How to Use OpenAI's New Speech Recognition and Speech Synthesis Models in Video Translation
This audio is synthesized using OpenAI's new speech model for dubbing.
New Speech Transcription Models
OpenAI has just launched new speech transcription models that are more accurate than the previous whisper-1. They come in two variants: the affordable gpt-4o-mini-transcribe and the premium gpt-4o-transcribe. If you need high-quality recognition or are dealing with noisy audio or video backgrounds, consider trying the latter.
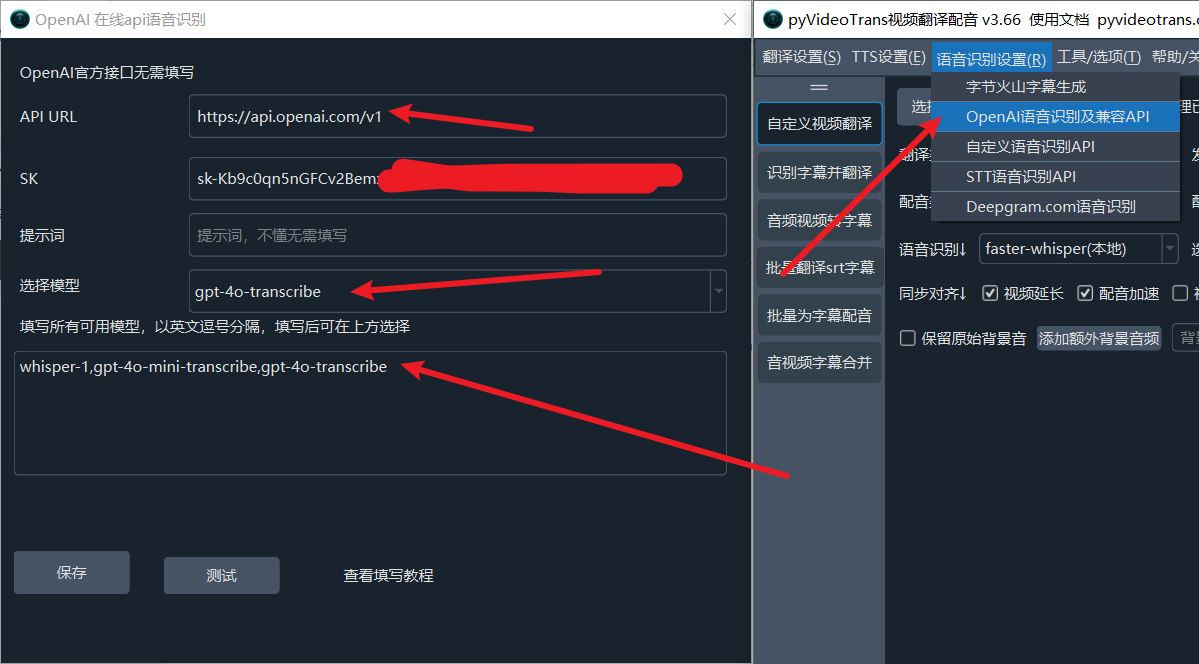
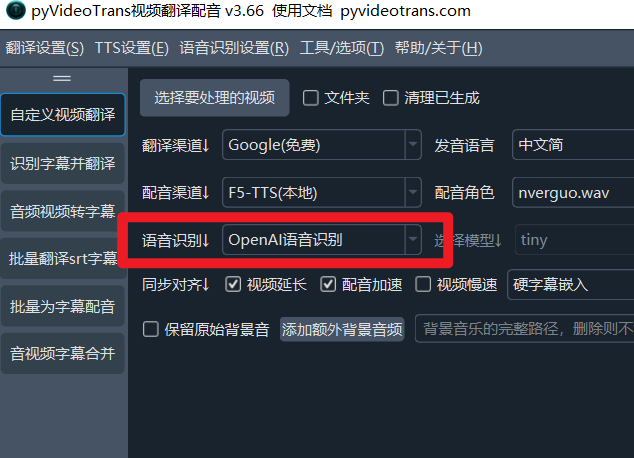
Using them is straightforward. If you're using OpenAI's official API, simply enter these two model names in Menu > Speech Recognition Settings > OpenAI Speech Recognition & Compatible API > Fill in All Models. Then, select the model you want to use, save the settings, and return to the speech recognition channel to make your selection.
