This is a powerful open-source Video Translation / Speech Transcription / Speech Synthesis Software, dedicated to seamlessly converting videos from one language to another, complete with dubbed audio and subtitles in the target language.
Core Features at a Glance
- Fully Automated Video & Audio Translation: Intelligently recognizes and transcribes speech in audio/video, generates source language subtitles, translates them into the target language, generates dubbed audio, and finally merges the new audio and subtitles into the original video—all in one go.
- Speech Transcription / Video-to-Subtitle: Batch transcribe human speech from video or audio files into accurate SRT subtitle files with timecodes.
- Speech Synthesis / Text-to-Speech (TTS): Utilize a variety of advanced TTS channels to generate high-quality, natural-sounding voiceovers for your text or SRT subtitle files.
- SRT Subtitle Translation: Support for batch translation of SRT subtitle files, preserving original timecodes and formatting, with various bilingual subtitle styling options.
- Real-time Speech-to-Text: Supports real-time microphone monitoring to convert speech into text.
How the Software Works
Before getting started, it is crucial to understand the core workflow of this software:
First, Human Speech in the audio or video is processed via a [Speech Recognition Channel] to generate a subtitle file. Then, this subtitle file is passed through a [Translation Channel] to translate it into the target language. Next, the translated subtitles are used by a selected [Dubbing Channel] to generate voiceover audio. Finally, the subtitles, audio, and original video are embedded and aligned to complete the video translation process.
- Can Process: Any audio or video containing human speech, regardless of whether it has embedded subtitles.
- Cannot Process: Videos containing only background music and hardcoded subtitles but no human speech. This software cannot directly extract hardcoded subtitles from the video frames (OCR).
Download and Installation
1.1 Windows Users (Pre-packaged Version)
We provide an out-of-the-box pre-packaged version for Windows 10/11 users. No complex configuration is required; simply download, unzip, and run.
Click here to download the Windows pre-packaged version, unzip and run
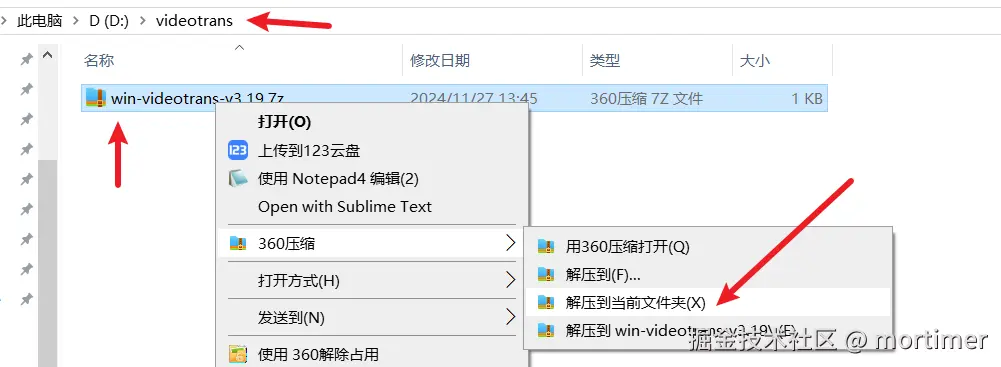
Unzipping Precautions
Please do not double-click
sp.exedirectly inside the compressed file; this will inevitably cause errors. Incorrect unzipping is the most common reason for software startup failures. Please strictly adhere to the following rules:
- Do Not Use Admin-Restricted Paths: Do not unzip to system folders requiring special permissions, such as
C:/Program FilesorC:/Windows. - Recommended: Use a folder with only English/Numbers: It is strongly advised that the unzipping path does not contain any Chinese characters, spaces, or special symbols, and the path depth should not be too long.
- Highly Recommended: Create a folder with a pure English or numeric name on a non-system drive like D: or E: (e.g.,
D:/videotrans), and extract the archive into this folder.
Starting the Software
After unzipping, enter the folder, find the sp.exe file, and double-click to run it. 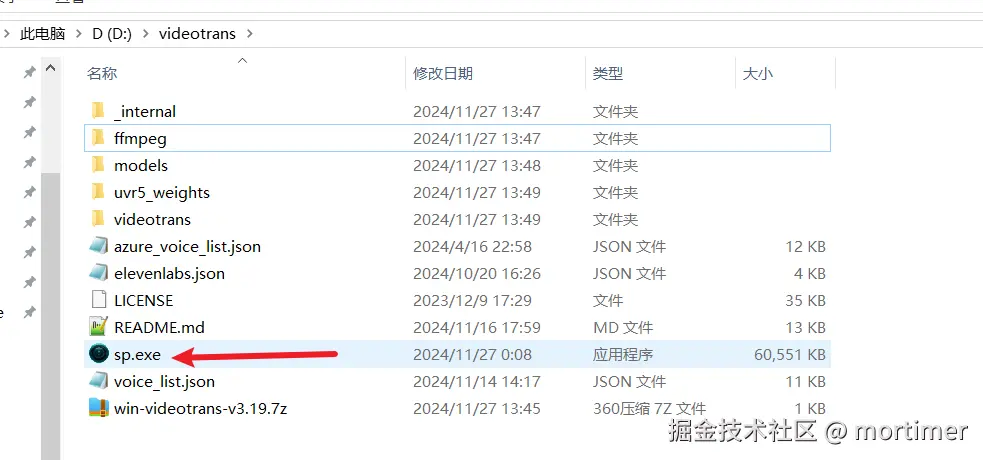
The software needs to load many modules upon its first launch. This may take several dozen seconds; please wait patiently.
1.2 MacOS / Linux Users (Source Code Deployment)
MacOS and Linux users need to deploy via source code.
- Source Code Repository: https://github.com/jianchang512/pyvideotrans
- Detailed Deployment Tutorials:
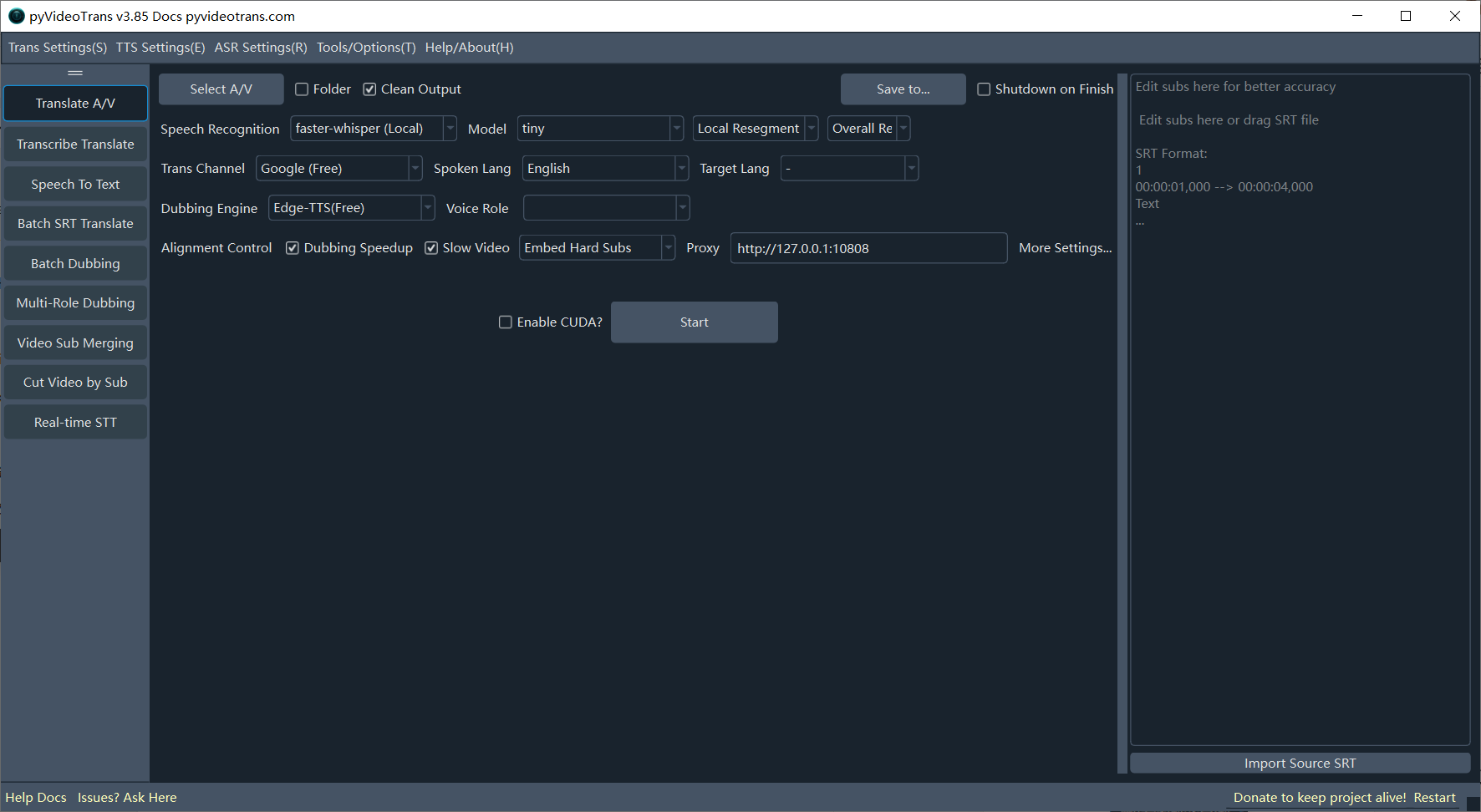
Software Interface & Core Functions
After starting the software, you will see the main interface as shown below.
