pyVideoTrans Technical Architecture and Implementation Principles
pyvideotrans is a powerful video translation tool designed with a modular, multi-threaded pipeline architecture to achieve efficient, stable, and scalable video processing workflows.
1. Core Processing Workflow
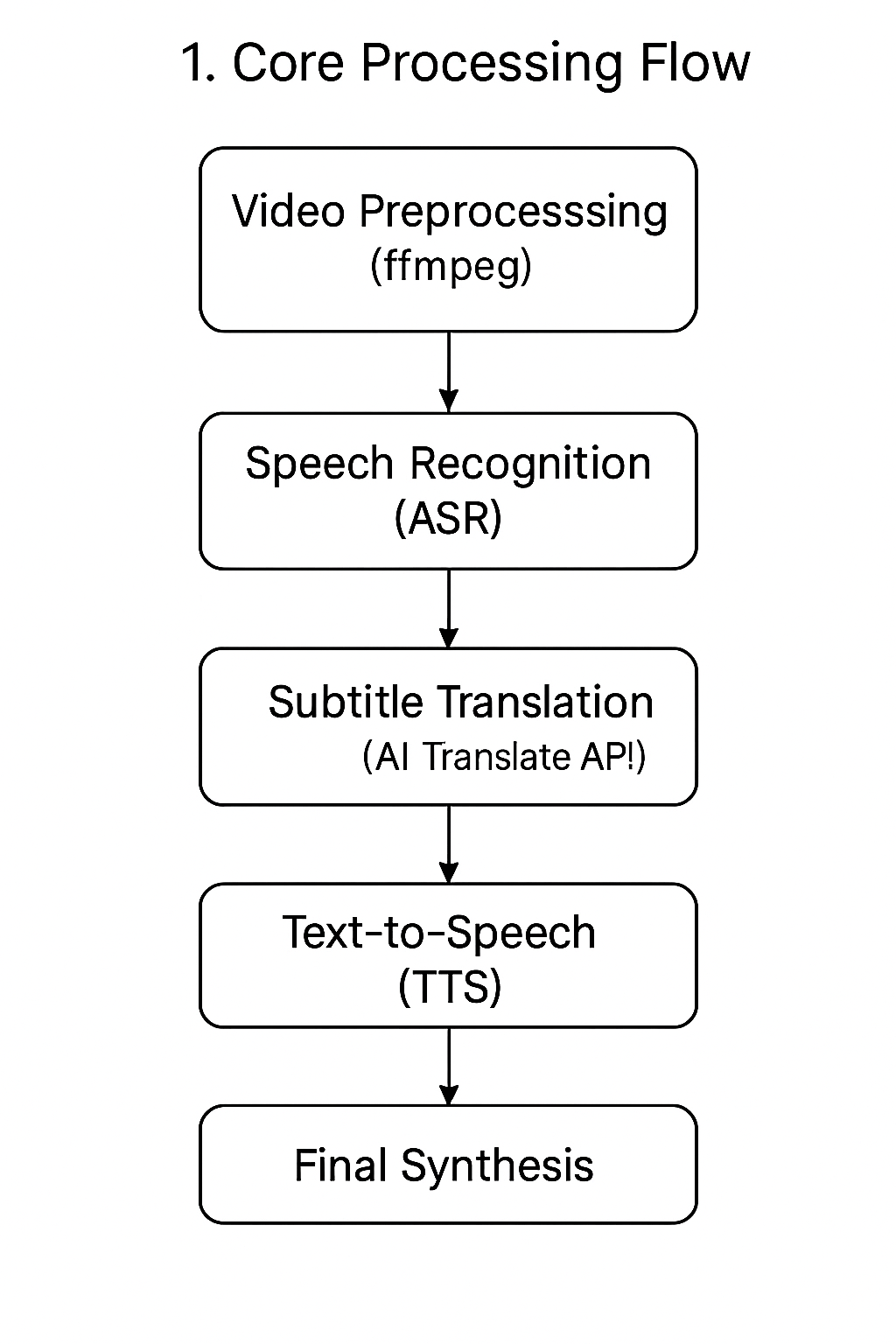
The core functionality of the software is to automatically translate a video and add target-language voiceover. The entire process is broken down into a series of independent steps, forming an automated processing pipeline:
- Video Preprocessing: First, the original video file is split into two separate parts using
ffmpeg: a silent video stream and the original audio stream. - Speech Transcription (ASR): Next, a speech recognition engine (such as the
whispermodel) is called to transcribe the extracted audio into a timestamped subtitle file (SRT format). - Subtitle Translation: The original language SRT subtitle file is translated into the target language SRT subtitle using a translation service (e.g., AI translation API).
