This is a webui and api project for the kokoro TTS project, supporting voice synthesis in 8 languages including Chinese, English, Japanese, French, Italian, Portuguese, Spanish, and Hindi.
Project address: https://github.com/jianchang512/kokoro-uiapi
Web Interface
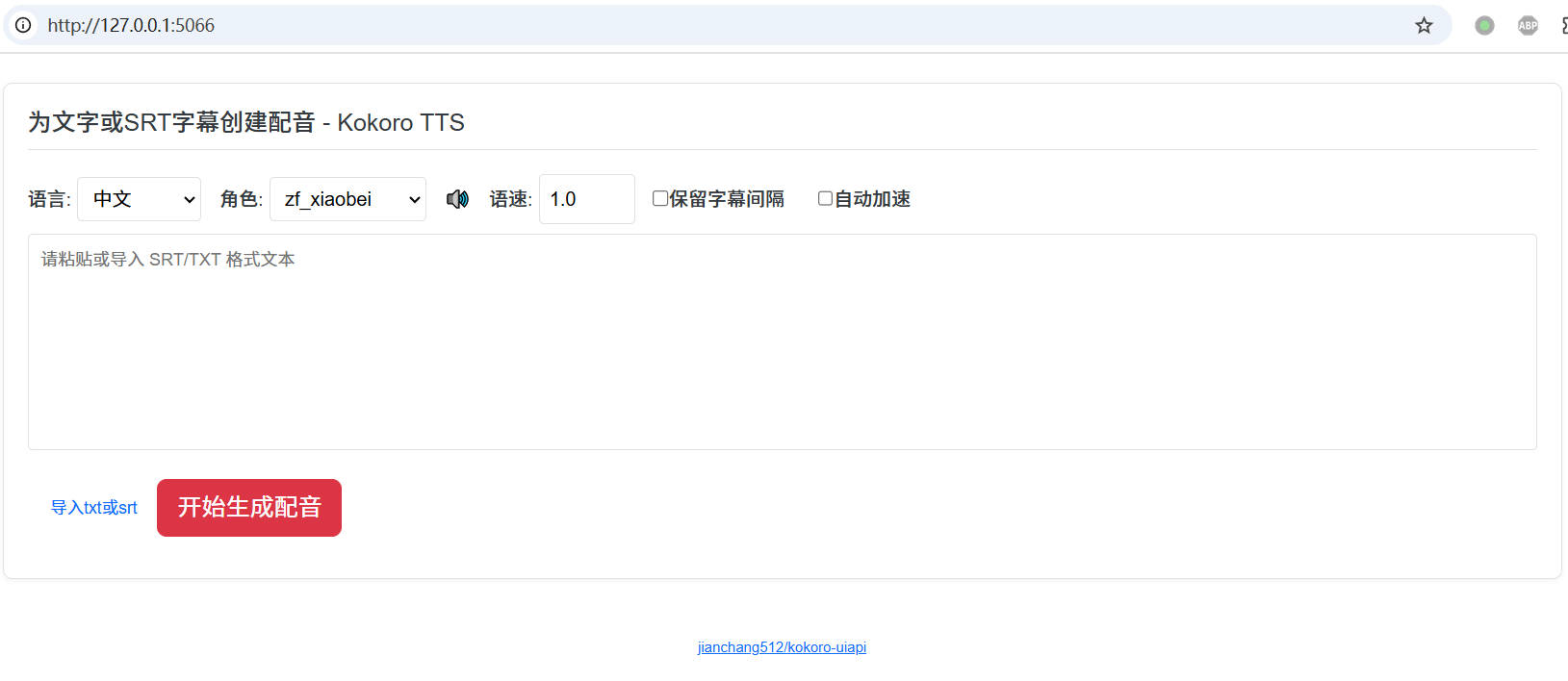
Default UI address after startup: http://127.0.0.1:5066
- Supports voice synthesis for text and SRT subtitles
- Supports online preview and download
- Supports subtitle alignment
Installation Methods
Windows
For Windows 10/11, you can directly download the integration package and double-click start.bat to start. For GPU acceleration, ensure you have an NVIDIA graphics card and install CUDA 12.