- Left Function Area: Switch between the software's main modules, such as Translate Video & Audio, Transcribe & Translate Subtitles, Audio/Video to Subtitles, Batch Translate SRT, Batch Dub Subtitles, Multi-role Dubbing, Merge A/V/Subs, Cut Video by Subtitle, Real-time STT, etc.

- Top Menu Bar: For global configurations.

- Translation Settings: Configure API Keys and parameters for various translation channels (e.g., OpenAI, Azure, DeepSeek).
- TTS Settings: Configure API Keys and parameters for dubbing channels (e.g., OpenAI TTS, Azure TTS).
- Recognition Settings: Configure API Keys and parameters for speech recognition channels (e.g., OpenAI API, Ali ASR).
- Tools / Options: Contains various advanced options and auxiliary tools, such as subtitle formatting, video merging, vocal separation, etc.
- Help / About: View software version information, documentation, and community links.

Function: Translate Video and Audio
By default, the software opens to the Translate Video and Audio workspace. This is the core feature. We will guide you step-by-step through a complete video/audio translation task.
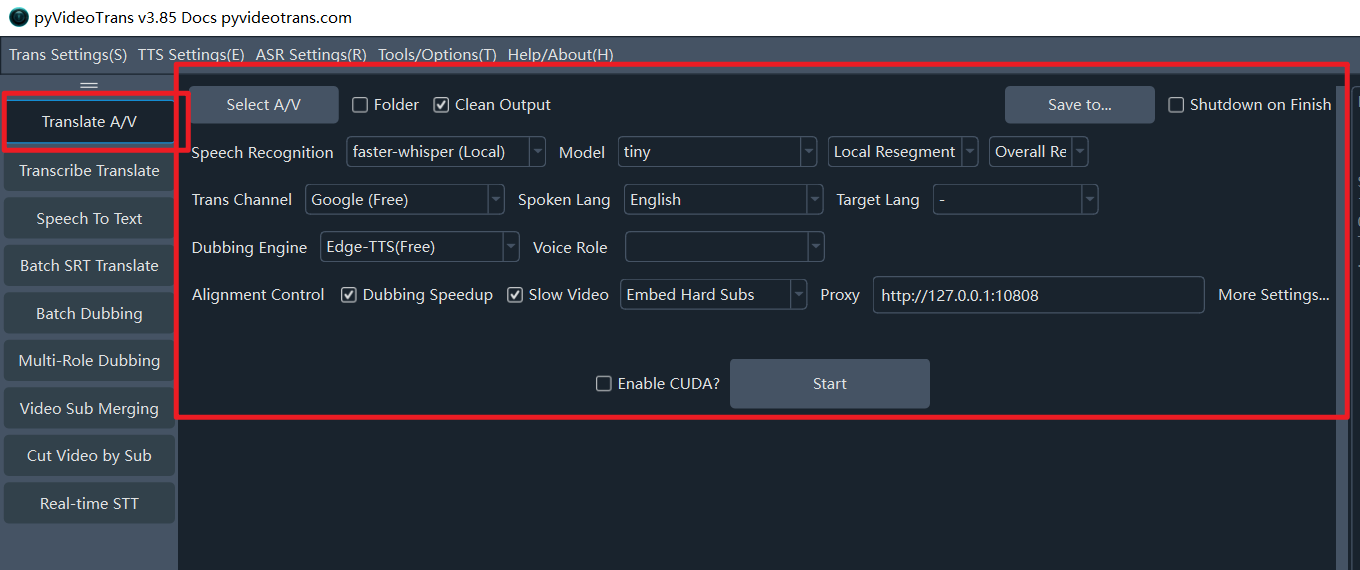
Row 1: Select Video to Translate
Supported Video Formats:
mp4/mov/avi/mkv/webm/mpeg/ogg/mts/tsSupported Audio Formats:
wav/mp3/m4a/flac/aac
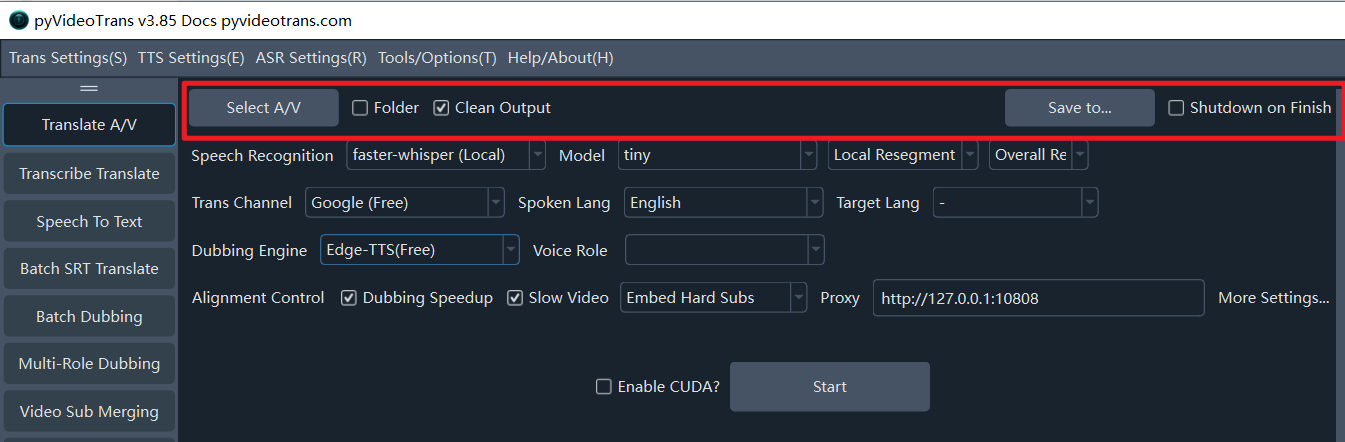
Select Audio/Video: Click this button to select one or more video/audio files to translate (holdCtrlto select multiple).Folder: Check this to batch process all videos within a folder.Clear Generated: Check this if you need to re-process the same video from scratch (ignoring cached files).Output to..: By default, translated files are saved in a_video_outfolder inside the original video's directory. Click this to set a custom output directory.Shutdown after completion: Automatically shuts down the computer after all tasks are finished. Suitable for large batches or long-duration tasks.