- Text-to-Speech (TTS): Using a TTS engine, a corresponding dubbed audio file is generated based on the content and timestamps of the target language SRT subtitles.
- Final Synthesis: Finally, the silent video stream, the target language subtitle file, and the newly generated dubbed audio file are merged. Through precise timecode alignment, the final translated and dubbed video file is produced.
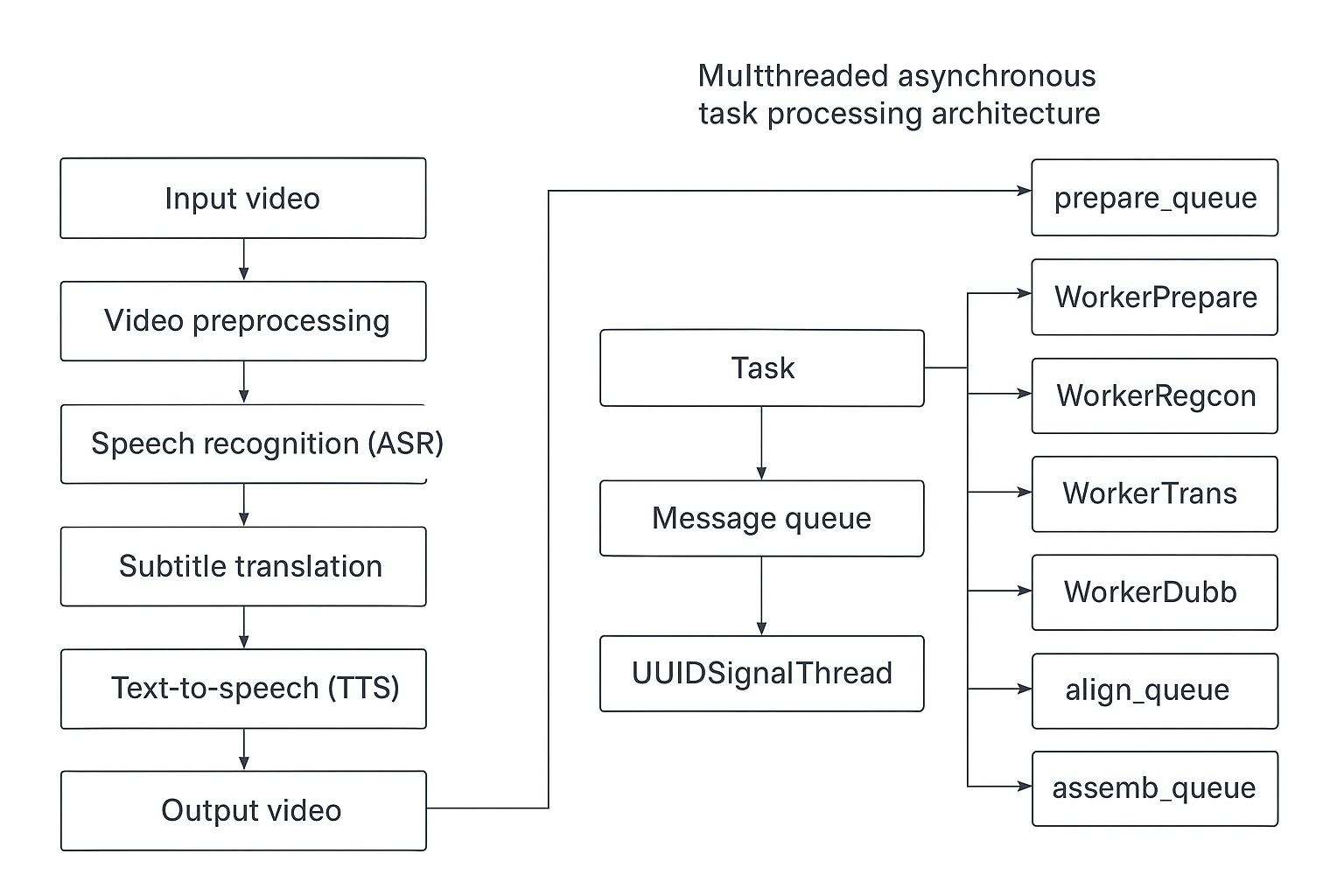
2. Multi-threaded Asynchronous Task Processing Architecture
To maintain a smooth and responsive user interface (UI) during long video processing tasks, pyvideotrans adopts a multi-threaded and multi-queue architecture based on the "producer-consumer" pattern.
