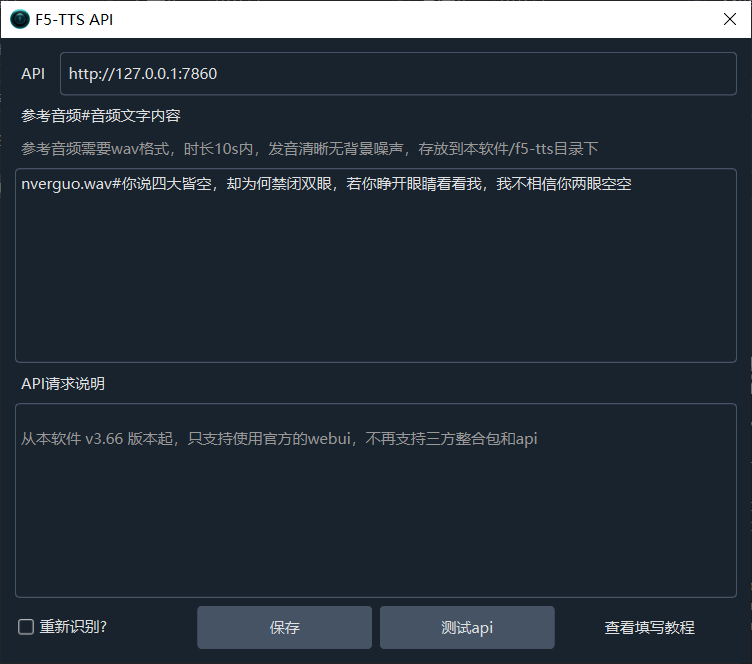
Starting from v3.68, you can directly select Spark-TTS in the software under TTS -> F5-TTS Configuration, without needing to modify the Spark-TTS source code as described at the end of this article.
Spark-TTS is a recently popular open-source voice cloning project jointly developed by multiple universities, including the Hong Kong University of Science and Technology, Northwestern Polytechnical University, and Shanghai Jiao Tong University. Local tests show that its performance is comparable to F5-TTS.
Spark-TTS supports Chinese and English voice cloning, and the installation process is not complicated. This article provides a detailed guide on how to install and deploy it, and make modifications to ensure compatibility with the F5-TTS API interface, allowing it to be used directly in the F5-TTS dubbing channel of the pyVideoTrans software.
Prerequisites: Ensure you have Python 3.10, 3.11, or 3.12 installed.
If not installed, please refer to the previous article for installation instructions.
1. Download Spark-TTS Source Code
First, create a folder named with English letters or numbers on a non-system drive, such as D:/spark. Using a non-system drive and avoiding Chinese characters helps prevent potential errors related to permissions or encoding.