Row 2: Voice Recognition Channel
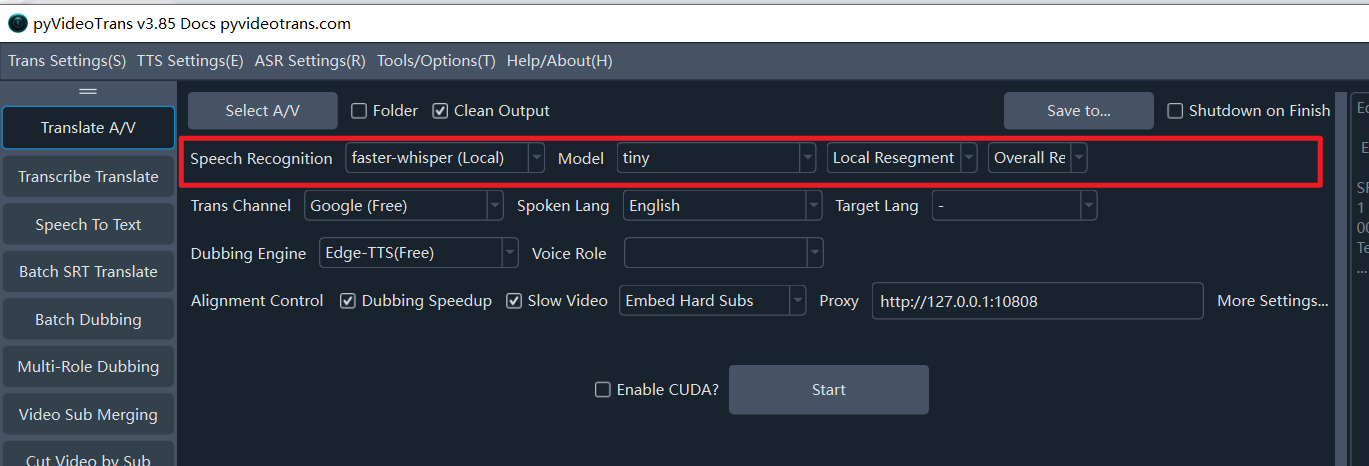
Voice Recognition: Used to transcribe human speech in audio or video into subtitle files. The quality of this step directly determines the final result. Supports over a dozen different recognition methods.faster-whisper (Local): A local model (requires online download on first run). Speed and quality are balanced. Recommended unless you have special needs. It offers about ten models of different sizes.tinyis the smallest/fastest/least resource-intensive but has low accuracy (not recommended).large-v2/large-v3provide the best results and are recommended. Models ending in.enor starting withdistil-are for English audio only.openai-whisper (Local): Similar to the above but slightly slower, possibly with marginally higher accuracy.large-v2/large-v3models are recommended.Ali FunASR (Local): Alibaba's local recognition model. Excellent for Chinese speech. Try this if your source video is in Chinese. Also requires an initial download.- Also supports ByteDance/Volcano Subtitle Generation, OpenAI Speech Recognition, Gemini Speech Recognition, Ali Qwen3-ASR, and various other online APIs and local models.
Default Segmentation | Local Re-segmentation | LLM Re-segmentation: Choose between default segmentation, using Large Language Models (LLM) to intelligently segment text and optimize punctuation, or using local algorithms to re-segment based on punctuation and duration. (Limited to faster-whisper and openai-whisper channels).
Overall Recognition vs. Batch Inference:
Overall Recognitionuses built-in VAD to detect and distinguish speech activity, resulting in better segmentation.Batch Inferencesplits speech based on the setMax Speech Durationand processes 16 parts simultaneously; it is faster but segmentation may be slightly inferior.
Row 3: Translation Channel
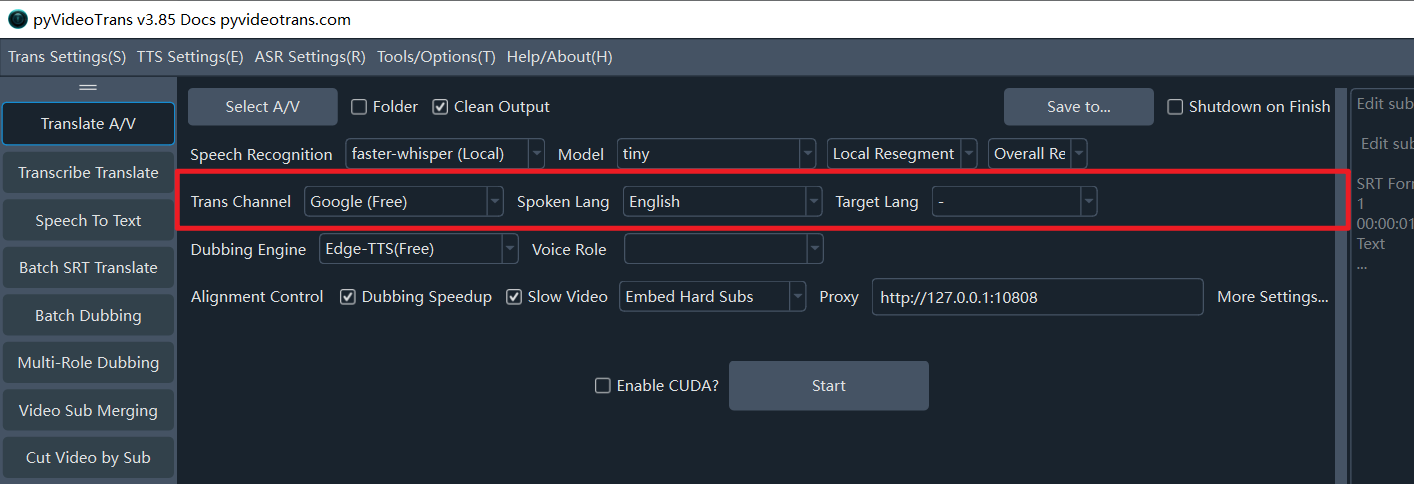
Translation Channel: Used to translate the original language subtitle file generated by transcription into the target language subtitle file. Built-in support for over a dozen channels.
- Free Traditional: Google Translate (Requires Proxy), Microsoft Translate (No Proxy), DeepLX (Self-deployed).
- Paid Traditional: Baidu, Tencent, Ali Machine Translation, DeepL.
- AI Smart Translation: OpenAI ChatGPT, Gemini, DeepSeek, Claude, Zhipu AI, SiliconFlow, 302.AI, etc. Requires your own SK/API Key entered in
Menu -> Translation Settings -> Corresponding Channel Panel. - Compatible AI / Local Model: Supports self-deployed large models. Select the "Compatible AI/Local Model" channel and enter the API address in
Menu -> Translation Settings -> Local LLM Settings. - Source Language: The language spoken in the original video. Must be selected correctly. If unsure, select
auto. - Target Language: The language you wish to translate the audio/video into.
Row 4: Dubbing Channel
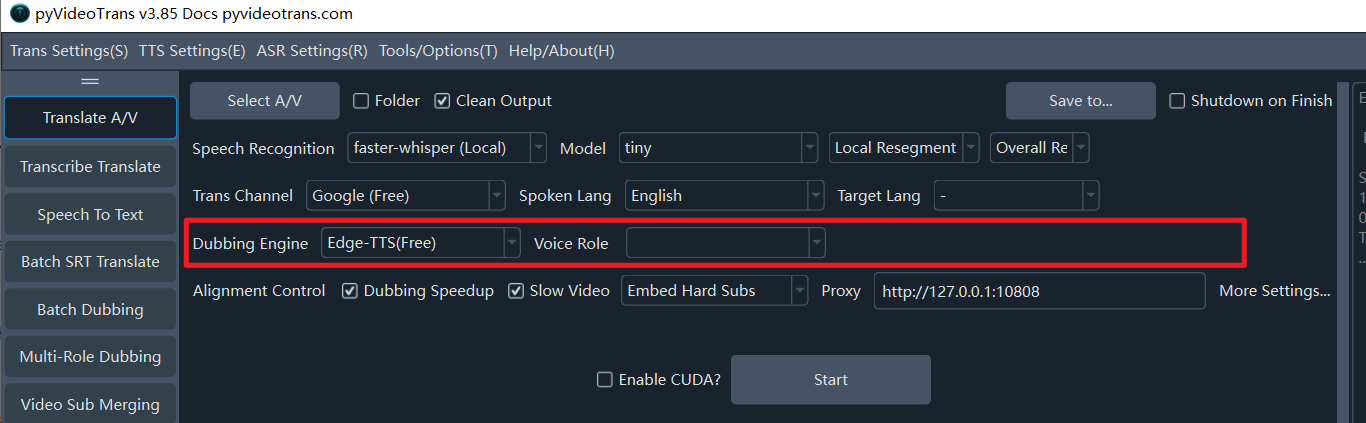
Dubbing Channel: The translated subtitle file will be dubbed using the channel specified here. Supports online APIs like OpenAI TTS, Ali Qwen-TTS, Edge-TTS, ElevenLabs, ByteDance/Volcano, Azure-TTS, Minimaxi, etc., as well as local open-source TTS models like IndexTTS2, F5-TTS, CosyVoice, ChatterBox, VoxCPM, etc. Edge-TTS is a free channel available out of the box. Configure keys for other channels inMenu -> TTS Settings.
