当AI配音遇上视频:实现音画同步的自动化工程实践
将一种语言的视频,配上另一种语言的语音,已经变得越来越普遍。无论是知识分享、影视作品还是产品介绍,好的本地化配音能极大地拉近与观众的距离。但这背后,一个棘手的问题始终存在:如何实现音画同步?
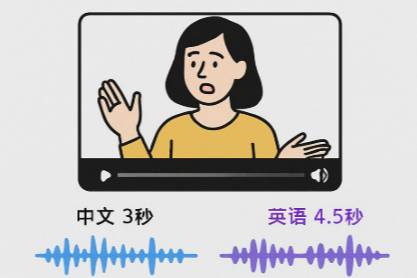
语言的差异是天生的。 一段3秒的中文对话,翻译成英语可能需要4.5秒,换成德语可能需要5秒。即便语言相同,不同的TTS(文本转语音)引擎、不同的发音人,甚至同一个发音人在不同情绪下,生成的语音时长都会有不小的差异。
这种时长的不匹配,直接导致了声音和画面上说话人的脱节。当观众看到一个人的嘴已经闭上,而声音还在继续时,那种出戏感是毁灭性的。
手动去对齐每一句配音,当然能做到完美。但面对一个有成百上千条字幕的视频,可能同时还有N多的视频等待处理,这无异于一场枯燥又耗时的噩梦。我们需要一个自动化的解决方案。
本文就将分享这样一套自动化方案的探索过程。它使用Python,并借助强大的ffmpeg和pydub库,试图在翻译配音和原始视频之间,找到一个可以被接受的同步点。并不追求像素级的完美对齐,只希望构建一个健壮、可靠、能自动执行的工程流程。在多数情况下,这个流程能生成一个听感和观感都足够自然的视频。
核心思路:在音频与视频间寻找平衡
问题的根源是时间差。当配音时长 大于 原始字幕对应的视频时长时,麻烦就来了。我们需要某种方法,“凭空”创造出额外的时间。
这个挑战只在配音过长时出现。如果配音比视频短,顶多是角色提前说完了话,嘴还在动。这在观感上相对可以接受,也不会打乱后续的时间线。但配-音过长,就会侵占下一句的播放时间,导致语音重叠或整个时间线错位。这是我们必须解决的核心矛盾。
办法无非两个:要么缩短音频,要么延长视频。
缩短音频,就是对它进行加速。Python的
pydub库提供了speedup方法,实现起来很简单。但它的缺点也很明显。当加速倍率超过1.5倍,声音就会开始变调,语速过快,听起来很怪异。超过2倍,配音基本就失去了传递信息的意义。延长视频,则是将视频慢放。
ffmpeg的setpts滤镜是实现这一目的的利器。一条setpts=2.0*PTS指令,就能让视频片段的时长延长一倍,并且过程流畅。这为我们争取了宝贵的时间。但同样,过度慢放会让画面中的人物动作像在演“慢动作”,显得拖沓、不自然。
一个好的自动化策略,必须在这两者之间找到平衡。我们最初的设想很简单:
- 如果时间差不大,比如小于1秒,这点压力就让音频自己承担。小幅度的加速,人耳通常不易察觉。
- 如果时间差比较大,那就应该让音频和视频共同分担。比如,多出来的时间,一方负责一半。音频加速一点,视频慢放一点,把两边的失真都控制在最小。
这个思路,构成了我们方案的基石。但当真正开始动手写代码时,才发现工程落地远比想象的复杂。
第一次尝试:脆弱的循环与交织的逻辑
最直观的写法,就是遍历每一条字幕。在循环里,获取配音时长,和原始时长比较。如果配音过长,就当场判断是该加速音频还是慢放视频,然后立即执行ffmpeg或pydub命令。
这种做法看似直接,却隐藏着巨大的风险。它把“计算决策”、“文件读写”、“状态更新”这些完全不同性质的操作,全都耦合在了一个大循环里。
这意味着,循环里任何一个环节出错,比如某个视频片段因为ffmpeg的一个小问题处理失败,整个流程就可能中断。即便不中断,也可能在后续的迭代中,因为状态的错乱产生无法预测的错误。
一个更健壮的架构,必须把流程解耦,拆分成几个独立的、原子化的阶段。
- 准备阶段:先完整地走一遍所有字幕,只做一件事:收集信息。把每条字幕的原始起止时间、原始时长、配音时长,以及它和下一条字幕之间的“静默间隙”时长,全都计算好,存起来。
- 决策阶段:再走一遍,这次只做计算和决策。根据我们定好的平衡策略,为每一条需要调整的字幕,算出它最终的“目标音频时长”和“目标视频时长”。这个阶段,不动任何文件。
- 执行阶段:有了明确的“施工图”,现在才开始动手。根据决策阶段的结果,批量地、甚至可以并行地处理所有音视频文件。音频加速和视频处理可以分开执行。
- 合并阶段:当所有独立的音视频片段都处理完毕后,最后一步,才是把它们按照正确的顺序拼接起来,生成最终的文件。

让每一部分的功能变得单一,代码更清晰,也更容易进行错误处理和调试。这是从“能用”到“可靠”迈出的第一步。
沉默的敌人:被吸收的间隙与误差的消除
视频的时间线是连续的。字幕和字幕之间,常常有几秒钟没有对话的“静默间隙”。这些间隙是视频叙事节奏的一部分,处理不好,整个片子就会变得很奇怪。
一个很自然的想法,是把间隙也当成一种特殊的片段来处理。字幕A结束后,到下一条字幕B开始前有2秒间隙,那我们就把这2秒的视频也切出来。
但这又带来一个新问题:如果这个间隙非常短,比如只有30毫秒呢?
ffmpeg在处理这种极短时间片段时,行为很不稳定。视频是由一帧一帧的画面构成的,一帧的时长通常在16ms到42ms之间(对应60FPS到24FPS)。你没法让ffmpeg精确地切出一个只有30ms的片段,因为它可能连一帧都不到。强行操作,结果很可能是命令失败,或者生成一个0字节的空文件。