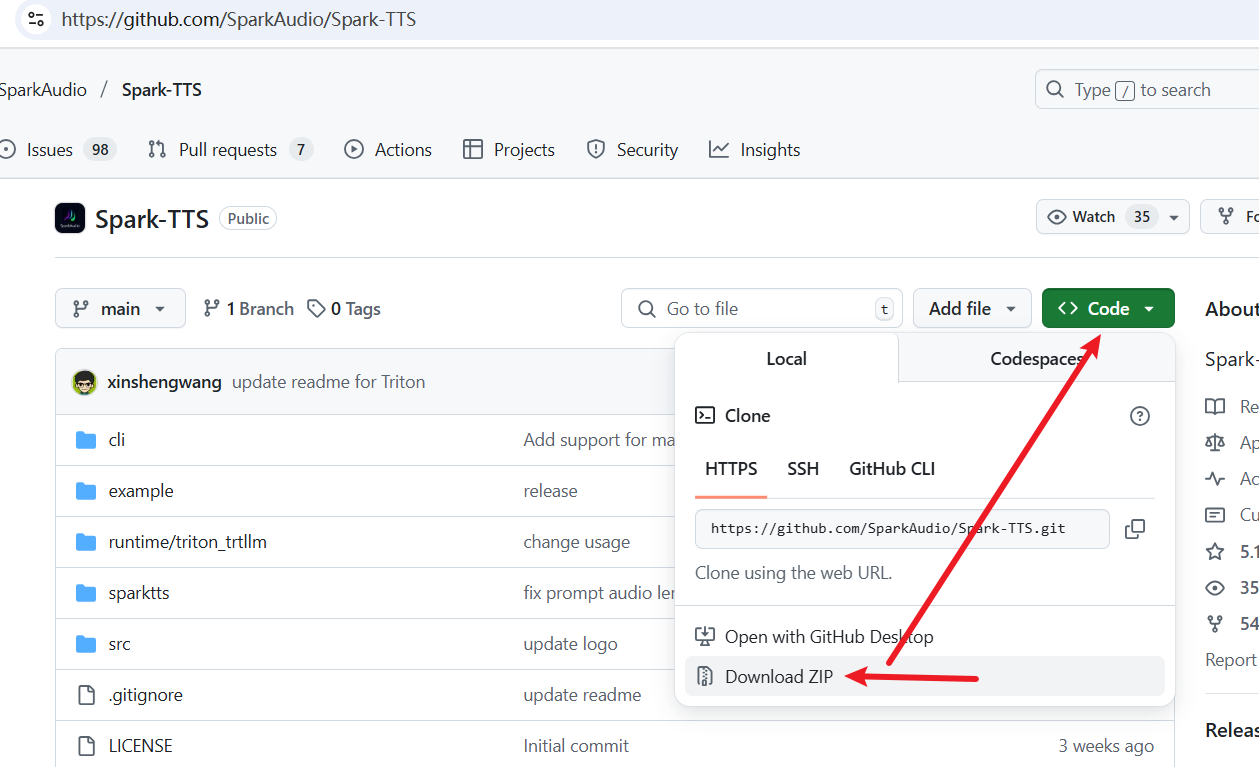
Then, visit the official Spark-TTS code repository: https://github.com/SparkAudio/Spark-TTS
As shown below, click to download the source code ZIP file:
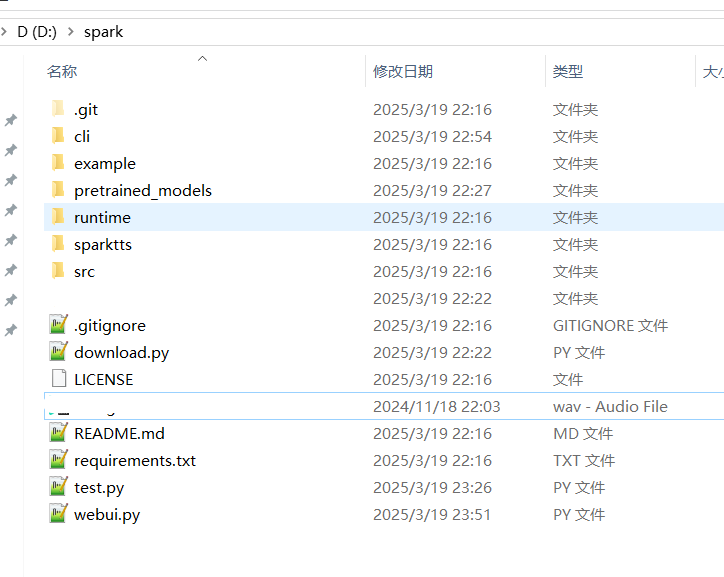
After downloading, extract the contents and copy all files and folders into the D:/spark directory. The resulting directory structure should look like this:
2. Create a Virtual Environment and Install Dependencies
- Create a Virtual Environment
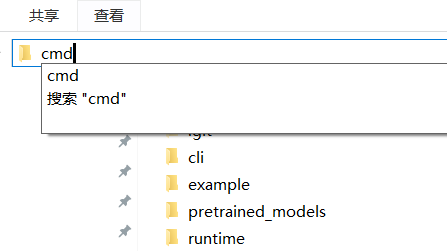
In the folder's address bar, type cmd and press Enter. In the opened terminal window, execute the following command:
python -m venv venvAs shown:
After execution, a venv folder will appear in the D:/spark directory:
Note: If you see an error like
python is not recognized as an internal or external command, it means Python is not installed or not added to the system environment variables. Please refer to the relevant article to install Python.
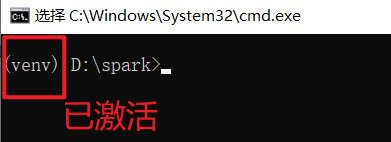
Next, execute venv\scripts\activate to activate the virtual environment. Once activated, (venv) will appear at the beginning of the terminal line, indicating success. All subsequent commands must be executed in this environment, so always check if it's activated.