When a user initiates a task (e.g., translating a video), the task flows sequentially through a pipeline composed of 7 dedicated worker threads. Each thread is responsible for a specific stage of the process and hands off data to the next thread via queues.
Task
Each audio/video file to be processed is encapsulated as a BaseTask object. This object has a unique UUID identifier and persists throughout the entire processing pipeline. The task object contains all the data and state information required for processing.
Worker Threads and Data Queues
Each worker thread continuously monitors its dedicated input queue. Once data is available in the queue, the thread retrieves it, performs its specific work, and then places the result into the input queue of the next thread.
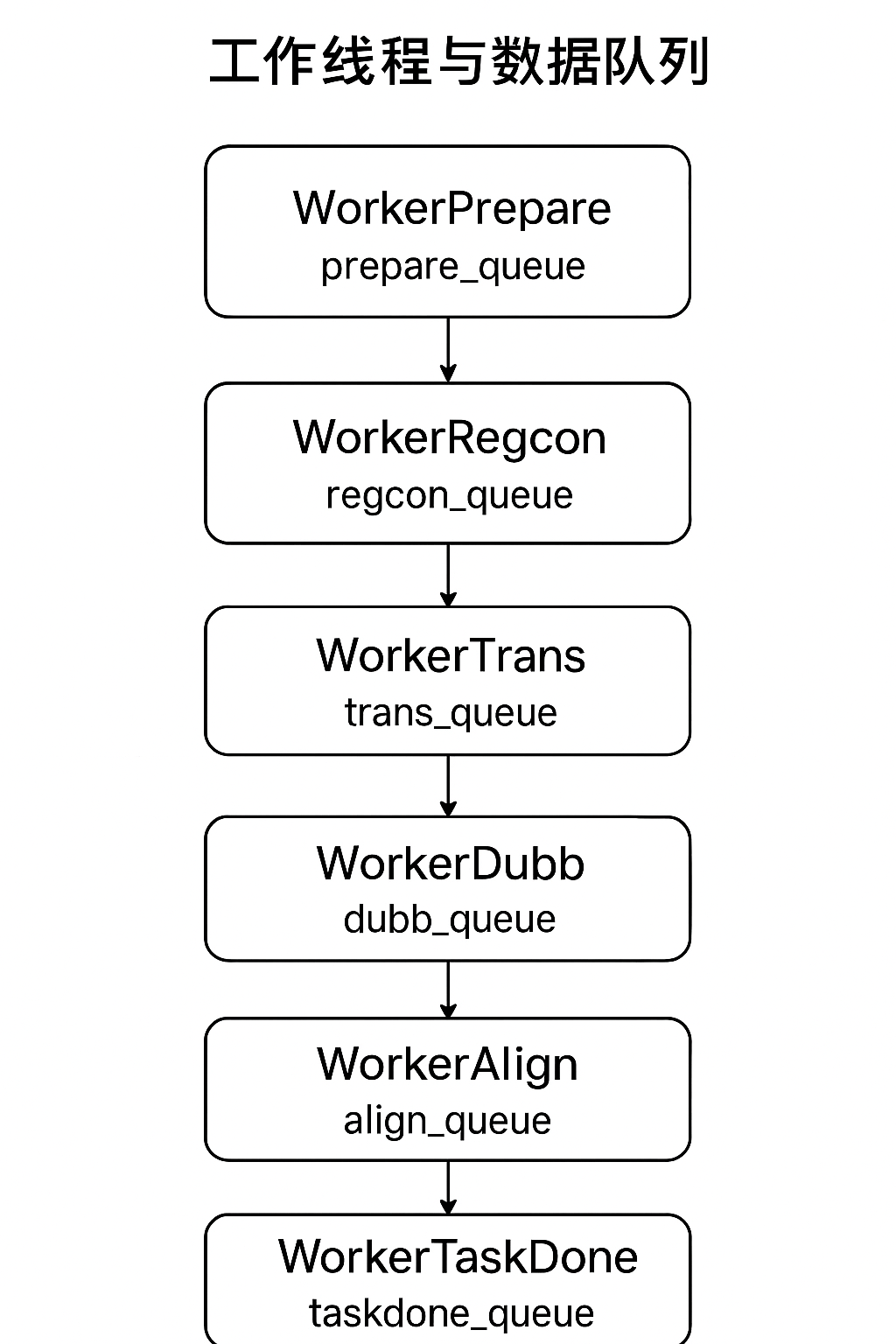
Preprocessing Thread (
WorkerPrepare):- Queue:
prepare_queue - Responsibility: Receives the original file path, performs audio/video separation, and creates temporary directories and standardized data structures required for processing. After completion, passes the task to
recogn_queue.