New Speech Synthesis (Text-to-Speech) Model
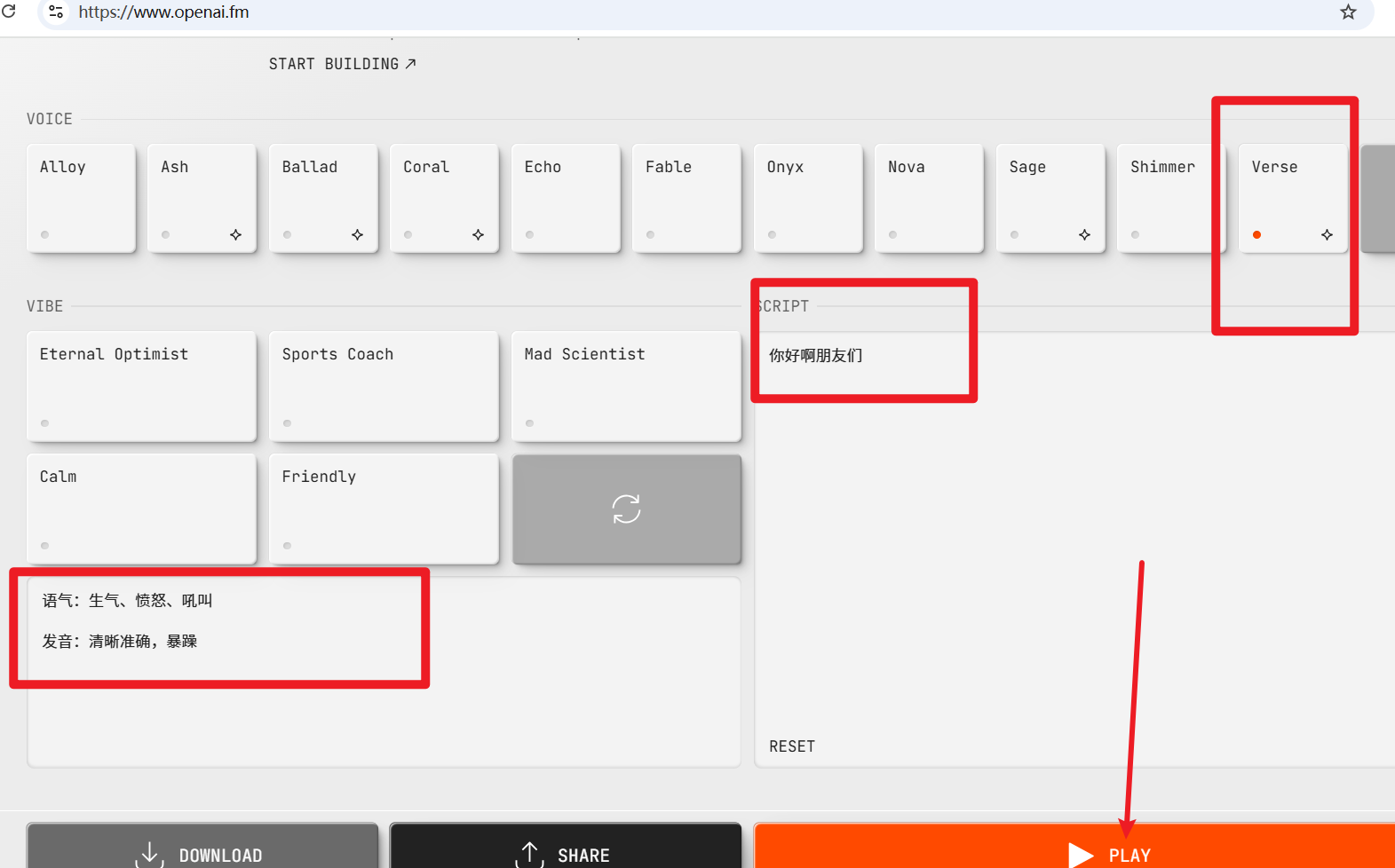
The new speech synthesis model, gpt-4o-mini-tts, performs significantly better than the previous tts-1. It also supports input prompts to set the speaking style of the voice, such as "Please speak in an excited tone" or "Imitate the emphasis of a news anchor."