- Install Dependencies
In the activated virtual environment, continue executing the following command in the terminal to install all dependencies:
pip install -r requirements.txtThe installation may take some time, so please be patient.
3. Download the Model
Open-source AI project models are often hosted on Hugging Face (huggingface.co). Since this site is blocked in some regions, you may need a VPN to download the model. Ensure your VPN is properly configured and system proxy is set.
In the current directory D:/spark, create a text file named down.txt, copy and paste the following code into it, and save:
from huggingface_hub import snapshot_download
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
print('Download complete')Then, in the activated virtual environment terminal, execute the following command:
python down.txtMake sure (venv) appears at the beginning of the command line:

Wait for the terminal to indicate the download is complete.
If you see an output like the following, it indicates a network connection error, possibly due to incorrect VPN configuration:
Returning existing local_dir `pretrained_models\Spark-TTS-0.5B` as remote repo cannot be accessed in `snapshot_download` ((MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/SparkAudio/Spark-TTS-0.5B/revision/main (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x000001BC4C8A4430>, 'Connection to huggingface.co timed out. (connect timeout=None)'))"), '(Request ID: aa61d1fb-ffc7-4479-9a99-2258c1bc0aee)')).
4. Launch the Web Interface
After the model is downloaded, you can start and open the web interface.
In the activated virtual environment terminal, execute the following command:
python webui.py
Wait until you see the following message, indicating the startup is complete:
Now, open your browser and go to http://127.0.0.1:7860. The web interface should look like this:
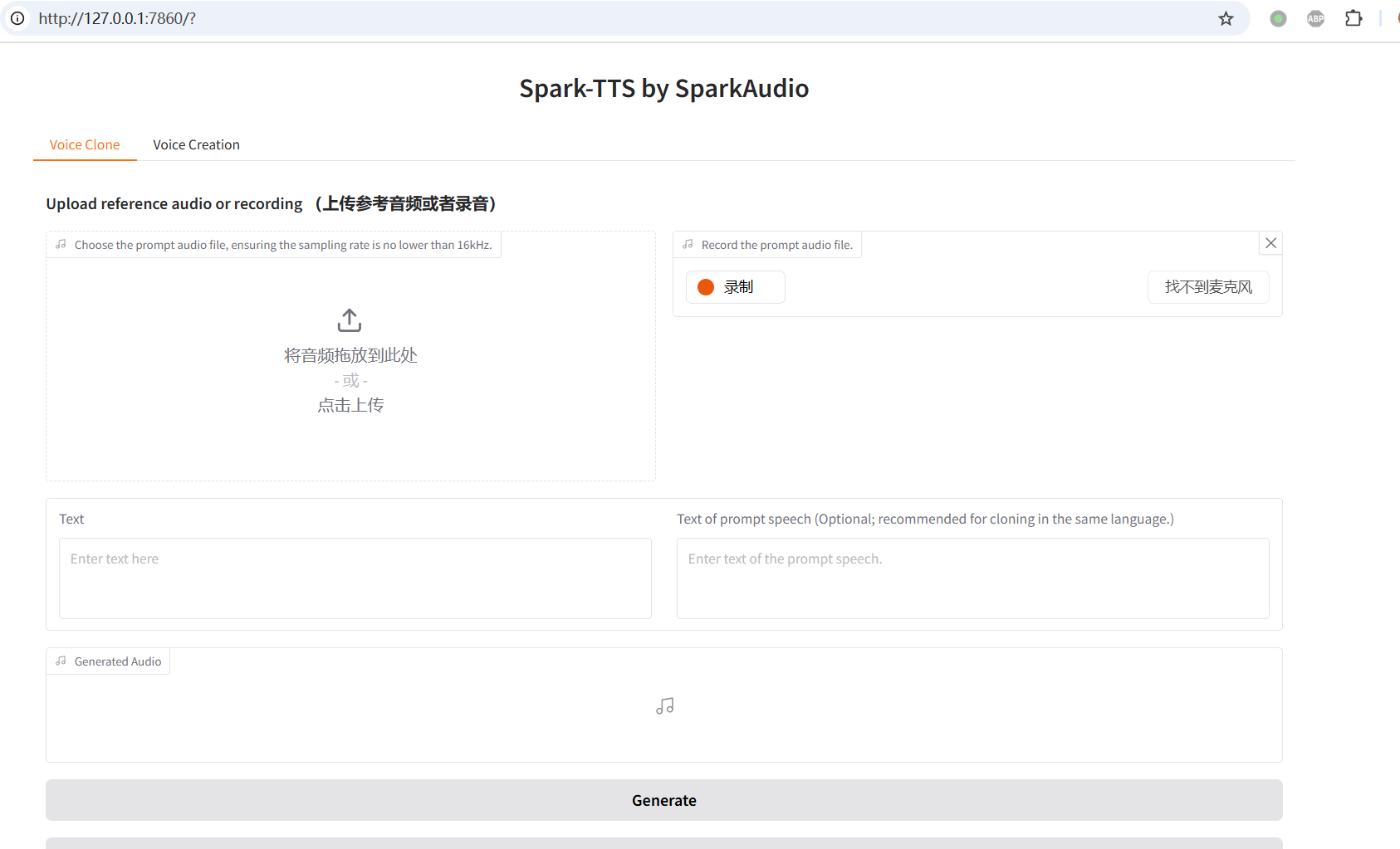
5. Test Voice Cloning
As shown below, select an audio file (3-10 seconds long, clear pronunciation, clean background) whose voice you want to clone.