最初我们想到的办法是“丢弃”。如果一个间隙太短,比如小于50毫-秒,那我们干脆就不要它了。但这个想法很快被我们自己否决了。一部长视频里可能有成百上千个这样的小间隙,每次都丢掉一两帧画面,累积起来,就会造成明显的“跳帧感”,画面变得不连贯。这种体验是无法接受的。
更好的策略是“吸收”
当一个字幕片段处理完后,我们向前看一眼它后面的间隙。如果这个间隙很短(小于我们设定的50ms阈值),我们就把这个微小的间隙“吸收”掉,当作是当前字幕片段的一部分。
举个例子:
- 字幕A:
00:10.000->00:12.500 - 一个40ms的微小间隙
- 字幕B:
00:12.540->00:15.000
按照 “吸收” 策略,我们在处理字幕A时,会发现它后面的间隙只有40ms。于是,我们裁切的终点不再是 12.500,而是直接延伸到 12.540。这样,这个40ms的间隙就被无缝地并入了A片段的末尾。
这样做有两大好处:
- 避免了跳帧:视频时间线是连续的,没有任何内容被丢弃。
- 提供了额外空间:A片段的原始时长从2.5秒增加到了2.54秒。如果这个片段恰好需要视频慢放,这多出来的40ms就为我们提供了宝贵的缓冲,可以稍微降低慢放的倍率,让画面更自然。
这个策略的核心,是动态地调整裁切终点,并且必须小心翼翼地维护整个时间线的推进记录,确保被吸收的间隙不会在后续被重复处理。
为失败而设计:一个有弹性的处理管道
现实世界的媒体文件,远比我们想象的要“脏”。视频可能在某个时间点有轻微的编解码错误,或者一个不合理的慢放参数(比如对一个本身就短的片段进行超高倍率慢放)都可能让ffmpeg处理失败。如果我们的程序因为一个片段的失败就全线崩溃,那它在工程上就是失败的。
我们必须为失败而设计。在视频处理的执行阶段,引入 尝试-检查-回退 的机制。
流程如下:
- 尝试:对一个片段,执行我们计算好的
ffmpeg裁切命令,这可能带有变速参数。 - 检查:命令执行后,立刻检查输出文件是否存在,且大小是否大于0。
- 回退:如果检查失败,日志会记录一条警告。然后,程序会立刻再次调用
ffmpeg,但这一次用的是 安全模式——完全不带变速参数,只按原始速度裁切。
这个回退机制保证了,即便我们对某个片段的慢放操作失败了,我们至少还能得到一个时长正确的原始片段,保全了整个视频时间线的完整性,避免了后续所有片段的错位。
最终的架构:一个灵活、解耦的SpeedRate类
经过反复的迭代和优化,最终形成了一个相对健壮的SpeedRate类。它将整个复杂的同步过程,封装成了一个清晰、可靠的执行流。下面,我们来看一下它的关键部分是如何协同工作的。
import os
import shutil
import time
from pathlib import Path
import concurrent.futures
from pydub import AudioSegment
from pydub.exceptions import CouldntDecodeError
from videotrans.configure import config
from videotrans.util import tools
class SpeedRate:
"""
通过音频加速和视频慢放来对齐翻译配音和原始视频时间轴。
V10 更新日志:
- 【策略优化】引入微小间隙“吸收”策略,替代原有的“丢弃”策略。
当一个字幕片段后的间隙小于阈值时,该间隙将被并入前一个字幕片段进行处理,
避免了“跳帧”现象,并为视频慢速提供了额外时长。
- 相应地调整了 video_pts 的计算逻辑,以适应动态变化的片段时长。
"""
MIN_CLIP_DURATION_MS = 50 # 最小有效片段时长(毫秒)
def __init__(self,
*,
queue_tts=None,
shoud_videorate=False,
shoud_audiorate=False,
uuid=None,
novoice_mp4=None,
raw_total_time=0,
noextname=None,
target_audio=None,
cache_folder=None
):
self.queue_tts = queue_tts
self.shoud_videorate = shoud_videorate
self.shoud_audiorate = shoud_audiorate
self.uuid = uuid
self.novoice_mp4_original = novoice_mp4
self.novoice_mp4 = novoice_mp4
self.raw_total_time = raw_total_time
self.noextname = noextname
self.target_audio = target_audio
self.cache_folder = cache_folder if cache_folder else Path(f'{config.TEMP_DIR}/{str(uuid if uuid else time.time())}').as_posix()
Path(self.cache_folder).mkdir(parents=True, exist_ok=True)