- Queue:
Speech Recognition Thread (
WorkerRegcon):- Queue:
regcon_queue - Responsibility: Calls the specified speech recognition module to transcribe the audio file into original language SRT subtitles. After completion, passes the task to
trans_queue.
- Queue:
Subtitle Translation Thread (
WorkerTrans):- Queue:
trans_queue - Responsibility: Translates the original SRT subtitles into the target language. After completion, passes the task to
dubb_queue.
- Queue:
Dubbing Thread (
WorkerDubb):- Queue:
dubb_queue - Responsibility: Synthesizes the dubbed audio using the TTS module based on the translated subtitles. After completion, passes the task to
align_queue.
- Queue:
Audio-Visual Alignment Thread (
WorkerAlign):- Queue:
align_queue - Responsibility: Handles complex scenarios like audio time-stretching and video slow-down to ensure final video synchronization and precise subtitle alignment. After completion, passes the task to
assemb_queue.
- Queue:
Merge & Embed Thread (
WorkerAssemb):- Queue:
assemb_queue - Responsibility: Merges the silent video, dubbed audio, and target language subtitles into a final, complete video file. After completion, passes the task to
taskdone_queue.
- Queue:
Finalization Thread (
WorkerTaskDone):- Queue:
taskdone_queue - Responsibility: Moves the final generated video file from the temporary directory to the user-specified output directory, cleans up temporary files, and sends a task completion notification to the UI.
- Queue:
Messaging & UI Update Thread (UUIDSignalThread)
In addition to the 7 worker threads, there is an independent messaging thread. Each task has its own message queue. Worker threads push progress, logs, status, and other information to this queue during execution. The messaging thread is responsible for pulling information from the message queues of active tasks and updating the main interface in real-time, keeping the user informed about task status.
Feature Customization and Process Skipping
This pipeline architecture offers high flexibility. Different software features can be implemented by "skipping" certain stages in the pipeline. Each task (BaseTask) has internal flags to control whether a specific stage is executed.
- Example 1: Video to Subtitle Feature This feature only requires speech recognition, so it skips the subtitle translation, dubbing, audio-visual alignment, and merge & embed threads.
- Example 2: Batch Dubbing for Subtitles Feature This feature starts from existing subtitle files, so it skips the speech recognition and subtitle translation threads.
3. Core Class Design and Inheritance
The software's extensibility stems from its object-oriented inheritance hierarchy, where base classes define interfaces and subclasses implement specific functionalities.
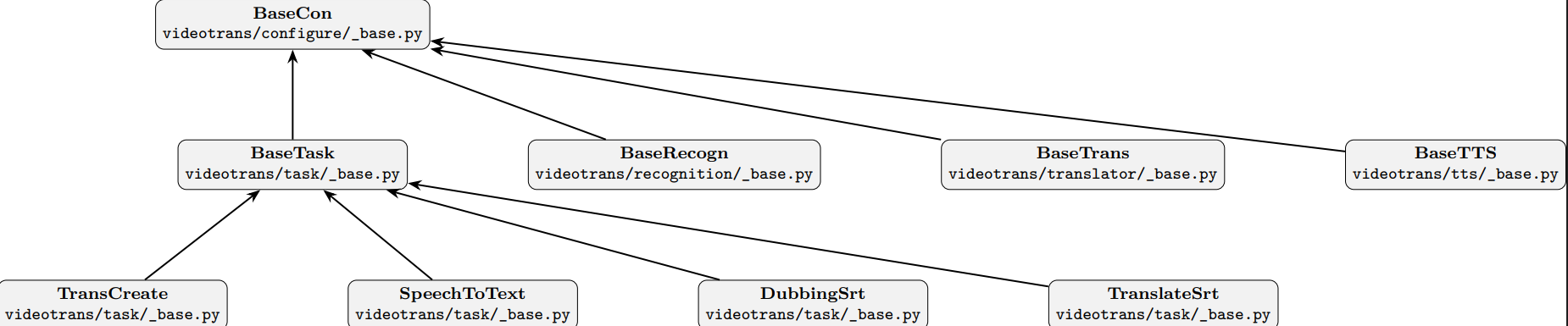
Top-level Base Class (BaseCon)
Located in videotrans/configure/_base.py, it defines common base properties and methods for all classes, such as task UUID, message sending mechanism, proxy configuration, etc.