- Dubbing Role: Each dubbing channel usually offers multiple voices. After selecting the Target Language, you can choose a Dubbing Role (Voice).
- Test Dubbing: After selecting a role, click to preview the voice effect.
Row 5: Synchronization & Subtitles

Since different languages have different speaking speeds, the dubbed audio duration may not match the original video. Adjustments can be made here. Primarily handles cases where dubbing is longer than the original segment to avoid audio overlap or audio continuing after the video stops. Cases where dubbing is shorter are generally left as is.
Dubbing Acceleration: If a dubbed segment is longer than the original, speed up the audio to match.Video Slow Motion: If a dubbed segment is longer, slow down the video playback for that segment to match the audio. (If checked, processing is time-consuming and generates many intermediate files; total file size may increase significantly to minimize quality loss).No Subtitles: Only replace the audio; do not add any subtitles.Embed Hard Subtitles: Permanently "burn" subtitles into the video frames. Cannot be turned off; visible everywhere.Embed Soft Subtitles: Encapsulate subtitles as a separate track within the video. Players can toggle them on/off. Web players may not display them.(Double): Subtitles will have two lines: original language and target language.Network Proxy: For regions (like Mainland China) accessing foreign services like Google, Gemini, or OpenAI, a proxy is required. If you have a VPN/Proxy service, enter the port here (e.g.,http://127.0.0.1:7860).
Row 6: Start Execution
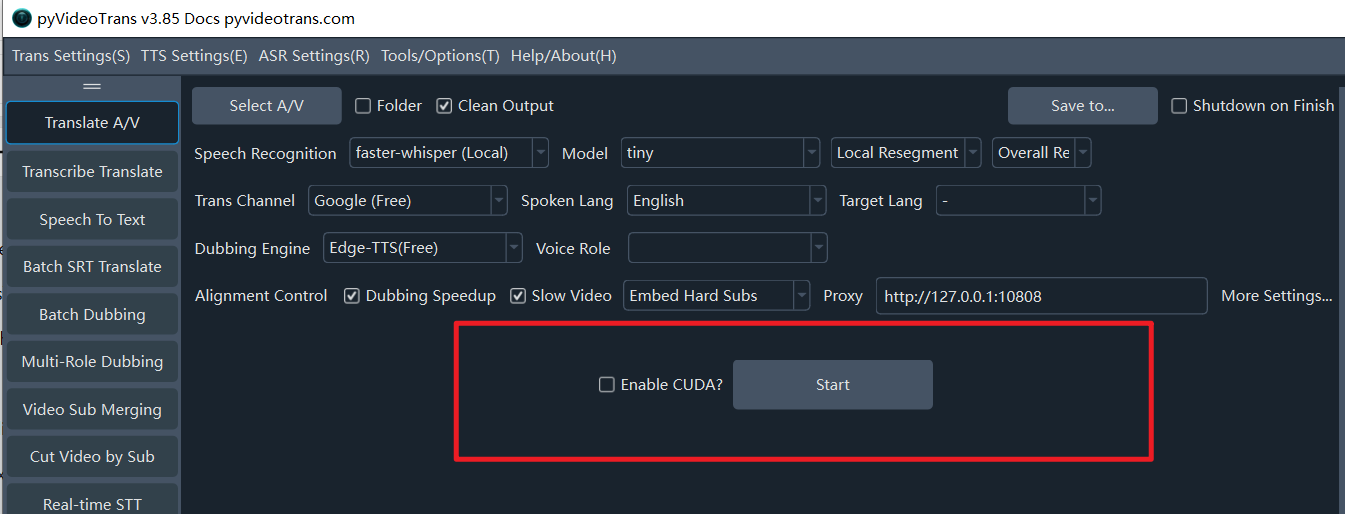
- CUDA Acceleration: On Windows and Linux, if you have an NVIDIA graphics card with the CUDA environment installed, strictly check this box. It can increase speech recognition speed by several times or even dozens of times.
Once all settings are complete, click the [Start] button.
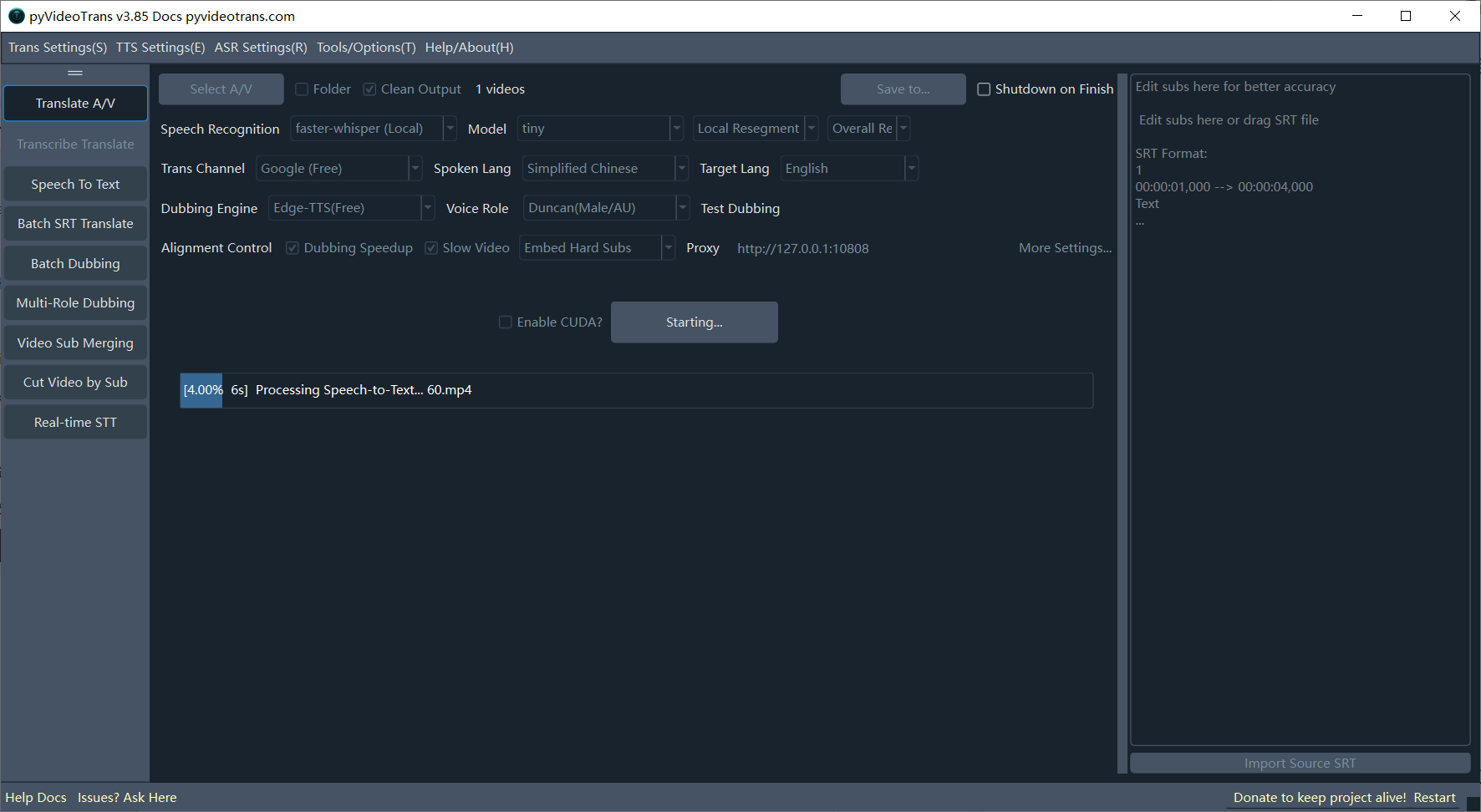
If multiple files are selected, they will be processed sequentially without pausing.