Then, enter the corresponding text of the audio in the Text of prompt speech field on the right, input the text you want to generate on the left, and finally click the Generate button at the bottom to start.
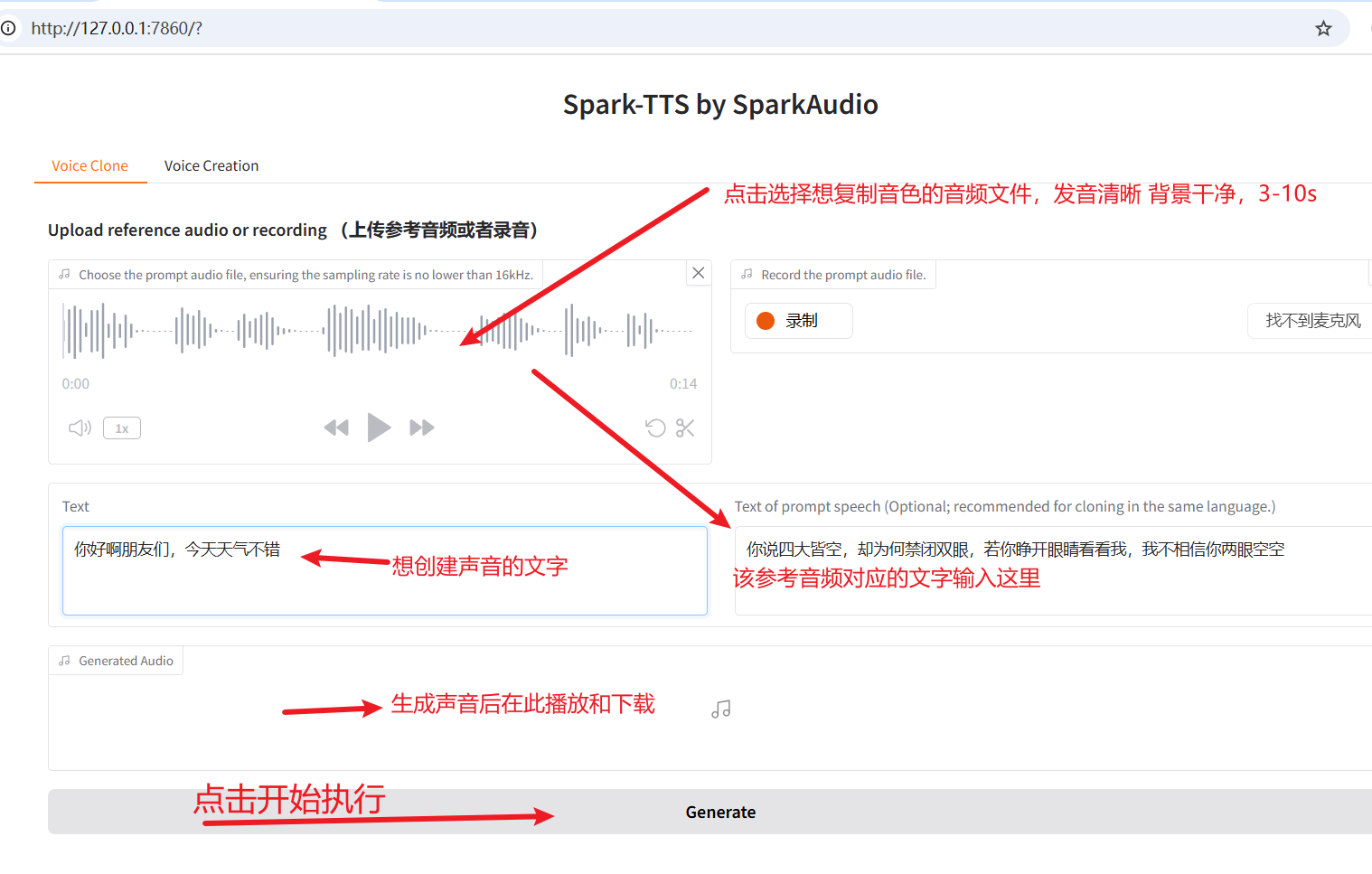
After execution, the result will be displayed as shown.
