Explanation of Advanced Settings Options
You can customize certain parameters in the top menu under Tools/Options > Advanced Settings for more precise control. See the images below.
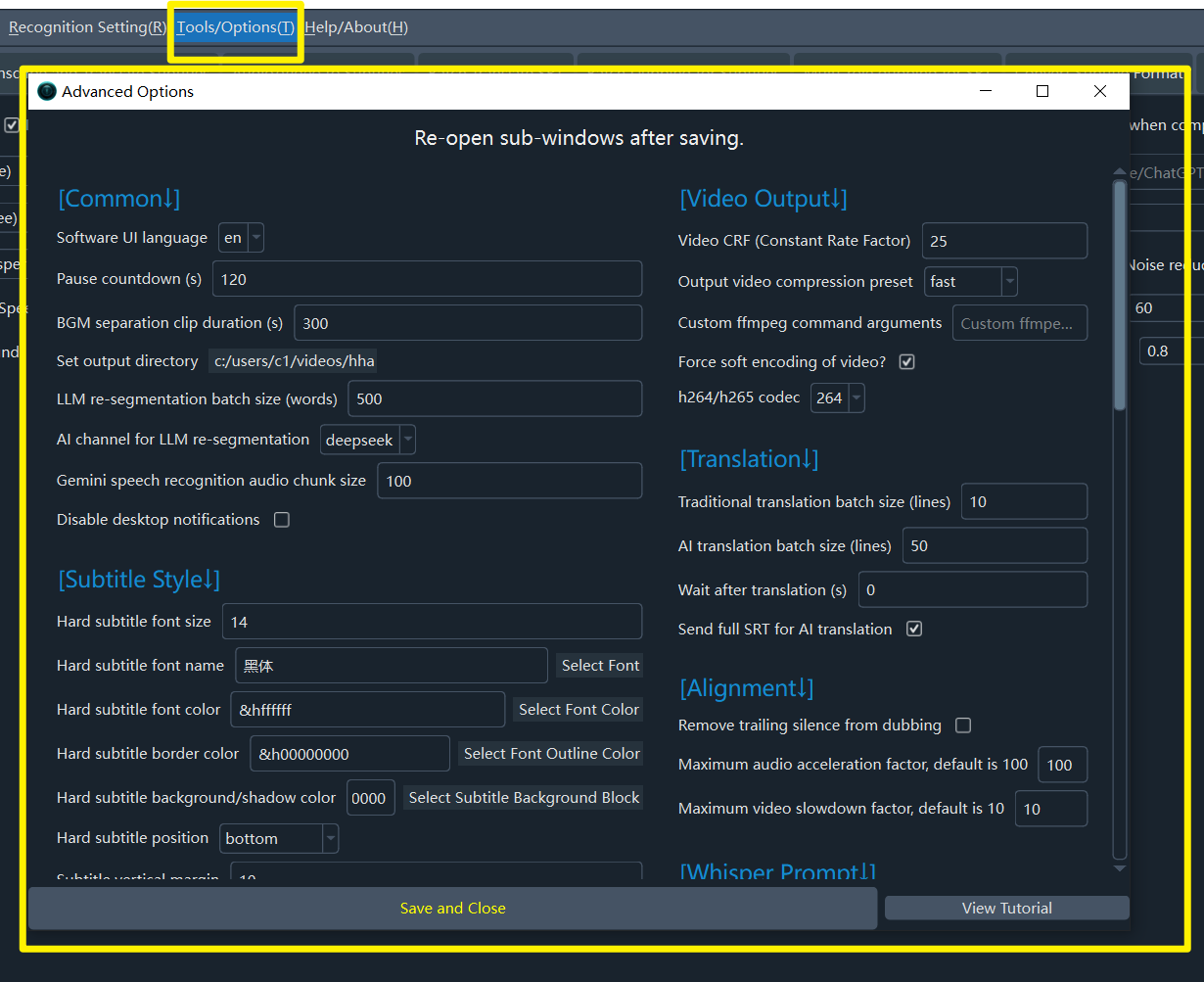
Click on the text titles on the left to view detailed explanations.
Common
- Software interface language: Set the software's interface language. Requires a restart to take effect.
- Countdown for single video translation pause: Countdown in seconds for a single video translation.
- Set output directory: Directory to save results (video separation, subtitles, dubbing). Defaults to the 'output' folder.
- LLM re-segmentation batch word/char count: Chunk size (characters/words) for LLM re-segmentation. Larger values are better but may exceed token limits and fail.
- AI provider for LLM re-segmentation: AI provider for LLM re-segmentation, supports 'openai' or 'deepseek'.
- Gemini speech recognition batch slice count: Number of audio slices per request for Gemini recognition. Larger values improve accuracy but increase failure rate.
- Disable desktop notifications: Disable desktop notifications for task completion or failure.
- Force serial processing for batch translation: Process batch translation sequentially (one by one) instead of in parallel.
- Show all parameters?: To avoid confusion caused by too many parameters, most parameters are hidden by default on the main interface. Selecting this option will switch to displaying all parameters by default.
Video Output
- Video output quality control (CRF): Constant Rate Factor (CRF) for video quality. 0=lossless (huge file), 51=low quality (small file). Default: 23 (balanced).
- Output video compression preset: Controls the encoding speed vs. quality balance (e.g., ultrafast, medium, slow). Faster means larger files.
- Custom FFmpeg command arguments: Custom FFmpeg command arguments, added before the output file argument.
- Force software video encoding?: Force software encoding (slower but more compatible). Hardware encoding is preferred by default.
- H.264/H.265 encoding: Video codec: libx264 (better compatibility) or libx265 (higher compression).