self.max_audio_speed_rate = max(1.0, float(config.settings.get('audio_rate', 5.0)))
self.max_video_pts_rate = max(1.0, float(config.settings.get('video_rate', 10.0)))
config.logger.info(f"SpeedRate initialized for '{self.noextname}'. AudioRate: {self.shoud_audiorate}, VideoRate: {self.shoud_videorate}")
config.logger.info(f"Config limits: MaxAudioSpeed={self.max_audio_speed_rate}, MaxVideoPTS={self.max_video_pts_rate}, MinClipDuration={self.MIN_CLIP_DURATION_MS}ms")
def run(self):
"""主执行函数"""
self._prepare_data()
self._calculate_adjustments()
self._execute_audio_speedup()
self._execute_video_processing()
merged_audio = self._recalculate_timeline_and_merge_audio()
if merged_audio:
self._finalize_audio(merged_audio)
return self.queue_tts
def _prepare_data(self):
"""第一步:准备和初始化数据。"""
tools.set_process(text="Preparing data...", uuid=self.uuid)
# 第一阶段:初始化独立数据
for it in self.queue_tts:
it['start_time_source'] = it['start_time']
it['end_time_source'] = it['end_time']
it['source_duration'] = it['end_time_source'] - it['start_time_source']
it['dubb_time'] = int(tools.get_audio_time(it['filename']) * 1000) if tools.vail_file(it['filename']) else 0
it['target_audio_duration'] = it['dubb_time']
it['target_video_duration'] = it['source_duration']
it['video_pts'] = 1.0
# 第二阶段:计算间隙
for i, it in enumerate(self.queue_tts):
if i < len(self.queue_tts) - 1:
next_item = self.queue_tts[i + 1]
it['silent_gap'] = next_item['start_time_source'] - it['end_time_source']
else:
it['silent_gap'] = self.raw_total_time - it['end_time_source']
it['silent_gap'] = max(0, it['silent_gap'])
def _calculate_adjustments(self):
"""第二步:计算调整方案。"""
tools.set_process(text="Calculating adjustments...", uuid=self.uuid)
for i, it in enumerate(self.queue_tts):
if it['dubb_time'] > it['source_duration'] and tools.vail_file(it['filename']):
try:
original_dubb_time = it['dubb_time']
_, new_dubb_length_ms = tools.remove_silence_from_file(
it['filename'], silence_threshold=-50.0, chunk_size=10, is_start=True)
it['dubb_time'] = new_dubb_length_ms
if original_dubb_time != it['dubb_time']:
config.logger.info(f"Removed silence from {Path(it['filename']).name}: duration reduced from {original_dubb_time}ms to {it['dubb_time']}ms.")