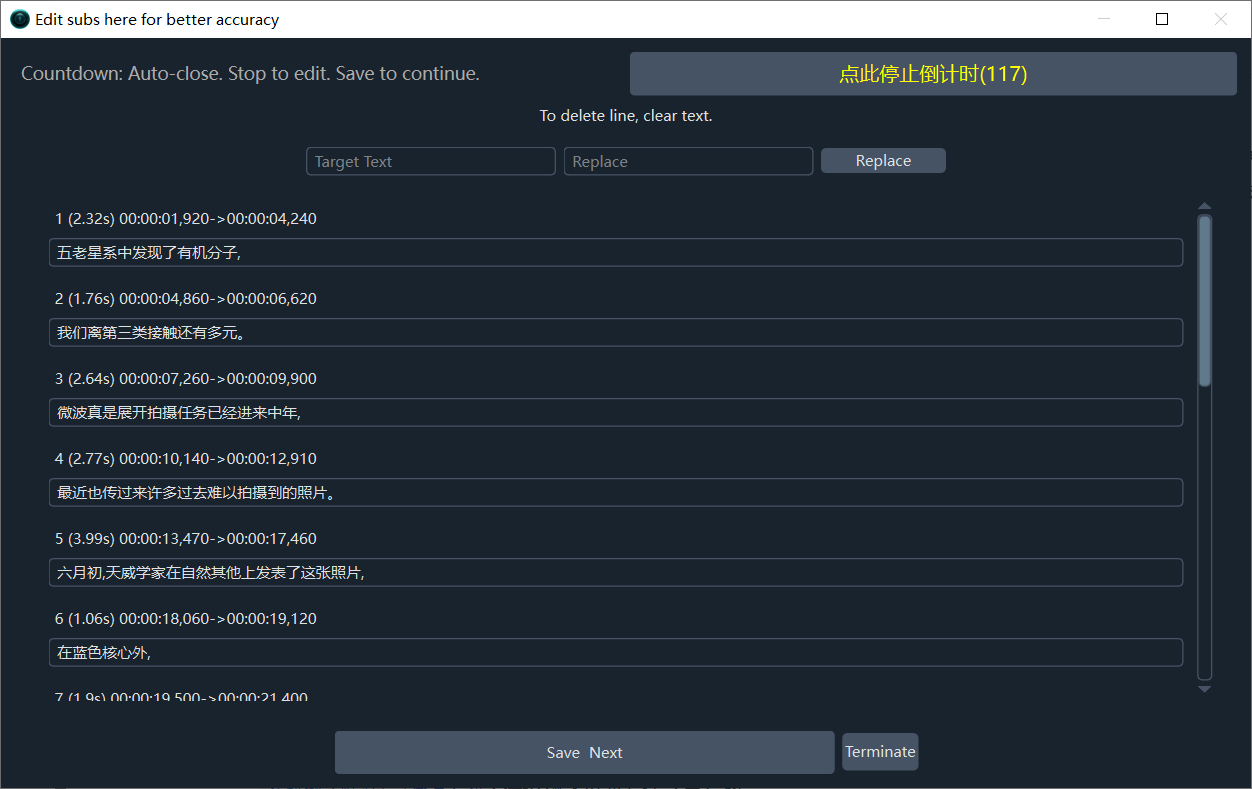
When only ONE video is selected, a separate Subtitle Editor window will pop up after speech transcription is complete. You can modify the subtitles here for better accuracy in subsequent steps.
Pop-up after Speech Recognition Phase:
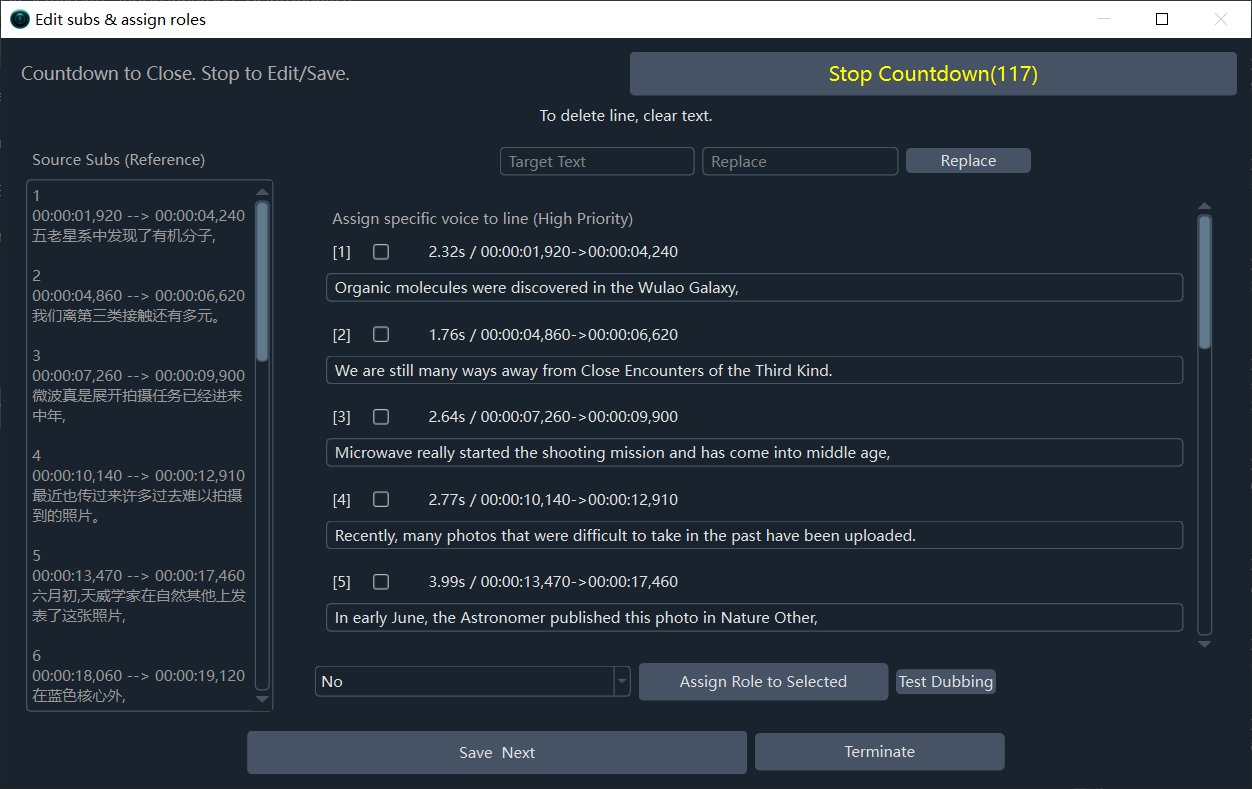
After subtitle translation is complete, another window pops up where you can set different Dubbing Roles for each speaker or specify a voice for specific lines.
Pop-up after Subtitle Translation Phase:
Row 7: Set More Parameters
For finer control over speed, volume, characters per line, denoising, speaker identification, etc., click Set More Parameters....