Base Task Class (BaseTask)
Located in videotrans/task/_base.py, inherits from BaseCon. It defines the 7 core methods corresponding to the 7 worker threads, as well as flags for controlling process skipping. It also specifies the recognition, translation, and dubbing channels required by the task.
- Video Translation Task (
TransCreate): A subclass ofBaseTaskthat fully implements the logic for all 7 stages. - Audio/Video to Subtitle Task (
SpeechToText): A subclass ofBaseTaskthat only executes the preprocessing, speech recognition, and finalization stages. - Batch Dubbing for Subtitles Task (
DubbingSrt): A subclass ofBaseTaskthat only executes the preprocessing, dubbing, audio-visual alignment, and finalization stages. - Batch Translate SRT Task (
TranslateSrt): A subclass ofBaseTaskthat only executes the preprocessing, subtitle translation, and finalization stages.
Speech Recognition Class (BaseRecogn)
Located in videotrans/recognition/_base.py, it is the parent class for all speech recognition channels. During the speech recognition stage, BaseTask calls an instance of one of its subclasses to perform the work.
- Special Note: To prevent potential crashes of
faster-whisperfrom causing the entire software to exit, theFasterAllandFasterAvgsubclasses are designed to run in independent subprocesses, enhancing the stability of the main program.
Subtitle Translation Class (BaseTrans)
Located in videotrans/translator/_base.py, it is the parent class for all subtitle translation channels, providing a unified translation interface.
Dubbing Class (BaseTTS)
Located in videotrans/tts/_base.py, it is the parent class for all TTS dubbing channels.
- Its subclasses employ different concurrency strategies based on the characteristics of different TTS interfaces. For example,
EdgeTTSuses asynchronous (asyncio) concurrency within the current thread, while other subclasses handle dubbing tasks in parallel by creating multiple sub-threads.
4. Interactive Single Video Processing Mode
To meet the higher demand for subtitle accuracy when processing a single video, pyvideotrans features a unique "Interactive Single Video Processing Mode". The core of this mode is the introduction of manual intervention points within the automated workflow, allowing users to pause the task at key steps to manually proofread and correct intermediate results.
Design Motivation
When processing a single important video, users often wish to:
- Correct Speech Recognition Results: Manually fix misrecognized text after speech transcription (ASR) is complete, ensuring the accuracy of the original subtitles.
- Polish Translated Subtitle Text: Adjust and refine the machine-translated results after subtitle translation is complete, making them more contextually appropriate and idiomatic, thereby improving the quality of the final dubbing.
The traditional seven-thread pipeline architecture is designed for high-throughput batch processing, where tasks automatically flow between threads, making it unsuitable for the "execute-pause-proofread-continue" interactive requirements of a single task.
Implementation Principle
For this scenario, the software employs a different processing model:
Dedicated Worker Thread: When the user chooses to process only one video, the program starts a dedicated worker thread
Worker(QThread)(located invideotrans/task/_only_one.py) responsible for the entire workflow.Serial Execution Flow: Within this dedicated thread, the task is executed serially, step by step, rather than being passed between multiple thread queues. This ensures each step of the process strictly follows the predefined sequence.
Manual Proofreading Nodes (Pause Points): Two critical pause points are set within the workflow.