Baidu Netdisk download address: https://pan.baidu.com/s/1jTB84E3-gaLqFrl32f4sDw?pwd=xnwp
GitHub download (without models, requires VPN for online download): https://github.com/jianchang512/kokoro-uiapi/releases/download/v0.1/kokoro-uiapi-noModels-v0.2.7z
Linux/MacOS
First, ensure the system has Python 3.8+ installed; 3.10-3.11 is recommended.
On Linux, use
apt install ffmpegoryum install ffmpegto pre-install ffmpeg.On MacOS, use
brew install ffmpegto install ffmpeg.
- Clone the source code:
git clone https://github.com/jianchang512/kokoro-uiapi - Create and activate a virtual environment:
cd kokoro-uiapi python3 -m venv venv . venv/bin/activate - Install dependencies:
pip3 install -r requirements.txt - Start:
python3 app.py
Using in pyVideoTrans
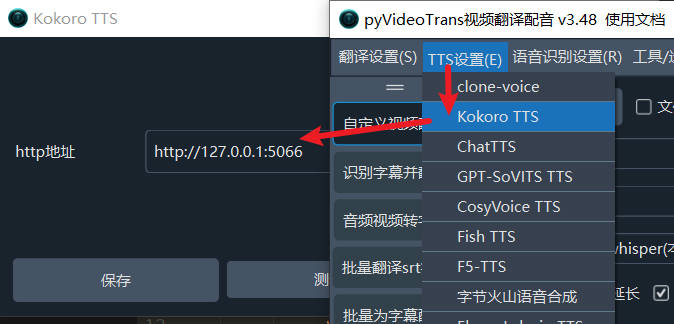
- First, start this project: double-click
start.batfor the Windows integration package, or runpython3 app.pyfor source installation. - Upgrade pyVideoTrans to v3.48+, open the menu -- TTS Settings -- Kokoro TTS -- fill in the HTTP address as
http://127.0.0.1:5066.
OpenAI API Compatibility
The API is compatible with OpenAI TTS.
Default API address after startup: http://127.0.0.1:5066/v1/audio/speech
Request method: POST Request data: application/json
{
input: text to synthesize,
voice: voice role,
speed: speech rate, default 1.0
}Returns MP3 audio data on success.
OpenAI SDK Usage Example
from openai import OpenAI
client = OpenAI(
api_key='123456',
base_url='http://127.0.0.1:5066/v1'
)
try:
response = client.audio.speech.create(
model='tts-1',
input='Hello there, dear friends',
voice='zf_xiaobei',
response_format='mp3',
speed=1.0
)
with open('./test_openai.mp3', 'wb') as f:
f.write(response.content)
print("MP3 file saved successfully to test_openai.mp3")
except Exception as e:
print(f"An error occurred: {e}")Voice Role List
English voice roles:
af_alloy
af_aoede
af_bella
af_jessica
af_kore
af_nicole
af_nova
af_river
af_sarah
af_sky
am_adam
am_echo
am_eric
am_fenrir
am_liam
am_michael
am_onyx
am_puck
am_santa
bf_alice
bf_emma
bf_isabella
bf_lily
bm_daniel
bm_fable
bm_george
bm_lewisChinese voice roles:
zf_xiaobei
zf_xiaoni
zf_xiaoxiao
zf_xiaoyi
zm_yunjian
zm_yunxi
zm_yunxia
zm_yunyangJapanese voice roles:
jf_alpha
jf_gongitsune
jf_nezumi
jf_tebukuro
jm_kumoFrench voice role: ff_siwis
Italian voice roles: if_sara, im_nicola
Hindi voice roles: hf_alpha, hf_beta, hm_omega, hm_psi
Spanish voice roles: ef_dora, em_alex, em_santa
Portuguese voice roles: pf_dora, pm_alex, pm_santa
Proxy VPN
For source code deployment, voice model pt files need to be downloaded from huggingface.co. Set up a global or system proxy in advance to ensure access.
Alternatively, download the models in advance and extract them to the directory where app.py is located.
Model download address: https://github.com/jianchang512/kokoro-uiapi/releases/download/v0.1/moxing--jieya--dao--app.py--mulu.7z