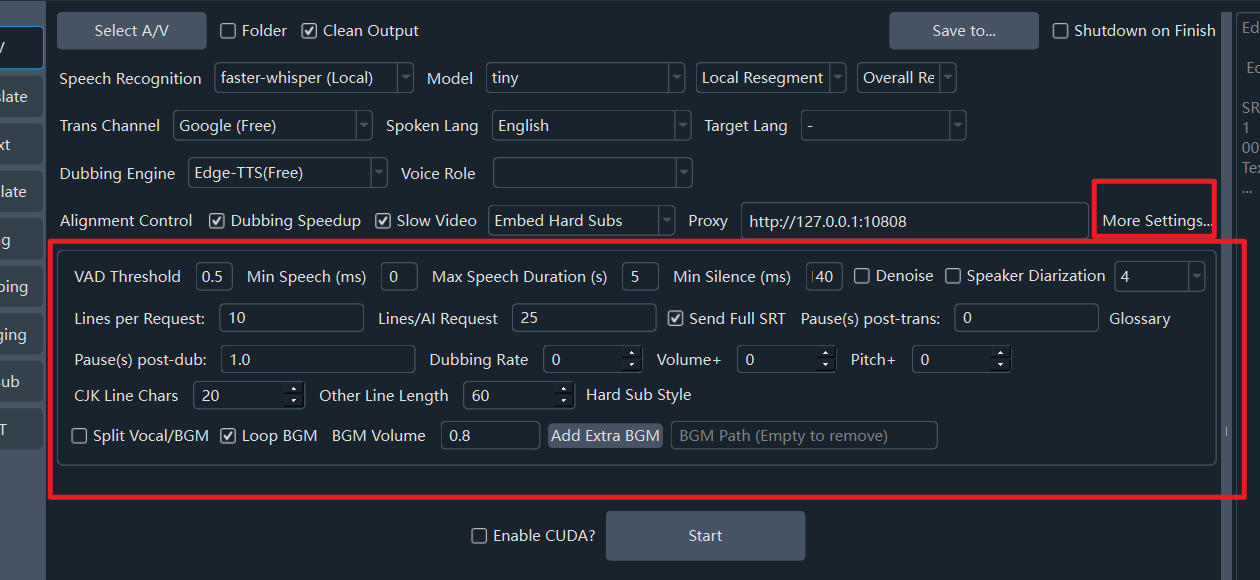
- Denoise: If checked, removes noise from audio before recognition, improving accuracy.
- Identify Speakers: If checked, attempts to distinguish speakers after recognition (accuracy varies). The number following it represents the expected number of speakers; setting this beforehand improves accuracy. Default is unlimited.
- Translation Glossary: Terms sent to AI during translation to ensure consistency.
- Dubbing Speed: Default 0.
50means 50% faster;-50means 50% slower. - Volume +: Default 0.
50means 50% louder;-50means 50% quieter. - Pitch +: Default 0.
20increases pitch by 20Hz (sharper);-20decreases by 20Hz (deeper). - Voice Threshold (VAD): The minimum probability for an audio segment to be considered speech. Default 0.45. Lower is more sensitive but may mistake noise for speech.
- Min Speech Duration (ms): Segments shorter than this are discarded (to remove brief non-speech noises). Unit: ms. Default: 0ms. Setting too high causes missing words.
- Max Speech Duration (s): Limits the maximum length of a single speech segment. Forced split if exceeded. Unit: seconds. Default: 5s.
- Silence Split Duration (ms): Wait for a silence of this duration before splitting a speech segment. Unit: ms. Default: 140ms.
- Lines per Batch (Traditional Translate): Number of lines sent per request for traditional translation channels.
- Lines per Batch (AI Translate): Number of lines sent per request for AI channels.
- Send Full Subtitles: Whether to send the full subtitle format context when using AI translation.
- Pause after Translation (s): Pause time between translation requests (to limit rate).
- Pause after Dubbing (s): Pause time between dubbing requests.
- CJK Max Char per Line: Maximum characters per line for Hard Subtitles in Chinese/Japanese/Korean.
- Other Lang Max Char per Line: Max characters per line for non-CJK languages.
- Modify Hard Subtitle Style: Opens a specialized Hard Subtitle Style Editor.
- Separate Vocals/Background: If selected, separates vocals from background music. The background music is re-embedded during the final merge (Very slow and resource-intensive).
- Loop Background Audio: If background audio is shorter than the final video, loop it. Otherwise, fill with silence.
- Background Volume: Volume of the re-embedded background audio. Default 0.8 (80% of original).
- Add Extra Background Audio: Select a local audio file to use as the new background track.
Row 8: Progress Bar
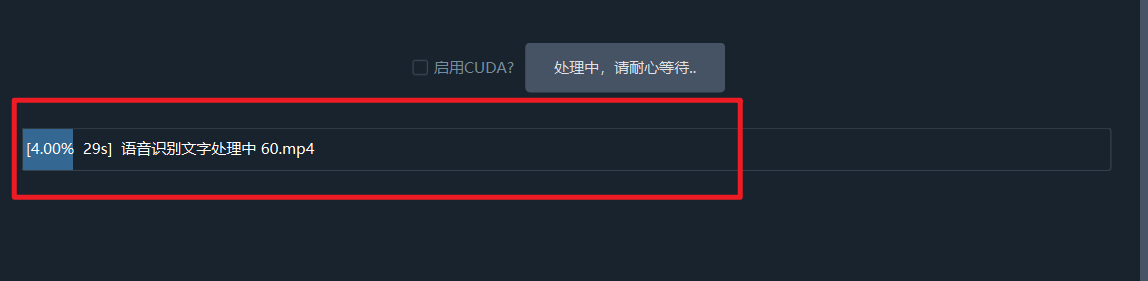
When the task is finished, click the bottom progress bar area to open the output folder. You will find the final MP4 file along with generated SRT subtitles, dubbing files, and other assets.
In addition to core video/audio translation, pyVideoTrans offers several independent powerful features.
Function: Transcribe and Translate Subtitles
Supported Formats: Video (
mp4, etc.) / Audio (wav, etc.)
This function performs the first half of the video translation process: transcribing audio/video to generate an SRT file, and then translating that SRT file to the target language. It stops there. Choose this if you only want to generate subtitles from a video.
Function: Audio/Video to Subtitles (Batch)
Supported Formats: Video (
mp4, etc.) / Audio (wav, etc.)
A panel dedicated to converting video or audio files into text or subtitles. Useful when you don't want to translate the video but just want to batch generate subtitles.
Batch transcribe video/audio to Subtitles or TXT. Drag and drop files, set the Source Language and Recognition Model, and start. Supports Re-segmentation, Denoising, and Speaker Identification.
Function: Batch Translate SRT Subtitles
Supported Format:
srt
If you already have SRT files, this quickly translates them into other languages while preserving the timeline. Supports output formats like Single Language, Target Language on Top (Double), Target Language on Bottom (Double).
Function: Batch Dub Subtitles / Speech Synthesis
Supported Formats:
srt/txt
If you have many subtitle or text files and want to create voiceovers for them in batch.
Synthesize your SRT or plain text into audio files (WAV/MP3) using selected TTS engines. Supports fine-tuning of speed, volume, and pitch.
Function: Multi-role Dubbing
Supported Format:
srt
Similar to Batch Dub Subtitles, but allows you to assign a specific Voice/Role to each line of the subtitle independently, enabling multi-character dubbing.
Function: Merge Audio, Video, and Subtitles
A practical post-production tool. When you have separate Video, Audio (Dubbing), and Subtitle files, use this to perfectly merge them into a final video file. Supports custom subtitle styling.
Function: Cut Video by Subtitle
If you have a video and a corresponding subtitle file (srt/ass/vtt) and want to clip specific "highlight" segments based on the text.
Select the video and subtitle, then check the subtitle lines you want to clip. Options: Cut with audio (default), Cut silent video only, Cut audio only, Cut silent video and audio separately.
Function: Real-time Speech-to-Text
Listens to microphone input and converts speech to text in real-time. Latency under 2 seconds. Automatically segments text, adds punctuation, exports to TXT, and saves recording files.
More features are available under the
Menu -> Tools / Optionsentry.
As seen from the software principles, the three most important components are the Voice Recognition Channel, Translation Channel, and Dubbing Channel.
Voice Recognition Channels
Converts human speech in audio/video to SRT subtitle files. Supports 15 channels:
- faster-whisper Local Mode
- openai-whisper Local Mode
- Ali FunASR Chinese Recognition
- Google Speech Recognition
- ByteDance/Volcano Subtitle Generation
- ByteDance Large Model Speed Edition
- OpenAI Speech Recognition
- Elevenlabs.io Speech Recognition
- Parakeet-tdt Speech Recognition
- STT Speech Recognition API
- Custom Speech Recognition API
- Gemini Large Model Recognition
- Ali Bailian Qwen3-ASR
- deepgram.com Recognition
- faster-whisper-xxl.exe
- Whisper.cpp Recognition
- 302.AI Recognition
Translation Channels
Translates original subtitles generated by
Voice Recognitioninto target language subtitles. Supports 23 channels:
Translation results contain blank lines or are missing many parts
Analysis:When using traditional channels (Baidu, Tencent) or AI channels without checking "Send Full Subtitles", text is sent line-by-line. If the engine returns a different number of lines than sent, blank lines occur.Solution:- Avoid local small models (7b, 14b) unless you set
trans_thread=1inMenu -> Tools -> Advanced Settingsand uncheck "Send Full Subtitles". This is slow and lacks context. - Use smarter online AI models like Gemini or DeepSeek API.