except Exception as e:
config.logger.warning(f"Could not remove silence from {it['filename']}: {e}")
# 吸收微小间隙后,可用的视频时长可能会增加
effective_source_duration = it['source_duration']
if it.get('silent_gap', 0) < self.MIN_CLIP_DURATION_MS:
effective_source_duration += it['silent_gap']
if it['dubb_time'] <= effective_source_duration or effective_source_duration <= 0:
continue
dub_duration = it['dubb_time']
# 使用有效时长进行计算
source_duration = effective_source_duration
silent_gap = it['silent_gap']
over_time = dub_duration - source_duration
# 决策逻辑现在基于 `effective_source_duration`
if self.shoud_audiorate and not self.shoud_videorate:
required_speed = dub_duration / source_duration
if required_speed <= 1.5:
it['target_audio_duration'] = source_duration
else:
# 注意:这里的silent_gap在吸收后实际已经为0,但为了逻辑完整性保留
available_time = source_duration + (silent_gap if silent_gap >= self.MIN_CLIP_DURATION_MS else 0)
duration_at_1_5x = dub_duration / 1.5
it['target_audio_duration'] = duration_at_1_5x if duration_at_1_5x <= available_time else available_time
elif not self.shoud_audiorate and self.shoud_videorate:
required_pts = dub_duration / source_duration
if required_pts <= 1.5:
it['target_video_duration'] = dub_duration
else:
available_time = source_duration + (silent_gap if silent_gap >= self.MIN_CLIP_DURATION_MS else 0)
duration_at_1_5x = source_duration * 1.5
it['target_video_duration'] = duration_at_1_5x if duration_at_1_5x <= available_time else available_time
elif self.shoud_audiorate and self.shoud_videorate:
if over_time <= 1000:
it['target_audio_duration'] = source_duration
else:
adjustment_share = over_time // 2
it['target_audio_duration'] = dub_duration - adjustment_share
it['target_video_duration'] = source_duration + adjustment_share
# 安全校验和PTS计算
if it['target_audio_duration'] < dub_duration:
speed_ratio = dub_duration / it['target_audio_duration']
if speed_ratio > self.max_audio_speed_rate: it['target_audio_duration'] = dub_duration / self.max_audio_speed_rate
if it['target_video_duration'] > source_duration:
pts_ratio = it['target_video_duration'] / source_duration
if pts_ratio > self.max_video_pts_rate: it['target_video_duration'] = source_duration * self.max_video_pts_rate
# pts需要基于最终裁切的原始视频时长来计算
it['video_pts'] = max(1.0, it['target_video_duration'] / source_duration)
def _process_single_audio(self, item):
"""处理单个音频文件的加速任务"""
input_file_path = item['filename']
target_duration_ms = int(item['target_duration_ms'])
try:
audio = AudioSegment.from_file(input_file_path)
current_duration_ms = len(audio)
if target_duration_ms <= 0 or current_duration_ms <= target_duration_ms: return input_file_path, current_duration_ms, ""
speedup_ratio = current_duration_ms / target_duration_ms
fast_audio = audio.speedup(playback_speed=speedup_ratio)
config.logger.info(f'音频加速处理:{speedup_ratio=}')
fast_audio.export(input_file_path, format=Path(input_file_path).suffix[1:])
item['ref']['dubb_time'] = len(fast_audio)
return input_file_path, len(fast_audio), ""
except Exception as e:
config.logger.error(f"Error processing audio {input_file_path}: {e}")
return input_file_path, None, str(e)
def _execute_audio_speedup(self):
"""第三步:执行音频加速。"""
if not self.shoud_audiorate: return
tasks = [
{"filename": it['filename'], "target_duration_ms": it['target_audio_duration'], "ref": it}
