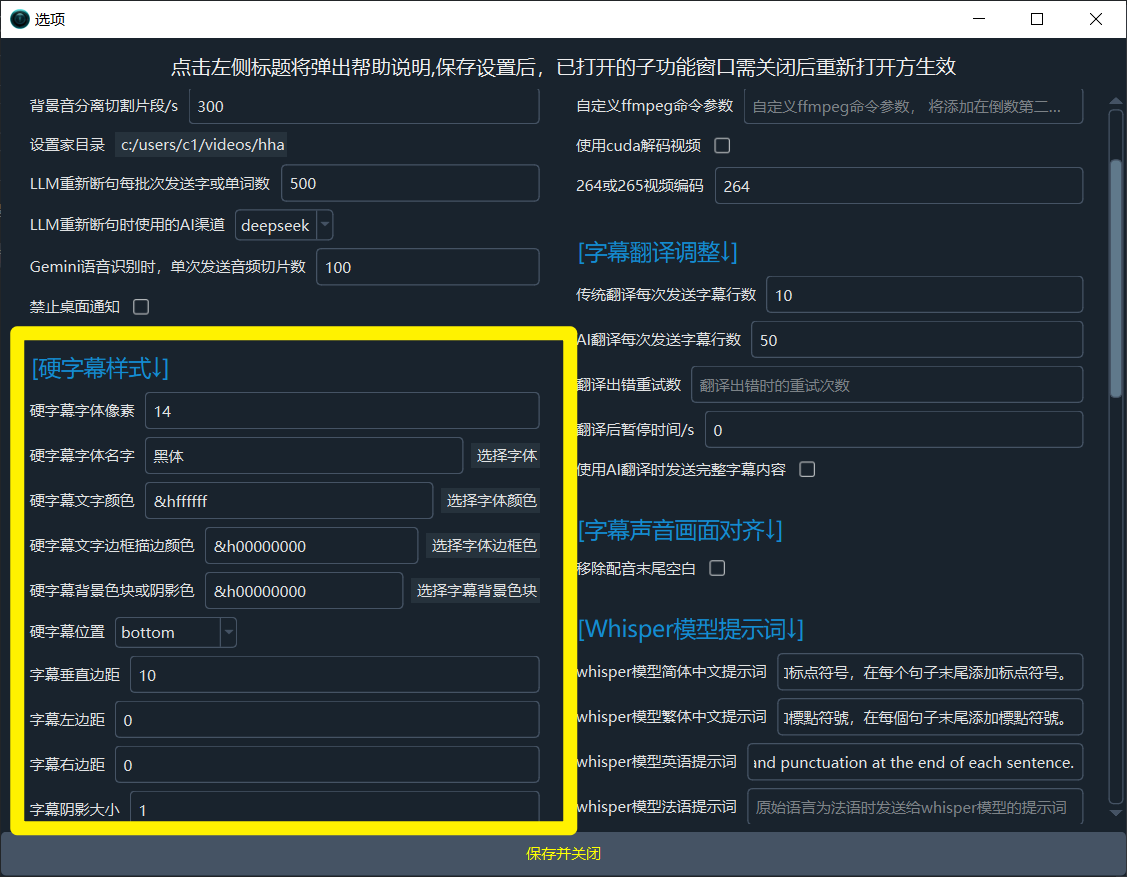
10. How to customize subtitle font, color, and style?
- Click Modify Hard Subtitles on the main interface.
- Here you can modify the font, size, color, border style, etc., of the hard subtitles.
- Color Code Explanation: The color code format is
&HBBGGRR&, which is the reverse of common RGB, ordered as Blue Green Red (BGR).- White:
&HFFFFFF& - Black:
&H000000& - Pure Red:
&H0000FF& - Pure Green:
&H00FF00& - Pure Blue:
&HFF0000&
- White:
Part 3: Common Problems and Troubleshooting
10. Batch translating videos, e.g., 30-50-100 videos, always gets stuck?
By default, batch tasks split each task into multiple stages and process them in parallel. Too many tasks may lead to resource exhaustion. You can select Advanced Options -- Force Serial Execution in Batch to change the execution mode to serial. This means the second video will only start executing after the first video is completely finished, proceeding sequentially.
11. Why are sound, subtitles, and video out of sync after processing?
This is a normal phenomenon in language translation.
- Reason: When different languages express the same meaning, the sentence length and pronunciation duration change. For example, a 2-second Chinese sentence might become 4 seconds when translated into English. This duration change causes the dubbing to not align perfectly with the original lip movements and timeline.
12. Always prompting insufficient VRAM (e.g., Unable to allocate error)?
This error means your graphics card does not have enough memory (VRAM) to perform the current task, usually because a large model is used or a long video is being processed.
- Solution (Try in recommended order):
- Use a smaller model: Change the recognition model from
large-v3tomedium,small, orbase. Thelarge-v3model requires a minimum of 8GB VRAM, but in practice, other programs also consume VRAM. - Adjust Advanced Settings: Make the following changes in
Menu Bar -> Tools/Options -> Advanced Optionsto sacrifice some precision for lower VRAM usage:CUDA Data Type: Changefloat32tofloat16orint8.beam_size: Change5to1.best_of: Change5to1.Context: Changetruetofalse.
- Select
Batch Inferencein the general recognition dropdown box. This will pre-slice the audio into small segments and then execute multiple segments simultaneously.
- Use a smaller model: Change the recognition model from
13. CUDA is installed, why can't the software use GPU acceleration?
Please check the following possible reasons:
- Incompatible CUDA Version: The built-in CUDA support version for this software is 12.8. If your CUDA version is too low, it cannot be invoked.