6. Using in pyVideoTrans Software
Spark-TTS is very similar to F5-TTS. With a simple modification, it can be used directly in the F5-TTS dubbing channel of pyVideoTrans.
- Open the
webui.pyfile and paste the following code around line 135:
def basic_tts(gen_text_input, ref_text_input, ref_audio_input,remove_silence=None,speed_slider=None):
"""
Gradio callback to clone voice using text and optional prompt speech.
- text: The input text to be synthesised.
- prompt_text: Additional textual info for the prompt (optional).
- prompt_wav_upload/prompt_wav_record: Audio files used as reference.
"""
prompt_speech = ref_audio_input
prompt_text_clean = None if len(ref_text_input) < 2 else ref_text_input
audio_output_path = run_tts(
gen_text_input,
model,
prompt_text=prompt_text_clean,
prompt_speech=prompt_speech
)
return audio_output_path,prompt_text_clean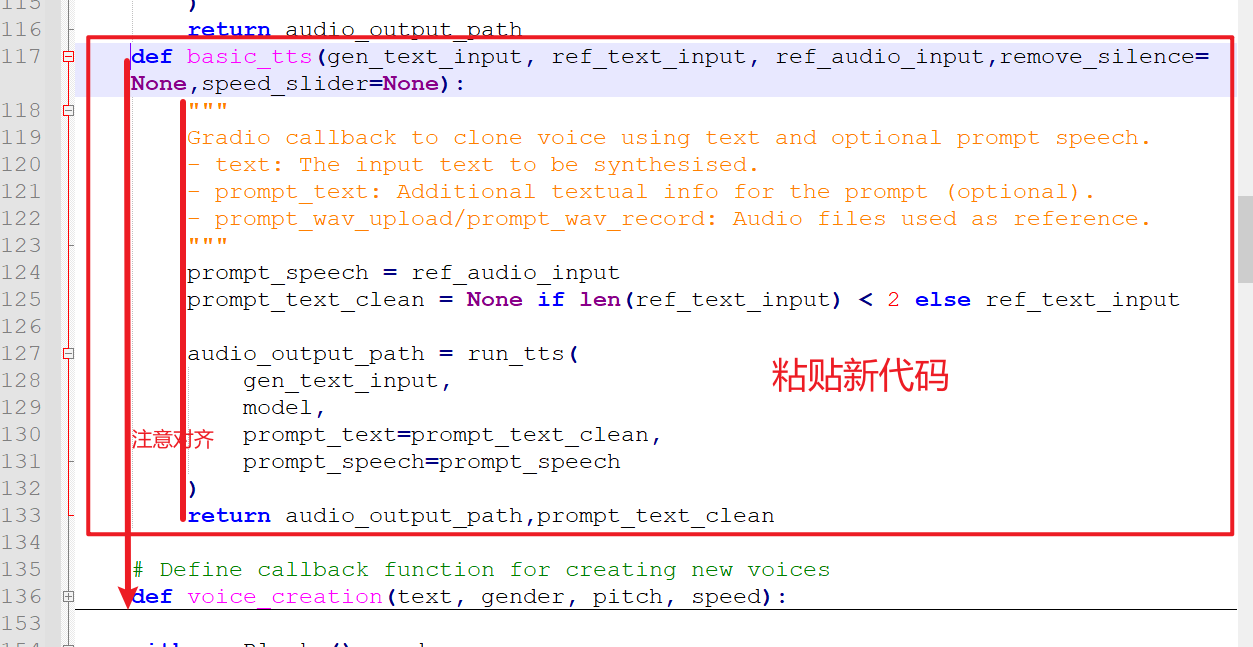
Important Note: Python code uses spaces for indentation; misalignment will cause errors. To avoid issues, do not use Notepad to open webui.py. Instead, use a professional code editor like Notepad++ or VSCode, which are free.
