VAD Parameter Adjustment in Speech Recognition
In the speech recognition stage of video translation, generated subtitles may sometimes be too long (tens of seconds or even minutes) or too short (less than a second). By adjusting VAD (Voice Activity Detection) parameters, these issues can be optimized to make subtitles better match the actual speech content.
What is VAD?
Silero VAD is an efficient voice activity detection tool used to identify speech segments in audio and separate them from silence or noise. It can be integrated with speech recognition tools (such as Whisper) to detect and segment speech fragments before and after recognition, thereby improving recognition results.
In faster-whisper, VAD is enabled by default to analyze and segment audio, primarily through the adjustment of the following five parameters. These parameters help users control the detection and segmentation of speech and silence, optimizing subtitle generation.
Parameter Details and Adjustment Suggestions
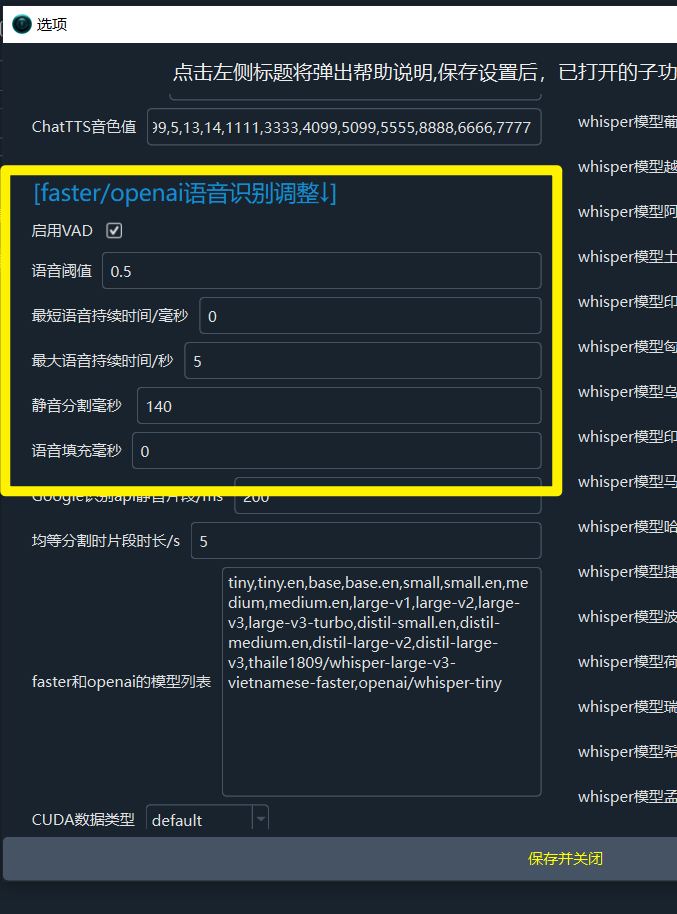
threshold (Speech Threshold)
Function: Represents the minimum probability for an audio segment to be considered speech. Silero VAD calculates the speech probability for each audio segment; parts exceeding this threshold are treated as speech, while others are considered silence or noise.
Adjustment Suggestion: The default value is 0.5, which works for most cases. If there are frequent misjudgments (e.g., noise being recognized as speech), try increasing it to 0.6 or 0.7. If too many speech segments are missed, reduce it to 0.3 or 0.4. Test gradually based on audio quality.
min_speech_duration_ms (Minimum Speech Duration, in milliseconds)
Function: If a detected speech segment is shorter than this value, it will be discarded to remove brief non-speech noise.
Adjustment Suggestion: The default is 0 ms (no restriction), but it is recommended to set it to 250 ms to filter out short noises. If the audio contains short phrases, keep the default. To remove more noise, increase it to 500 ms.
max_speech_duration_s (Maximum Speech Duration, in seconds)
Function: Limits the maximum length of a single speech segment. If the duration exceeds this value, the system will split it at silence intervals longer than 100 ms. If no silence is detected, it will force a split just before the specified duration to avoid overly long segments.
Adjustment Suggestion: The default is 5 seconds. To control segment length (e.g., for dialogue segmentation), set it to 10 or 30 seconds, depending on your needs.
min_silence_duration_ms (Silence Segmentation Duration, in milliseconds)
Function: After speech ends, the system waits for silence to last this long before segmenting the speech fragment.
Adjustment Suggestion: The default is 140 ms (0.14 seconds). For more lenient segmentation, increase it to 2000 ms.
speech_pad_ms (Speech Padding Time, in milliseconds)
Function: Adds buffer time before and after detected speech segments to avoid cutting off edges of speech.
Adjustment Suggestion: The default is 0 ms. If subtitles are missing the beginning or end, increase it to 500 or 800 ms.
How to Adjust Parameters
These parameters can be easily adjusted in the software:
Note: You must check the Enable VAD checkbox for the parameters to take effect, as shown in the image below.
- Go to Menu > Tools/Options > Advanced Options > [faster/openai speech recognition adjustment area], as shown in the image.
- Alternatively, after performing speech recognition on the main interface, select
faster-whisper local, click the "Speech Recognition" text on the left, and the parameter adjustment text boxes will appear below.
Adjustment Tips
- Prioritize Audio Quality: While parameter tuning is important, a clean audio background has a greater impact on recognition results. Use clear, noise-free audio whenever possible.
- Test Gradually: Start with default values and adjust parameters one by one, observing subtitle changes to find the optimal settings.
- Adapt to Scenarios: Adjust max_speech_duration_s and min_silence_duration_ms based on the audio type (e.g., dialogue, monologue).
Summary
- threshold: Adjust based on audio characteristics; the default 0.5 is generally suitable.
- min_speech_duration_ms and min_silence_duration_ms: Control speech segment length and segmentation sensitivity.
- max_speech_duration_s: Limits long segments, suitable for segmentation needs.
- speech_pad_ms: Ensures speech completeness and avoids excessive cutting.
Properly setting these parameters can significantly improve VAD performance and generate more accurate subtitles.