Chinese Resegmentation Feature Usage
Whisper is a leading speech recognition model, but it still has significant shortcomings in Chinese recognition. Compared to English speech recognition, Whisper's performance in Chinese is notably weaker. It often outputs traditional Chinese characters and lacks punctuation, resulting in poorly segmented subtitles. Even when resegmenting using character-level timestamps, the results remain unsatisfactory if there are no clear silent intervals in the audio or video.
In contrast, Alibaba's FunASR series models excel in Chinese recognition. However, they support only a limited range of languages, specifically Chinese, and cannot handle other languages.
Therefore, in version 2.92, Alibaba's Chinese punctuation restoration model has been introduced. This model can restore punctuation in Chinese recognition results and resegment sentences based on punctuation and silent intervals. Due to the addition of this punctuation restoration model, the software size has increased by approximately 400MB.
Enabling Chinese Resegmentation
The Alibaba Chinese punctuation model will automatically be used for resegmentation when the following conditions are met:
- The "Chinese Resegmentation" option is checked on the main interface or in the audio/video to subtitle interface;
- The spoken language in the audio or video is Chinese;
- The speech recognition engine is set to "faster-whisper", "openai-whisper", or "deepgram.com";
- The segmentation mode is set to Full Recognition.
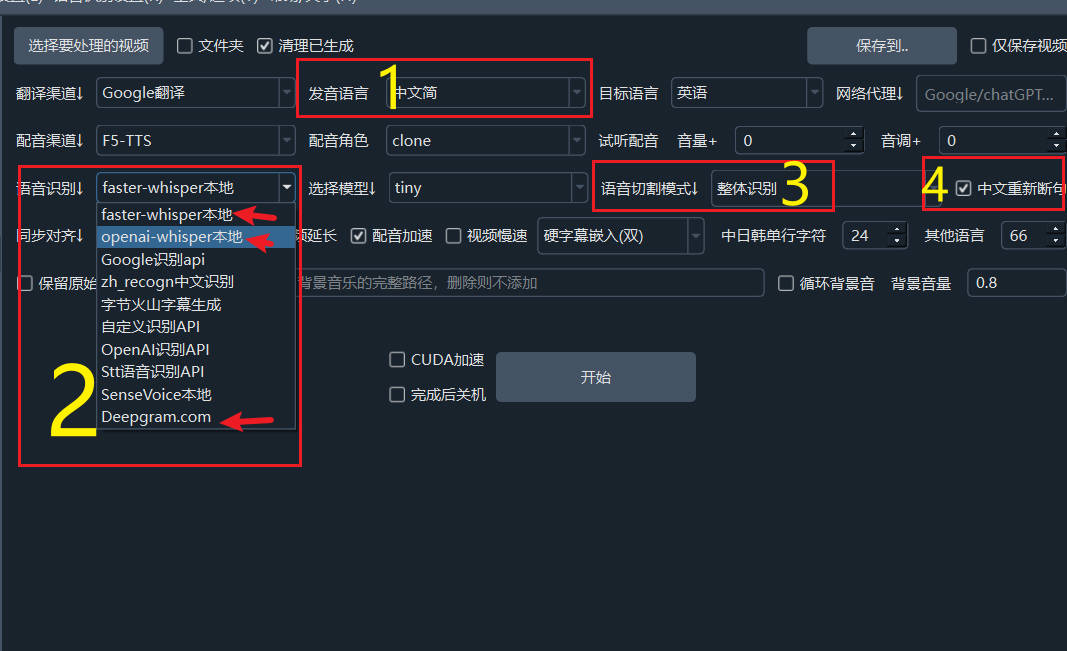
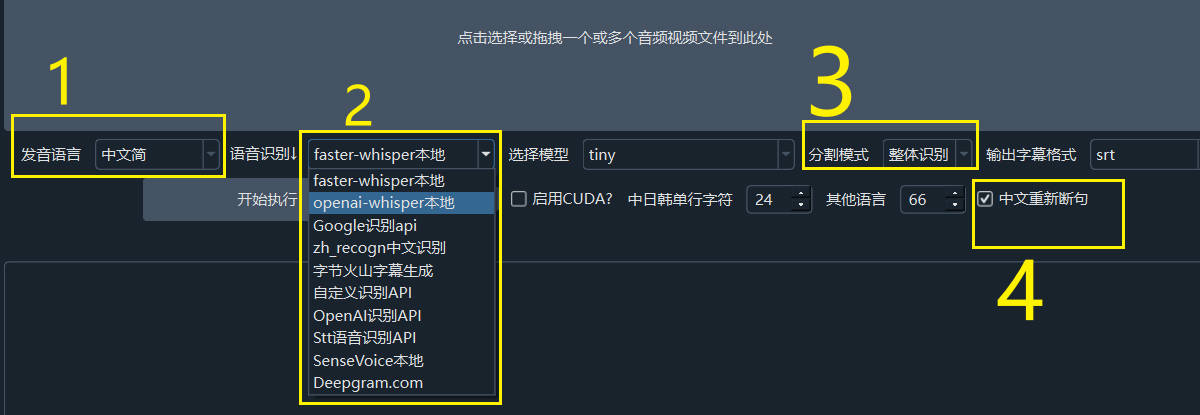
Once these conditions are satisfied, the system will restore punctuation after speech recognition is complete and then resegment sentences based on punctuation and silent intervals to improve subtitle accuracy and readability.