The complete serial workflow is as follows: Data Preprocessing → Speech Transcription → [Manual Proofreading Node 1] → Subtitle Translation → [Manual Proofreading Node 2] → Dubbing → Audio-Visual Alignment → Video Synthesis → Task Finalization
Pause and Resume Mechanism
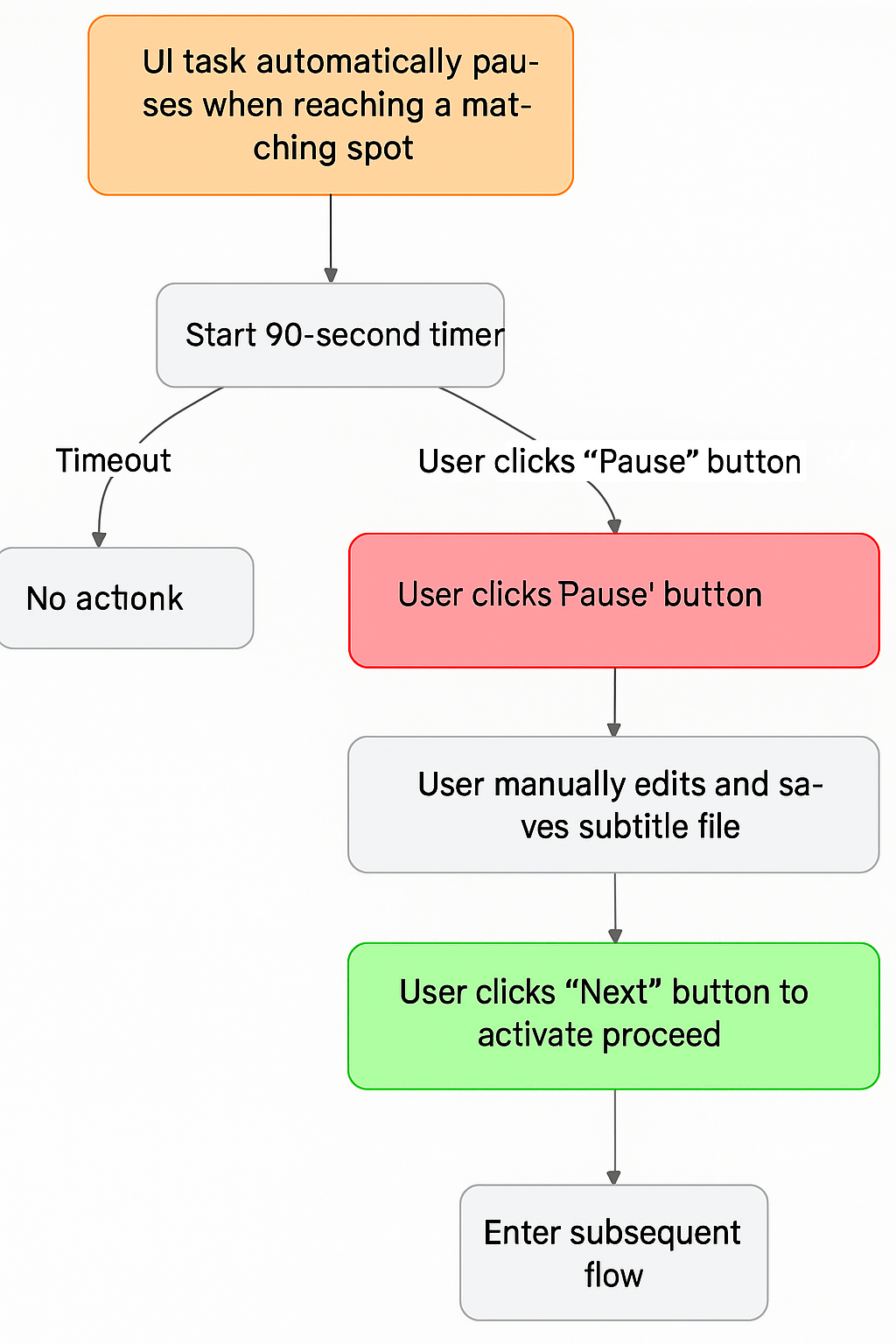
When a "Manual Proofreading Node" is reached, the task automatically pauses and provides the user with flexible interaction options:
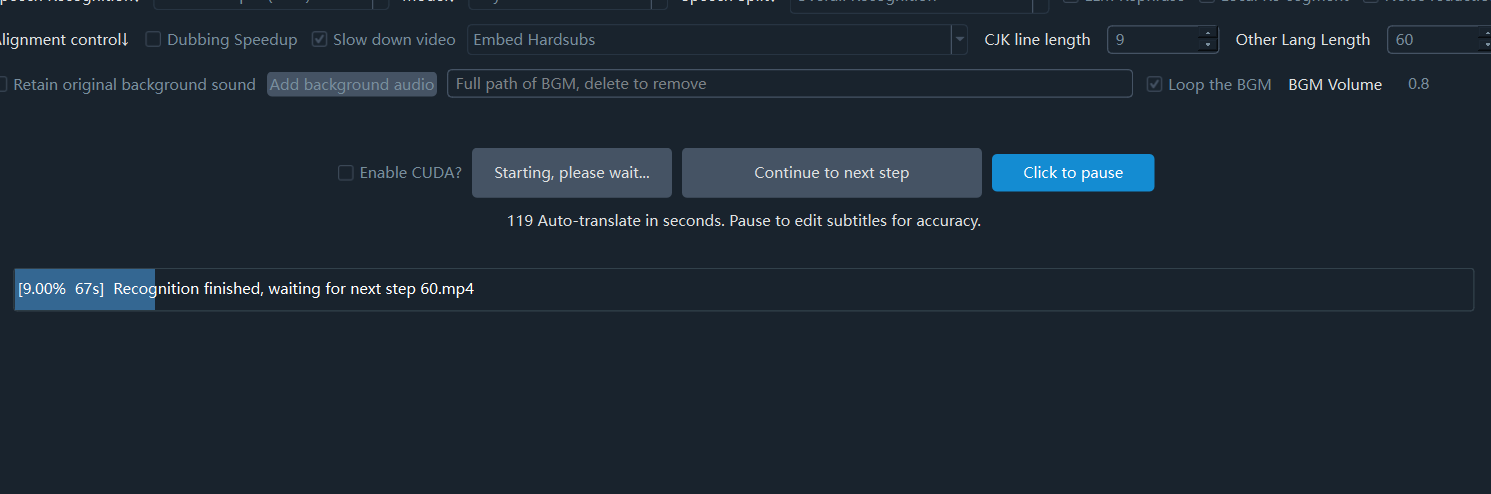
- Auto-resume Countdown: Upon pausing, the interface starts a 90-second countdown. If the user takes no action during this time, the task automatically proceeds to the next step after the countdown ends.
- Indefinite Pause: The user can click the "Pause" button on the interface at any time. The countdown then disappears, and the task enters an indefinite waiting state, giving the user ample time to edit and save the subtitle file.
- Manual Trigger to Continue: After the user completes the proofreading work, they must manually click the "Next" button to trigger the execution of the subsequent workflow.
Through this design, pyvideotrans not only ensures efficiency in batch processing but also provides the possibility for fine-grained control in single-video translation tasks where high quality is paramount.
5. Software Startup and UI Implementation
Development Framework: The software interface is developed based on the
