Speech recognition converts human speech in audio/video into text, serving as the first step in video translation and a key factor in determining the quality of subsequent dubbing and subtitles.
Currently, the software primarily supports two models that can perform local offline recognition: faster-whisper local and openai-whisper local.
Both are very similar. Essentially, faster-whisper is an optimized version of openai-whisper, with nearly identical recognition accuracy but faster processing speed. However, the former has higher environmental configuration requirements when using CUDA acceleration.
Faster-Whisper Local Recognition Mode
This mode is the default and recommended option, offering faster speed and higher efficiency.
The model sizes in this mode, from smallest to largest, are: tiny -> base -> small -> medium -> large-v1 -> large-v3.
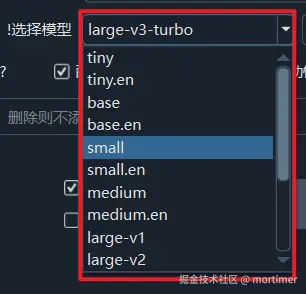
From front to back, the model size increases from 60MB to 2.7GB, and the memory, VRAM, and CPU/GPU consumption also gradually increase. If the available VRAM is less than 10GB, it is not recommended to use large-v3, as it may cause crashes or freezing.
From tiny to large-v3, as the size and resource consumption increase, the recognition accuracy also improves. Models like tiny/base/small are lightweight models with fast recognition speed and low resource usage, but their accuracy is relatively low.
medium is a mid-sized model. For videos with Chinese pronunciation, it is recommended to use a model at least as large as medium; otherwise, the results may be unsatisfactory.
If the CPU is powerful enough and memory is ample, even without CUDA acceleration, the large-v1/v2 models can be used. Their accuracy is significantly higher than that of smaller models, though the recognition speed will be slower.
large-v3 consumes substantial resources and is not recommended unless the computer is highly capable. It is advisable to use large-v3-turbo instead, as it offers the same accuracy but is faster and uses fewer resources.
Models with names ending in
.enor starting withdistilare only suitable for videos with English pronunciation and should not be used for videos in other languages.
OpenAI-Whisper Local Recognition Mode
The models in this mode are essentially the same as those in faster-whisper, with sizes ranging from small to large: tiny -> base -> small -> medium -> large-v1 -> large-v3. The usage considerations are also the same: tiny/base/small are lightweight models, while large-v1/v2/v3 are large models.
Summary and Selection Guidelines
- Prioritize the faster-whisper local mode unless you encounter persistent environment errors when attempting to use CUDA acceleration, in which case the openai-whisper local mode can be used.
- Regardless of the mode, for videos with Chinese pronunciation, it is recommended to use at least the medium model, with small as the minimum. For English pronunciation videos, use at least the small model. If computer resources are sufficient, large-v3-turbo is recommended.
- Models ending in
.enor starting withdistilare only suitable for videos with English pronunciation.