You can experience it on OpenAI's free trial website:
Using it is equally simple. In the software, go to Menu > TTS Settings > OpenAI TTS > Fill in All Models and enter gpt-4o-mini-tts. Then, select the model you want to use.
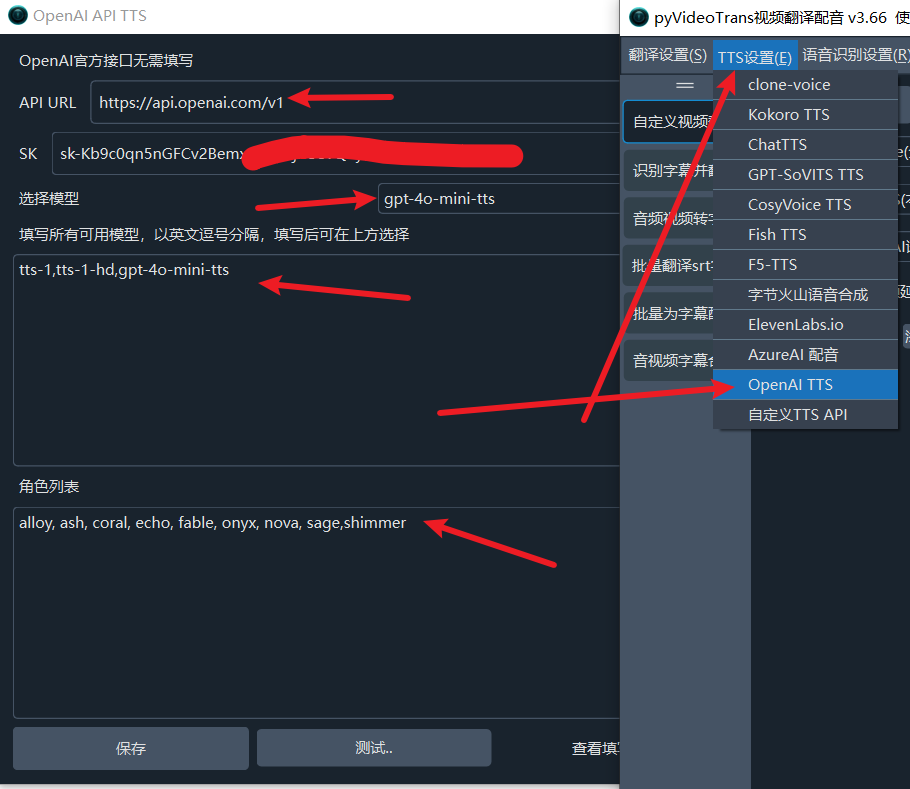
After saving, you can use it in the main interface.
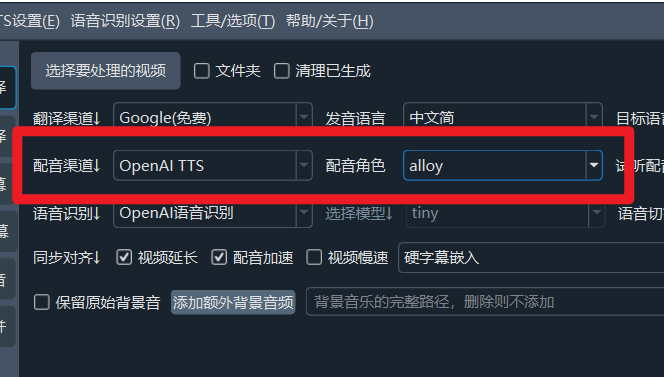
Why is there no place to input prompts? Because this is a newly released model, and the translation software hasn't been updated yet.
What About Using Third-Party Proxy Models?
The usage method is the same; just change the API address to the one provided by your third-party proxy. However, note that, as of now, most third-party proxy services do not yet support the newly added models.