PySide6framework.Startup Process:
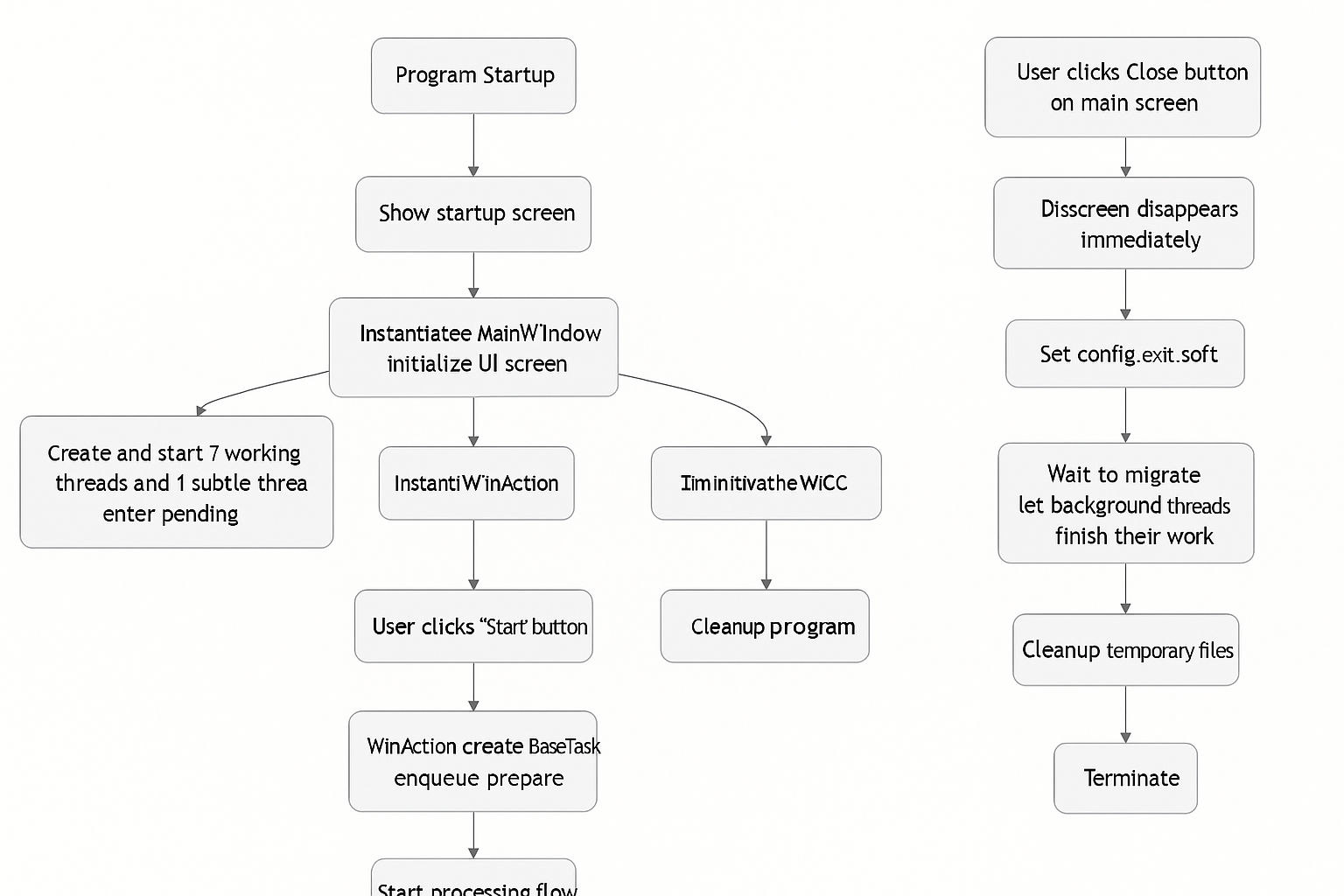
- When the program starts, a splash screen is displayed first.
- The main window class
MainWindow(videotrans/mainwin/_main_win.py) is instantiated in the background, and the UI interface is initialized. - Simultaneously, the aforementioned 7 worker threads and 1 messaging thread are created and started, putting them into a waiting state.
- The task initiation class
WinAction(videotrans/mainwin/_actions.py) is instantiated. When the user clicks the "Start" button on the interface,WinActionis responsible for creating theBaseTaskobject and pushing it into the first queue of the pipeline (prepare_queue), thereby starting the entire processing flow. - After the main interface is rendered, the splash screen is closed.
Safe Exit: When the user clicks the close button, the main interface is immediately hidden. The program sets the exit flag
config.exit_softtoTrueand waits for a few seconds, giving all background threads sufficient time to complete their current work and exit safely, before cleaning up temporary files and terminating the program.UI Structure:
- UI Definition: The layout definitions for all windows and controls are in the
videotrans/uipackage. - UI Implementation: Classes in
videotrans/component/set_form.pyare responsible for connecting the UI definitions with the business logic. - Window & Action Control: The
videotrans/winformpackage manages the creation, display, and event handling of various sub-windows, achieving decoupling between the UI and business logic.
- UI Definition: The layout definitions for all windows and controls are in the
6. Code Structure Overview
/
├── sp.py # Main program entry point
├── models/ # Directory for local AI model files
├── uvr5_weights/ # Voice/Background separation model weights
├── logs/ # Log file directory
└── videotrans/ # Core business logic code
├── component/ # UI component entry points and common widgets
├── configure/ # Configuration info, queue definitions, top-level base classes
├── language/ # UI multilingual JSON files
├── mainwin/ # Main window interface and logic
├── process/ # Independent process implementation for faster-whisper
├── prompts/ # AI prompt templates
├── recognition/ # Speech Recognition (ASR) modules
├── separate/ # Voice/Background separation modules
├── styles/ # UI styles (QSS) and icon resources
├── task/ # Various task processing logic (video translation, subtitle conversion, etc.), background thread startup entry
├── translator/ # Subtitle translation modules
├── tts/ # Text-to-Speech (TTS) modules
├── ui/ # PySide6 UI definition files
├── util/ # General utility helper functions
├── voicejson/ # TTS voice profile configuration files
└── winform/ # Logic and management for various sub-windows