Improving the Quality of AI-Translated Subtitles
When using AI to translate SRT subtitles, there are generally two approaches.
Method 1: Full Translation with Subtitle Format, Including Non-Translatable Elements Like "Line Numbers" and "Timestamp Rows."
How to enable: In the software, select Send Complete Subtitles.
Example below: Send the full content with formatting.
1
00:00:01,950 --> 00:00:04,950
Organic molecules have been discovered in the Five Old Star System.
2
00:00:04,950 --> 00:00:07,902
How far are we from third-type contact?
3
00:00:07,902 --> 00:00:11,958
It has been a year since the microwave imaging mission began.Advantages: Considers context, resulting in better translation quality.
Disadvantages: Besides wasting tokens, it may cause subtitle formatting errors in the translation, making the result no longer a valid SRT subtitle format. For example, English punctuation marks ,: may be incorrectly changed to Chinese punctuation, or line numbers and timestamps may be merged into one line.
Method 2: Send Only the Subtitle Text Content, Then Replace the Corresponding Text in the Original Subtitles with the Translation.
How to enable: In the software, deselect Send Complete Subtitles.
Example format: Only send the subtitle text.
Organic molecules have been discovered in the Five Old Star System.
How far are we from third-type contact?
It has been a year since the microwave imaging mission began.Advantages: Ensures the translation result is always a valid SRT subtitle format.
Disadvantages: Also obvious. Translating line by line cannot account for context, significantly reducing translation quality.
To address this, the software supports translating multiple lines at once, defaulting to 15 lines of subtitles, which can partially account for context.
However, this introduces a new issue: Different languages have different grammar rules and sentence structures, which may cause the original 15 lines to become 14, 13, etc., especially when the preceding and following lines are part of the same sentence grammatically.

When the translated result does not have the same number of lines as the original subtitles, it will definitely cause subtitle confusion. To solve this, if the line count of the translation does not match the original, the software will re-translate line by line to ensure the line count is exactly the same, sacrificing context consideration.
Note: The issues mentioned in the first method may occur, resulting in an invalid SRT subtitle format, potentially causing parsing errors or loss of all content after the error. It is recommended to use this method only with sufficiently intelligent models, such as GPT-4o-mini or larger models. If using a locally deployed model, this method is not recommended. Due to hardware limitations, locally deployed models are generally small, less intelligent, and more prone to formatting errors in translation results.
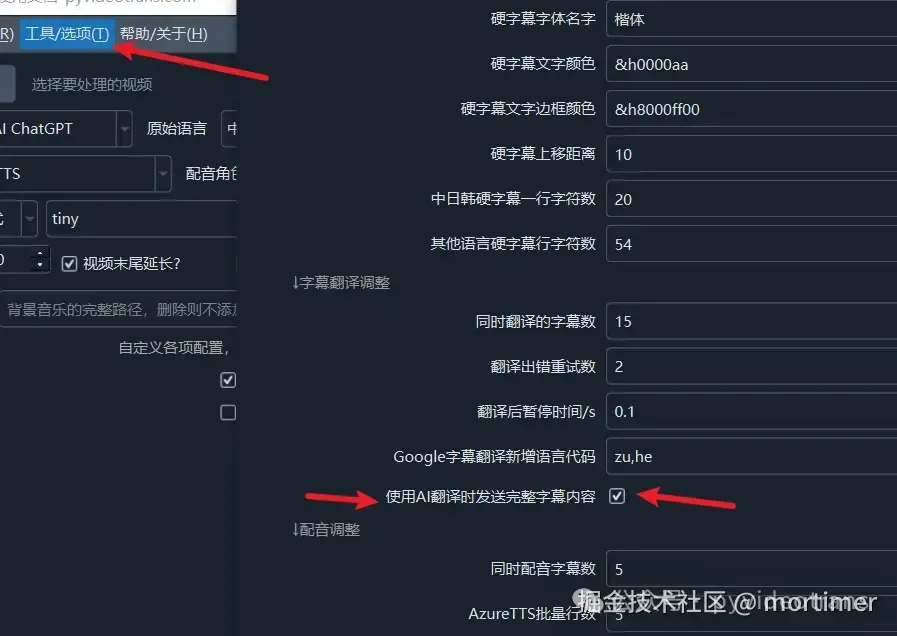
Enabling the First Translation Method:
Menu → Tools/Options → Advanced Options → Subtitle Translation Area → Send Complete Subtitles During AI Translation
Adding a Glossary
You can add your own glossary in each prompt, similar to the example below.
**During translation, be sure to use** the glossary I provide for translating terms to maintain consistency. The specific glossary is as follows:
* Transformer -> Transformer
* Token -> Token
* LLM/Large Language Model -> Large Language Model
* Generative AI -> Generative AI
* One Health -> One Health
* Radiomics -> Radiomics
* OHHLEP -> OHHLEP
* STEM -> STEM
* SHAPE -> SHAPE
* Single-cell transcriptomics -> Single-cell Transcriptomics
* Spatial transcriptomics -> Spatial Transcriptomics