- Graphics Driver Outdated: Please update your NVIDIA graphics driver to the latest version.
- Missing cuDNN: Ensure you have correctly installed cuDNN matching your CUDA version.
- Hardware Incompatibility: GPU acceleration only supports NVIDIA graphics cards (N-cards). AMD or Intel graphics cards cannot use CUDA.
14. Error during execution containing "ffprobe exec error" or ffmpeg?
This error is usually related to file paths being too long or containing special symbols.
- Reason: Windows systems have a maximum length limit for file paths (usually 260 characters). If your video filename is very long (e.g., videos downloaded from YouTube) and the folder hierarchy is deep, the total path can easily exceed the limit.
- Solution: Move the video file to a shallower directory (e.g.,
D:\videos) and rename it to a short English or numeric name.
15. Software prompts video "contains no audio track"?
- Possible Reason 1: The video indeed has no sound. For example, videos downloaded from YouTube and certain other websites may have separate video and audio streams, and errors during merging can result in lost audio.
- Possible Reason 2: Background noise is too loud. If the video environment is very noisy (e.g., streets, concerts) and human voices are masked, the model may not recognize valid speech.
- Possible Reason 3: Wrong language selection. Please ensure the language selected in the "Original Speech" option matches the actual language spoken by the people in the video. For example, if the video is an English conversation, you must select "English" to recognize it correctly.
16. Is low GPU usage normal?
Normal. The software workflow is: Speech Recognition -> Text Translation -> Text Dubbing -> Video Synthesis.
Only in the first step, "Speech Recognition", is the GPU heavily used for calculation. Other stages (such as translation, synthesis) mainly rely on the CPU, so it is expected that the GPU is under low load for most of the time.
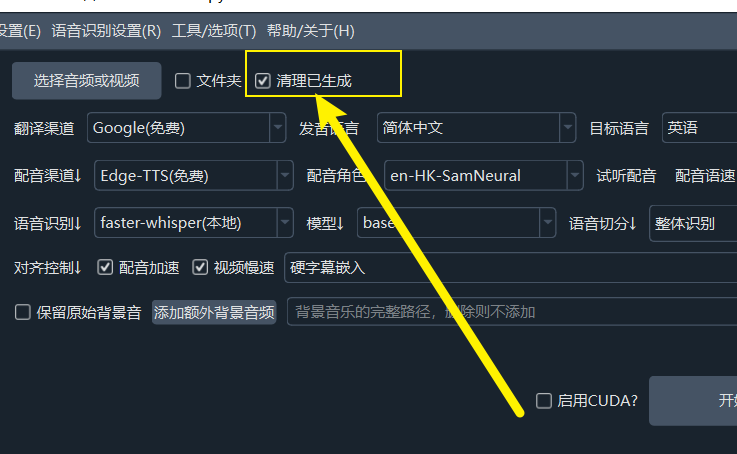
17. Repeatedly processing the same video, why do recognition results and subtitles remain unchanged?
- Reason: To save time and computing resources, the software enables a caching mechanism by default. If it detects that a subtitle file has already been generated for a video, it will directly use the cached result without re-processing.
- Solution: If you wish to force re-recognition and translation, please check the
Clear Generatedcheckbox in the upper left corner of the main interface.
18. Hard drive space full after processing a few videos?
This is usually due to enabling the "Video Slow" feature, which generates a large number of temporary files.
- Reason: This function cuts the video into many small fragments based on subtitles and processes each fragment, which generates cache files far exceeding the volume of the original video.
- Solution:
- Manual Cleanup: After processing is complete, you can manually delete all contents in the
tmpfolder under the software root directory. - Auto Cleanup: When the software is closed normally, the program will automatically clean up these caches.
- Manual Cleanup: After processing is complete, you can manually delete all contents in the
Part 4: General Information
18. Does the software support Docker deployment?
Currently Not Supported.
19. Can it recognize hard subtitles in the video frame (OCR function)?
No. The principle of this software is to analyze the audio track in the video, identify human speech, and convert it into text. It does not have image text recognition (OCR) capabilities.
20. Can I add new language support?
No. Adding a language means requiring support from corresponding speech recognition channels, subtitle translation channels, and dubbing channels. Each channel corresponds to multiple different local models or online API interfaces. Whether they support the new language, and even if supported, different methods require different format codes for the same language (e.g., Chinese requires zh for some channels, while others require zh-cn or chi, etc.). Arbitrarily adding languages will lead to various unexpected errors. Unless you can code and modify the source code yourself, you cannot add languages.
21. Is the software free? Can it be used commercially?
- Cost: This project is free and open source software; you can use all functions for free. Please note that if you use third-party translation or TTS (Text-to-Speech) or speech transcription interfaces, these service providers may charge fees, but this is unrelated to this software.
- Commercial Use: Individuals and companies are free to use this software. However, if you wish to integrate the code of this project into your own commercial product, you must abide by the GPL-v3 Open Source License. In addition, models or online APIs used by certain channels may have their own protocol requirements. regarding whether commercial use is allowed, please consult the platform corresponding to the channel used. For example, consult Microsoft for Edge-tts channels, and consult
https://github.com/2noise/ChatTTSfor ChatTTS dubbing channels.
22. Is human customer service provided?
No. This project is a free open-source software developed by an individual with no profit, so it is impossible to staff a dedicated human customer service team. If you encounter problems, please read this FAQ carefully first. Alternatively, you can choose to scan the WeChat QR code in the lower right corner of the software to donate, leave your WeChat ID, and obtain paid technical support.
23. Where to download software and models?
- Software Download Address: pyvideotrans.com/downpackage
- Source Code Repository: github.com/jianchang512/pyvideotrans