for it in self.queue_tts if it.get('dubb_time', 0) > it.get('target_audio_duration', 0) and tools.vail_file(it['filename'])
]
if not tasks: return
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(self._process_single_audio, task) for task in tasks]
for i, future in enumerate(concurrent.futures.as_completed(futures)):
if config.exit_soft: executor.shutdown(wait=False, cancel_futures=True); return
future.result()
tools.set_process(text=f"Audio processing: {i + 1}/{len(tasks)}", uuid=self.uuid)
def _execute_video_processing(self):
"""第四步:执行视频裁切(采用微小间隙吸收策略)。"""
if not self.shoud_videorate or not self.novoice_mp4_original:
return
video_tasks = []
processed_video_clips = []
last_end_time = 0
i = 0
while i < len(self.queue_tts):
it = self.queue_tts[i]
# 处理字幕片段前的间隙
gap_before = it['start_time_source'] - last_end_time
if gap_before > self.MIN_CLIP_DURATION_MS:
clip_path = Path(f'{self.cache_folder}/{i:05d}_gap.mp4').as_posix()
video_tasks.append({"ss": tools.ms_to_time_string(ms=last_end_time), "to": tools.ms_to_time_string(ms=it['start_time_source']), "source": self.novoice_mp4_original, "pts": 1.0, "out": clip_path})
processed_video_clips.append(clip_path)
# 确定当前字幕片段的裁切终点
start_ss = it['start_time_source']
end_to = it['end_time_source']
# V10 核心逻辑:向前看,决定是否吸收下一个间隙
if i + 1 < len(self.queue_tts):
next_it = self.queue_tts[i+1]
gap_after = next_it['start_time_source'] - it['end_time_source']
if 0 < gap_after < self.MIN_CLIP_DURATION_MS:
end_to = next_it['start_time_source'] # 延伸裁切终点
config.logger.info(f"Absorbing small gap ({gap_after}ms) after segment {i} into the clip.")
current_clip_source_duration = end_to - start_ss
# 只有当片段有效时才创建任务
if current_clip_source_duration > self.MIN_CLIP_DURATION_MS:
clip_path = Path(f"{self.cache_folder}/{i:05d}_sub.mp4").as_posix()
# 如果需要变速,可能需要重新计算pts
pts_val = it.get('video_pts', 1.0)
if pts_val > 1.01:
# 新的pts = 目标时长 / 新的源时长
new_target_duration = it.get('target_video_duration', current_clip_source_duration)
pts_val = max(1.0, new_target_duration / current_clip_source_duration)
video_tasks.append({"ss": tools.ms_to_time_string(ms=start_ss), "to": tools.ms_to_time_string(ms=end_to), "source": self.novoice_mp4_original, "pts": pts_val, "out": clip_path})
processed_video_clips.append(clip_path)
last_end_time = end_to
i += 1
# 处理结尾的最后一个间隙
if (final_gap := self.raw_total_time - last_end_time) > self.MIN_CLIP_DURATION_MS:
clip_path = Path(f'{self.cache_folder}/zzzz_final_gap.mp4').as_posix()
video_tasks.append({"ss": tools.ms_to_time_string(ms=last_end_time), "to": "", "source": self.novoice_mp4_original, "pts": 1.0, "out": clip_path})
processed_video_clips.append(clip_path)
# ... (后续的执行、合并逻辑与之前版本相同) ...
for j, task in enumerate(video_tasks):
if config.exit_soft: return
tools.set_process(text=f"Video processing: {j + 1}/{len(video_tasks)}", uuid=self.uuid)
the_pts = task['pts'] if task.get('pts', 1.0) > 1.01 else ""
config.logger.info(f'视频慢速:{the_pts=},处理后输出视频片段={task["out"]}')
tools.cut_from_video(ss=task['ss'], to=task['to'], source=task['source'], pts=the_pts, out=task['out'])
output_path = Path(task['out'])
if not output_path.exists() or output_path.stat().st_size == 0:
config.logger.warning(f"Segment {task['out']} failed to generate (PTS={task.get('pts', 1.0)}). Fallback to original speed.")