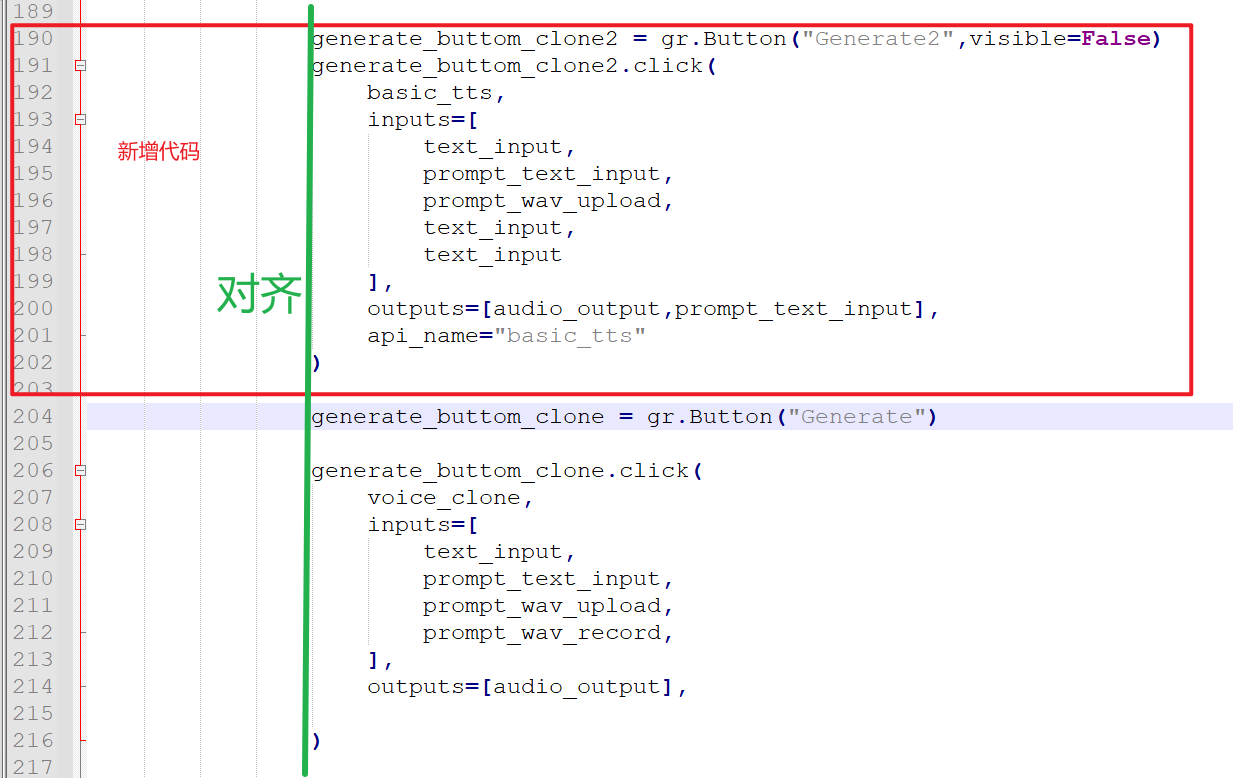
- Then, find the code
generate_buttom_clone = gr.Button("Generate")around line 190. Paste the following code above it, ensuring proper alignment:
generate_buttom_clone2 = gr.Button("Generate2",visible=False)
generate_buttom_clone2.click(
basic_tts,
inputs=[
text_input,
prompt_text_input,
prompt_wav_upload,
text_input,
text_input
],
outputs=[audio_output,prompt_text_input],
api_name="basic_tts"
)
- After saving the file, restart
webui.py:
python webui.py
- Enter the address
http://127.0.0.1:7860in the pyVideoTrans software under "Menu" -> "TTS Settings" -> "F5-TTS" API address to start using it. The reference audio location and input method are the same as for F5-TTS.