Rephrasing Recognition Results
To enhance the naturalness and accuracy of subtitle phrasing, pyVideoTrans has introduced AI-based LLM Rephrasing and punctuation-based Local Rephrasing starting from version v3.69, aiming to optimize the subtitle processing experience.
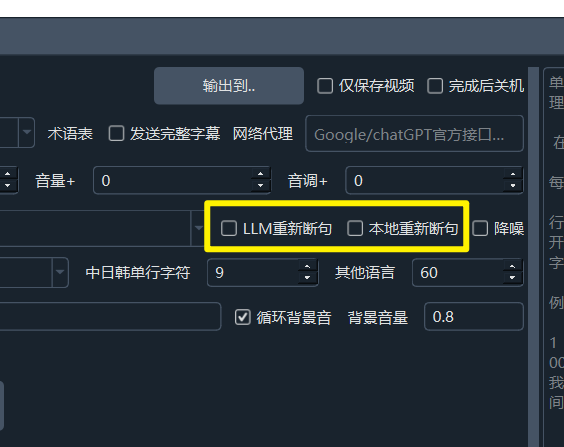
1. Using LLM Large Models to Rephrase Speech Recognition Results
How It Works:
When using faster-whisper (local), openai-whisper (local), or parakeet-tdt for speech recognition with the LLM Rephrasing feature enabled:
- pyVideoTrans sends the recognized
characters/wordscontaining word-level timestamps to the configured LLM for rephrasing. - The LLM intelligently rephrases the text based on the instructions in the prompt file
/videotrans/prompts/recharge/recharge-llm.txt.
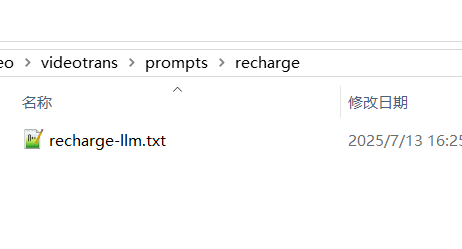
- After rephrasing, the results are reorganized into the standard SRT subtitle format for subsequent translation or direct use.
- If LLM rephrasing fails, the software automatically falls back to using the phrasing results provided by
faster-whisper/openai-whisper/parakeet-tdt.
Fine Control
To successfully enable and use this feature, ensure the following conditions are met:
Select Speech Segmentation Mode: Must be set to
Full Recognition.
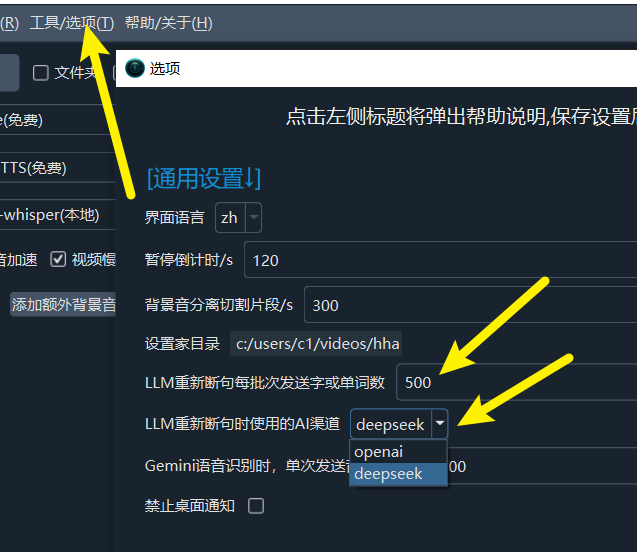
Configure LLM API: In Menu -> Translation Settings -> OpenAI API and Compatible AI or DeepSeek, correctly fill in your API Key (SK), select the model name, and set other relevant parameters.
By default,
OpenAI APIis used for rephrasing. You can switch toDeepSeekinMenu -> Tools -> Advanced Options -> AI Channel for LLM Rephrasing.Adjust the value in
Tools -> Options -> Advanced Options -> Number of Characters Sent per Batch for LLM Rephrasing. By default, a rephrasing request is sent every 500 characters or words. A larger value improves rephrasing quality, but if the output exceeds the maximum allowed tokens for the model, it may cause errors. Increasing this value also requires adjusting the Max Output Tokens mentioned below accordingly.
2. Using Local Rephrasing
If you prefer not to use LLM rephrasing, you can choose Local Rephrasing, which rephrases recognized characters/words based on punctuation marks. If punctuation is severely lacking, the effect may be poor.
This also applies only to the three speech recognition channels: faster-whisper, openai-whisper, and parakeet-tdt.