Translation
- Batch size (lines) for traditional translation: Number of subtitle lines per request for traditional translation.
- Batch size (lines) for AI translation: Number of subtitle lines per request for AI translation.
- Pause (s) after each translation request: Delay (in seconds) between translation requests to prevent rate-limiting.
- Send full SRT format for AI translation: Send full SRT format content when using AI translation.
- The higher concurrent of EdgeTTS: The higher the concurrent voice-over capacity of the EdgeTTS channel, the faster the speed, but rate throttling may fail.
- Retries after EdgeTTS failure: Number of retries after EdgeTTS channel failure
Dubbing
- Concurrent dubbing threads: Number of concurrent threads for dubbing.
- Pause (s) after each dubbing request: Delay (in seconds) between dubbing requests to prevent rate-limiting.
- Save dubbed audio for each subtitle line: Save the dubbed audio for each individual subtitle line.
- Azure TTS batch size (lines): Number of lines per batch request for Azure TTS.
- ChatTTS voice timbre value: ChatTTS voice timbre value.
Alignment
- Remove trailing silence from dubbing: Remove trailing silence from dubbed audio.
- Maximum audio speed-up rate: Maximum audio speed-up rate. Default: 100.
- Maximum video slow-down rate: Maximum video slow-down rate. Default: 10 (cannot exceed 10).
ASR Settings
- Enable VAD segmentation: Enable Voice Activity Detection (VAD) for faster-whisper's global recognition mode.
- VAD: Speech probability threshold: VAD: Minimum probability for an audio chunk to be considered speech. Default: 0.45.
- VAD: Min speech duration (ms): VAD: Minimum duration (ms) for a speech segment to be kept. Default: 0ms.
- VAD: Max speech duration (s): VAD: Maximum duration (s) of a single speech segment before splitting. Default: 5s.
- VAD: Min silence duration for split (ms): VAD: Minimum silence duration (ms) to mark the end of a segment. Default: 140ms.
- VAD: Speech padding (ms): VAD: Padding (ms) added to the start and end of detected speech segments. Default: 0.
- faster/whisper models: Comma-separated list of model names for faster-whisper and OpenAI modes.
- whisper.cpp models: Comma-separated list of model names for whisper.cpp mode.
- CUDA compute type: CUDA compute type for faster-whisper (e.g., int8, float16, float32, default).
- Recognition accuracy (beam_size): Beam size for transcription (1-5). Higher is more accurate but uses more VRAM.
- Recognition accuracy (best_of): Best-of for transcription (1-5). Higher is more accurate but uses more VRAM.
- Enable context awareness: Condition on previous text for better context (uses more GPU, may cause repetition).
- Threads nums for noise&separation: The more threads used for noise reduction and separation of human and background voices, the faster the process, but the more resources it consumes.
- Force batch inference: Force batch inference in global recognition mode (faster, but results in longer segments).
- Convert Traditional to Simplified Chinese subtitles: Force conversion of recognized Traditional Chinese to Simplified Chinese.
Whisper Prompt
- initial prompt for Simplified Chinese: Initial prompt for the Whisper model for Simplified Chinese speech.
- initial prompt for Traditional Chinese: Initial prompt for the Whisper model for Traditional Chinese speech.
- initial prompt for English: Initial prompt for the Whisper model for English speech.
- initial prompt for French: Initial prompt for the Whisper model for French speech.
- initial prompt for German: Initial prompt for the Whisper model for German speech.
- initial prompt for Japanese: Initial prompt for the Whisper model for Japanese speech.
- initial prompt for Korean: Initial prompt for the Whisper model for Korean speech.
- initial prompt for Russian: Initial prompt for the Whisper model for Russian speech.
- initial prompt for Spanish: Initial prompt for the Whisper model for Spanish speech.
- initial prompt for Thai: Initial prompt for the Whisper model for Thai speech.
- initial prompt for Italian: Initial prompt for the Whisper model for Italian speech.
- initial prompt for Portuguese: Initial prompt for the Whisper model for Portuguese speech.
- initial prompt for Vietnamese: Initial prompt for the Whisper model for Vietnamese speech.
- initial prompt for Arabic: Initial prompt for the Whisper model for Arabic speech.
- initial prompt for Turkish: Initial prompt for the Whisper model for Turkish speech.
- initial prompt for Hindi: Initial prompt for the Whisper model for Hindi speech.
- initial prompt for Hungarian: Initial prompt for the Whisper model for Hungarian speech.
- initial prompt for Ukrainian: Initial prompt for the Whisper model for Ukrainian speech.
- initial prompt for Indonesian: Initial prompt for the Whisper model for Indonesian speech.
- initial prompt for Malay: Initial prompt for the Whisper model for Malaysian speech.
- initial prompt for Kazakh: Initial prompt for the Whisper model for Kazakh speech.
- initial prompt for Czech: Initial prompt for the Whisper model for Czech speech.
- initial prompt for Polish: Initial prompt for the Whisper model for Polish speech.
- initial prompt for Dutch: Initial prompt for the Whisper model for Dutch speech.
- initial prompt for Swedish: Initial prompt for the Whisper model for Swedish speech.
- initial prompt for Hebrew: Initial prompt for the Whisper model for Hebrew speech.
- initial prompt for Bengali: Initial prompt for the Whisper model for Bengali speech.
- initial prompt for Persian: Initial prompt for the Whisper model for Persian speech.
- initial prompt for Urdu: Initial prompt for the Whisper model for Urdu speech.
- initial prompt for Cantonese: Initial prompt for the Whisper model for Cantonese speech.
- initial prompt for Filipino: Initial prompt for the Whisper model for Filipino speech.