- Avoid local small models (7b, 14b) unless you set
AI Translation includes prompt words in the result
Seen with local small models (14b, 32b). The model size is too small to strictly follow instructions.
Dubbing Channels
Dubs subtitles line-by-line.
You can adjust the number of concurrent dubbing tasks in
Menu -> Tools -> Advanced Options -> Dubbing Threads. Default is 1. Increasing this speeds up the process but may cause API rate limit failures.
How to perform Voice Cloning?
Select F5-TTS, Index-TTS, Clone-Voice, CosyVoice, GPT-SoVITS, or Chatterbox in the Dubbing Channel. Select a
clonerole. It will use the original audio as a reference to generate a dubbed voice matching the original timbre. Note: Reference audio should be 3-10s long, clear, and without background noise.
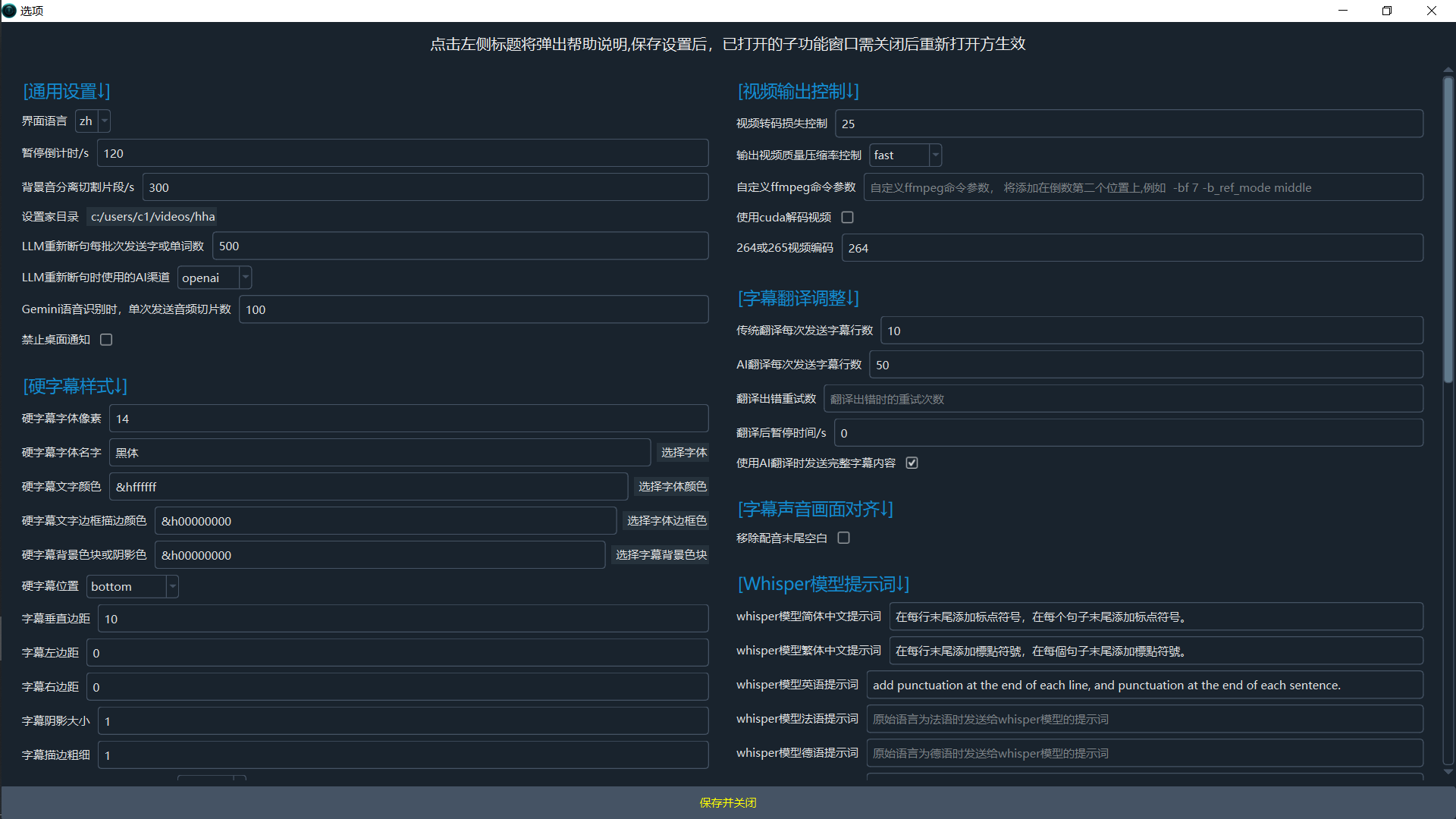
Advanced Options
Menu -> Tools -> Advanced Options provides fine-grained control.
Common
- Software interface language: Set the software's interface language. Requires a restart to take effect.
- Countdown for single video translation pause: Countdown in seconds for a single video translation.
- Set output directory: Directory to save results (video separation, subtitles, dubbing). Defaults to the 'output' folder.
- LLM re-segmentation batch word/char count: Chunk size (characters/words) for LLM re-segmentation. Larger values are better but may exceed token limits and fail.
- AI provider for LLM re-segmentation: AI provider for LLM re-segmentation, supports 'openai' or 'deepseek'.
- Gemini speech recognition batch slice count: Number of audio slices per request for Gemini recognition. Larger values improve accuracy but increase failure rate.
- Disable desktop notifications: Disable desktop notifications for task completion or failure.
- Force serial processing for batch translation: Process batch translation sequentially (one by one) instead of in parallel.
- Show all parameters?: To avoid confusion caused by too many parameters, most parameters are hidden by default on the main interface. Selecting this option will switch to displaying all parameters by default.
Video Output
- Video output quality control (CRF): Constant Rate Factor (CRF) for video quality. 0=lossless (huge file), 51=low quality (small file). Default: 23 (balanced).
- Output video compression preset: Controls the encoding speed vs. quality balance (e.g., ultrafast, medium, slow). Faster means larger files.
- Custom FFmpeg command arguments: Custom FFmpeg command arguments, added before the output file argument.
- Force software video encoding?: Force software encoding (slower but more compatible). Hardware encoding is preferred by default.
- H.264/H.265 encoding: Video codec: libx264 (better compatibility) or libx265 (higher compression).
Translation
- Batch size (lines) for traditional translation: Number of subtitle lines per request for traditional translation.
- Batch size (lines) for AI translation: Number of subtitle lines per request for AI translation.
- Pause (s) after each translation request: Delay (in seconds) between translation requests to prevent rate-limiting.
- Send full SRT format for AI translation: Send full SRT format content when using AI translation.
- The higher concurrent of EdgeTTS: The higher the concurrent voice-over capacity of the EdgeTTS channel, the faster the speed, but rate throttling may fail.