tools.cut_from_video(ss=task['ss'], to=task['to'], source=task['source'], pts="", out=task['out'])
if not output_path.exists() or output_path.stat().st_size == 0:
config.logger.error(f"FATAL: Fallback for {task['out']} also failed. Segment will be MISSING.")
valid_clips = [clip for clip in processed_video_clips if Path(clip).exists() and Path(clip).stat().st_size > 0]
if not valid_clips:
config.logger.warning("No valid video clips generated to merge. Skipping video merge.")
self.novoice_mp4 = self.novoice_mp4_original
return
concat_txt_path = Path(f'{self.cache_folder}/concat_list.txt').as_posix()
tools.create_concat_txt(valid_clips, concat_txt=concat_txt_path)
merged_video_path = Path(f'{self.cache_folder}/merged_{self.noextname}.mp4').as_posix()
tools.set_process(text="Merging video clips...", uuid=self.uuid)
tools.concat_multi_mp4(out=merged_video_path, concat_txt=concat_txt_path)
self.novoice_mp4 = merged_video_path
def _recalculate_timeline_and_merge_audio(self):
"""第五步:重新计算时间线并合并音频。"""
merged_audio = AudioSegment.empty()
video_was_processed = self.shoud_videorate and self.novoice_mp4_original and Path(self.novoice_mp4).name.startswith("merged_")
if video_was_processed:
config.logger.info("Building audio timeline based on processed video clips.")
current_timeline_ms = 0
try:
sorted_clips = sorted([f for f in os.listdir(self.cache_folder) if f.endswith(".mp4") and ("_sub" in f or "_gap" in f)])
except FileNotFoundError: return None
for clip_filename in sorted_clips:
clip_path = Path(f'{self.cache_folder}/{clip_filename}').as_posix()
try:
if not (Path(clip_path).exists() and Path(clip_path).stat().st_size > 0): continue
clip_duration = tools.get_video_duration(clip_path)
except Exception as e:
config.logger.warning(f"Could not get duration for clip {clip_path} (error: {e}). Skipping.")
continue
if "_sub" in clip_filename:
index = int(clip_filename.split('_')[0])
it = self.queue_tts[index]
it['start_time'] = current_timeline_ms
segment = AudioSegment.from_file(it['filename']) if tools.vail_file(it['filename']) else AudioSegment.silent(duration=clip_duration)
if len(segment) > clip_duration: segment = segment[:clip_duration]
elif len(segment) < clip_duration: segment += AudioSegment.silent(duration=clip_duration - len(segment))
merged_audio += segment
it['end_time'] = current_timeline_ms + clip_duration
it['startraw'], it['endraw'] = tools.ms_to_time_string(ms=it['start_time']), tools.ms_to_time_string(ms=it['end_time'])
else: # gap
merged_audio += AudioSegment.silent(duration=clip_duration)
current_timeline_ms += clip_duration
else:
# 此处的B模式逻辑保持不变,因为它不处理视频,不存在吸收间隙的问题
config.logger.info("Building audio timeline based on original timings (video not processed).")