- Retries after EdgeTTS failure: Number of retries after EdgeTTS channel failure
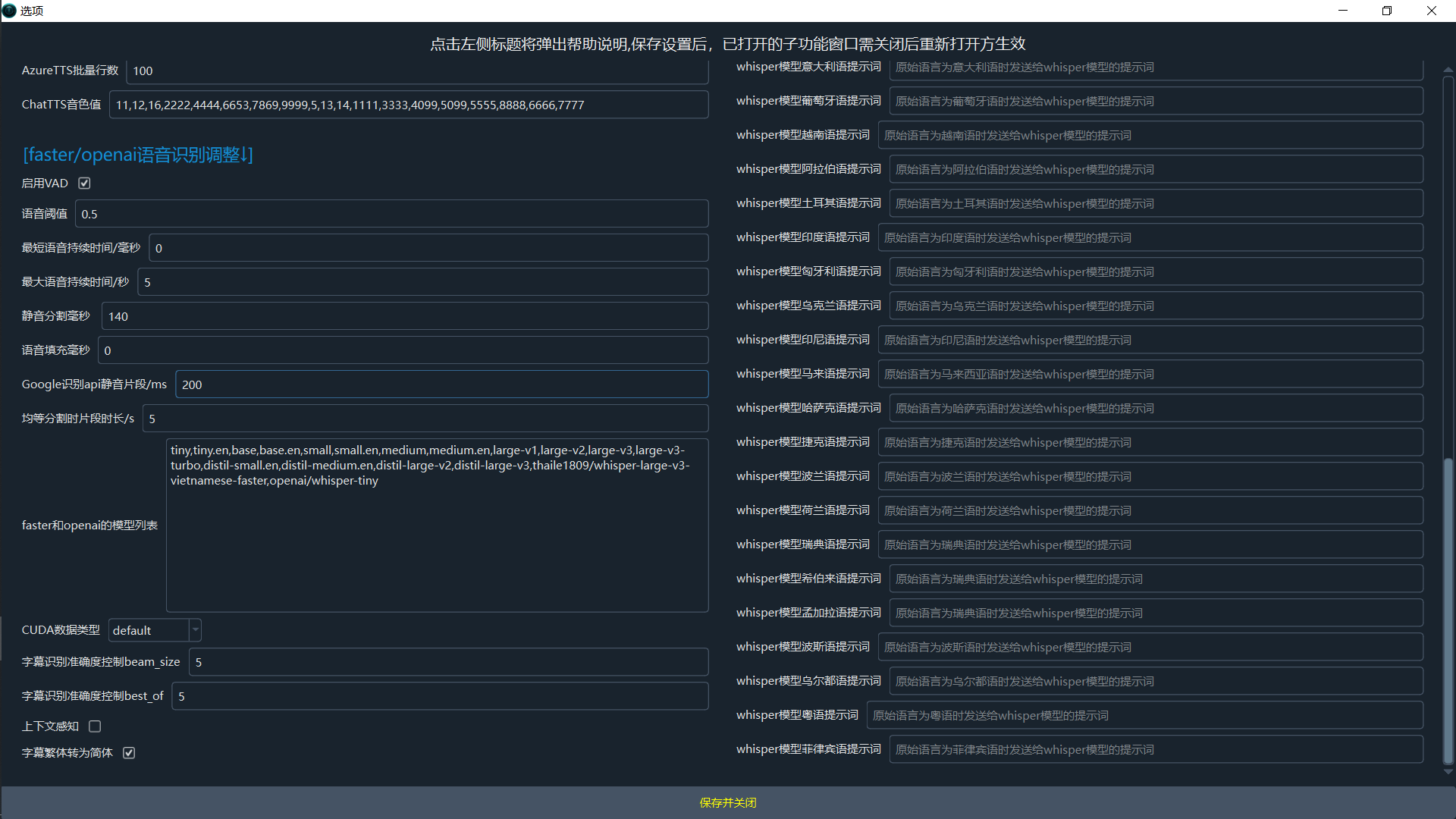
Dubbing
- Concurrent dubbing threads: Number of concurrent threads for dubbing.
- Pause (s) after each dubbing request: Delay (in seconds) between dubbing requests to prevent rate-limiting.
- Save dubbed audio for each subtitle line: Save the dubbed audio for each individual subtitle line.
- Azure TTS batch size (lines): Number of lines per batch request for Azure TTS.
- ChatTTS voice timbre value: ChatTTS voice timbre value.
Alignment
- Remove trailing silence from dubbing: Remove trailing silence from dubbed audio.
- Maximum audio speed-up rate: Maximum audio speed-up rate. Default: 100.
- Maximum video slow-down rate: Maximum video slow-down rate. Default: 10 (cannot exceed 10).
ASR Settings
- Enable VAD segmentation: Enable Voice Activity Detection (VAD) for faster-whisper's global recognition mode.
- VAD: Speech probability threshold: VAD: Minimum probability for an audio chunk to be considered speech. Default: 0.45.
- VAD: Min speech duration (ms): VAD: Minimum duration (ms) for a speech segment to be kept. Default: 0ms.
- VAD: Max speech duration (s): VAD: Maximum duration (s) of a single speech segment before splitting. Default: 5s.
- VAD: Min silence duration for split (ms): VAD: Minimum silence duration (ms) to mark the end of a segment. Default: 140ms.
- VAD: Speech padding (ms): VAD: Padding (ms) added to the start and end of detected speech segments. Default: 0.
- faster/whisper models: Comma-separated list of model names for faster-whisper and OpenAI modes.
- whisper.cpp models: Comma-separated list of model names for whisper.cpp mode.
- CUDA compute type: CUDA compute type for faster-whisper (e.g., int8, float16, float32, default).
- Recognition accuracy (beam_size): Beam size for transcription (1-5). Higher is more accurate but uses more VRAM.
- Recognition accuracy (best_of): Best-of for transcription (1-5). Higher is more accurate but uses more VRAM.
- Enable context awareness: Condition on previous text for better context (uses more GPU, may cause repetition).
- Threads nums for noise&separation: The more threads used for noise reduction and separation of human and background voices, the faster the process, but the more resources it consumes.
- Force batch inference: Force batch inference in global recognition mode (faster, but results in longer segments).
- Convert Traditional to Simplified Chinese subtitles: Force conversion of recognized Traditional Chinese to Simplified Chinese.
Whisper Prompt
- initial prompt for Simplified Chinese: Initial prompt for the Whisper model for Simplified Chinese speech.
- initial prompt for Traditional Chinese: Initial prompt for the Whisper model for Traditional Chinese speech.
- initial prompt for English: Initial prompt for the Whisper model for English speech.
- initial prompt for French: Initial prompt for the Whisper model for French speech.
- initial prompt for German: Initial prompt for the Whisper model for German speech.
- initial prompt for Japanese: Initial prompt for the Whisper model for Japanese speech.
- initial prompt for Korean: Initial prompt for the Whisper model for Korean speech.
- initial prompt for Russian: Initial prompt for the Whisper model for Russian speech.
- initial prompt for Spanish: Initial prompt for the Whisper model for Spanish speech.
- initial prompt for Thai: Initial prompt for the Whisper model for Thai speech.
- initial prompt for Italian: Initial prompt for the Whisper model for Italian speech.
- initial prompt for Portuguese: Initial prompt for the Whisper model for Portuguese speech.
- initial prompt for Vietnamese: Initial prompt for the Whisper model for Vietnamese speech.
- initial prompt for Arabic: Initial prompt for the Whisper model for Arabic speech.
- initial prompt for Turkish: Initial prompt for the Whisper model for Turkish speech.
- initial prompt for Hindi: Initial prompt for the Whisper model for Hindi speech.
- initial prompt for Hungarian: Initial prompt for the Whisper model for Hungarian speech.
- initial prompt for Ukrainian: Initial prompt for the Whisper model for Ukrainian speech.
- initial prompt for Indonesian: Initial prompt for the Whisper model for Indonesian speech.
- initial prompt for Malay: Initial prompt for the Whisper model for Malaysian speech.
- initial prompt for Kazakh: Initial prompt for the Whisper model for Kazakh speech.
- initial prompt for Czech: Initial prompt for the Whisper model for Czech speech.
- initial prompt for Polish: Initial prompt for the Whisper model for Polish speech.
- initial prompt for Dutch: Initial prompt for the Whisper model for Dutch speech.
- initial prompt for Swedish: Initial prompt for the Whisper model for Swedish speech.
- initial prompt for Hebrew: Initial prompt for the Whisper model for Hebrew speech.
- initial prompt for Bengali: Initial prompt for the Whisper model for Bengali speech.
- initial prompt for Persian: Initial prompt for the Whisper model for Persian speech.
- initial prompt for Urdu: Initial prompt for the Whisper model for Urdu speech.
- initial prompt for Cantonese: Initial prompt for the Whisper model for Cantonese speech.
- initial prompt for Filipino: Initial prompt for the Whisper model for Filipino speech.