last_end_time = 0
for i, it in enumerate(self.queue_tts):
silence_duration = it['start_time_source'] - last_end_time
if silence_duration > 0: merged_audio += AudioSegment.silent(duration=silence_duration)
it['start_time'] = len(merged_audio)
dubb_time = int(tools.get_audio_time(it['filename']) * 1000) if tools.vail_file(it['filename']) else it['source_duration']
segment = AudioSegment.from_file(it['filename']) if tools.vail_file(it['filename']) else AudioSegment.silent(duration=dubb_time)
if len(segment) > dubb_time: segment = segment[:dubb_time]
elif len(segment) < dubb_time: segment += AudioSegment.silent(duration=dubb_time - len(segment))
merged_audio += segment
it['end_time'] = len(merged_audio)
last_end_time = it['end_time_source']
it['startraw'], it['endraw'] = tools.ms_to_time_string(ms=it['start_time']), tools.ms_to_time_string(ms=it['end_time'])
return merged_audio
def _export_audio(self, audio_segment, destination_path):
"""将Pydub音频段导出到指定路径,处理不同格式。"""
wavfile = Path(f'{self.cache_folder}/temp_{time.time_ns()}.wav').as_posix()
try:
audio_segment.export(wavfile, format="wav")
ext = Path(destination_path).suffix.lower()
if ext == '.wav':
shutil.copy2(wavfile, destination_path)
elif ext == '.m4a':
tools.wav2m4a(wavfile, destination_path)
else: # .mp3
tools.runffmpeg(["-y", "-i", wavfile, "-ar", "48000", "-b:a", "192k", destination_path])
finally:
if Path(wavfile).exists():
os.remove(wavfile)
def _finalize_audio(self, merged_audio):
"""第六步:导出并对齐最终音视频时长(仅在视频被处理时)。"""
tools.set_process(text="Exporting and finalizing audio...", uuid=self.uuid)
try:
self._export_audio(merged_audio, self.target_audio)
video_was_processed = self.shoud_videorate and self.novoice_mp4_original and Path(self.novoice_mp4).name.startswith("merged_")
if not video_was_processed:
config.logger.info("Skipping duration alignment as video was not processed.")
return
if not (tools.vail_file(self.novoice_mp4) and tools.vail_file(self.target_audio)):
config.logger.warning("Final video or audio file not found, skipping duration alignment.")
return
video_duration_ms = tools.get_video_duration(self.novoice_mp4)
audio_duration_ms = int(tools.get_audio_time(self.target_audio) * 1000)
padding_needed = video_duration_ms - audio_duration_ms
if padding_needed > 10:
config.logger.info(f"Audio is shorter than video by {padding_needed}ms. Padding with silence.")
final_audio_segment = AudioSegment.from_file(self.target_audio)
final_audio_segment += AudioSegment.silent(duration=padding_needed)
self._export_audio(final_audio_segment, self.target_audio)
elif padding_needed < -10:
config.logger.warning(f"Final audio is longer than video by {-padding_needed}ms. This may cause sync issues.")
except Exception as e:
config.logger.error(f"Failed to export or finalize audio: {e}")
raise RuntimeError(f"Failed to finalize audio: {e}")
config.logger.info("Final audio merged and aligned successfully.")代码解读
__init__: 初始化所有参数,并定义了MIN_CLIP_DURATION_MS这个关键常量,它是我们所有微小片段处理策略的基础。_prepare_data: 采用健壮的两阶段方法来准备数据,彻底解决了在单次循环中“向前看”可能导致的KeyError。_calculate_adjustments: 决策核心。它首先尝试通过移除配音首尾的“水份”(静音)来减轻后续处理的压力,然后再根据我们的平衡策略进行计算。_execute_audio_speedup: 利用多线程并行处理所有需要加速的音频,提升效率。_execute_video_processing: 这是整个流程中最复杂、也是最能体现工程实践的部分。它实现了更优的“吸收”策略来保证画面的连续性,同时内置了“尝试-检查-回退”的容错机制,是整个流程稳定性的基石。_recalculate_timeline_and_merge_audio: 这个方法的设计非常灵活。它能自动判断视频是否被实际处理过,并选择不同的模式来构建最终的音频时间线。这种设计使得这个类既能处理复杂的音视频同步任务,也能胜任纯音频的拼接工作。_finalize_audio: 最后的“品控”环节。如果视频被处理过,它会确保最终生成的音轨和视频时长完全一致,这是一个专业流程中必不可少的细节。
可用,但远非完美
音画同步,特别是跨语言的音画同步,是一个充满细节和挑战的领域。本文提出的这套自动化方案,不是终点,也无法完全替代专业人士的精细调整。它的价值在于,通过一系列精心设计的工程实践——逻辑解耦、吸收策略、容错回退——我们构建了一个足够“聪明”和“皮实”的自动化流程。它能处理绝大多数场景,并优雅地绕过那些足以让简单脚本崩溃的陷阱。
它是一个在“完美效果”和“工程可行性”之间取得实用平衡的产物。对于需要大批量、快速处理视频配音的场景,它提供了一个可靠的起点,能自动化地完成80%的工作,生成一个质量可接受的初版。剩下的20%,则可以留给人工进行最终的画龙点睛。
