When AI Dubbing Meets Video: Automated Engineering Practices for Achieving Audio-Visual Synchronization
Dubbing videos from one language into another has become increasingly common. Whether for knowledge sharing, film and television, or product introductions, good localized dubbing can greatly bridge the gap with the audience. However, a persistent challenge remains: how to achieve audio-visual synchronization?
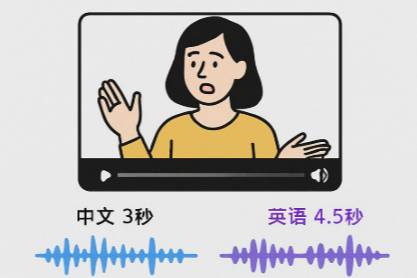
Language differences are inherent. A 3-second Chinese dialogue may take 4.5 seconds when translated into English, and possibly 5 seconds in German. Even within the same language, different TTS engines, different speakers, or the same speaker under different emotions can result in significant variations in speech duration.
This timing mismatch directly causes a disconnect between the audio and the on-screen speaker. When viewers see someone's mouth has closed but the voice continues, the resulting immersion break is devastating.
Manually aligning each dubbed line can achieve perfection. But for a video with hundreds or thousands of subtitles, potentially with many more waiting to be processed, this becomes a tedious and time-consuming nightmare. We need an automated solution.
This article shares the exploration process of such an automated solution. Using Python and leveraging powerful libraries like ffmpeg and pydub, it seeks to find an acceptable synchronization point between translated dubbing and the original video. It does not aim for pixel-perfect alignment but strives to build a robust, reliable, and automatically executable engineering workflow. In most cases, this process produces a video that sounds and looks natural enough.
Core Concept: Finding Balance Between Audio and Video
The root of the problem is the time difference. Trouble arises when the dubbed audio duration exceeds the video duration corresponding to the original subtitle. We need a way to "create" extra time out of thin air.
This challenge only occurs when the dubbing is too long. If the dubbing is shorter than the video, at worst the character finishes speaking early while their mouth is still moving. This is relatively acceptable visually and doesn't disrupt the subsequent timeline. However, if the dubbing is too long, it encroaches on the next line's playback time, causing audio overlap or a complete timeline misalignment. This is the core conflict we must resolve.
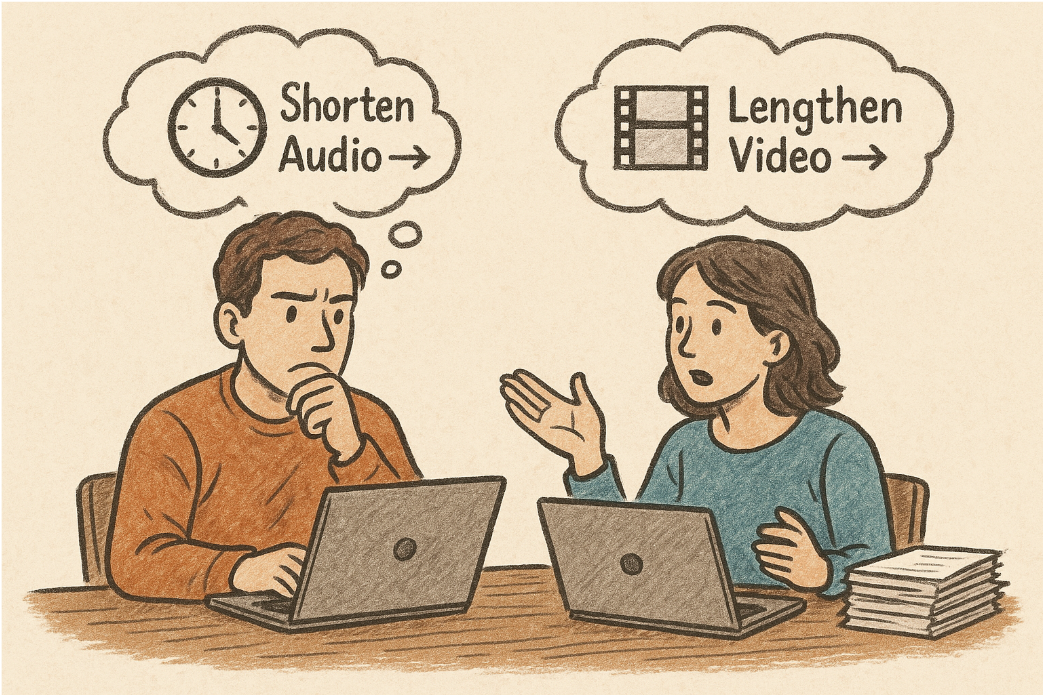
The solutions are essentially two: either shorten the audio or lengthen the video.
Shortening the audio means speeding it up. Python's
pydublibrary provides aspeedupmethod, which is simple to implement. But its drawback is obvious. When the speedup rate exceeds 1.5x, the voice begins to distort, speaking too fast, and sounds unnatural. Beyond 2x, the dubbing largely loses its informational value.Lengthening the video means slowing it down.
ffmpeg'ssetptsfilter is a powerful tool for this purpose. A singlesetpts=2.0*PTScommand can double the duration of a video segment smoothly. This buys us precious time. Similarly, excessive slowdown makes the on-screen action appear in "slow motion," feeling sluggish and unnatural.
A good automation strategy must find a balance between these two. Our initial idea was simple:
- If the time difference is small, say less than 1 second, let the audio bear the pressure. Slight acceleration is usually imperceptible to the human ear.
- If the time difference is large, both audio and video should share the burden. For example, each could handle half of the extra time. The audio speeds up a bit, the video slows down a bit, minimizing distortion on both sides.
This thinking formed the foundation of our solution. But when we actually started coding, we realized that engineering implementation was far more complex than imagined.
First Attempt: Fragile Loops and Intertwined Logic
The most intuitive approach is to iterate through each subtitle. Within the loop, get the dubbing duration, compare it with the original duration. If the dubbing is too long, decide on the spot whether to speed up the audio or slow down the video, then immediately execute the ffmpeg or pydub command.
This approach seems straightforward but hides significant risks. It couples fundamentally different operations—"calculation/decision," "file I/O," "state updates"—all within one large loop.
This means if any step in the loop fails—for instance, if a video segment fails to process due to a minor ffmpeg issue—the entire process could halt. Even if it doesn't halt, subsequent iterations might produce unpredictable errors due to corrupted state.
A more robust architecture must decouple the process, splitting it into independent, atomic stages.
- Preparation Stage: First, iterate through all subtitles completely, doing only one thing: collecting information. Calculate and store each subtitle's original start/end times, original duration, dubbed duration, and the "silent gap" duration before the next subtitle.
- Decision Stage: Iterate again, this time only performing calculations and decisions. Based on our defined balancing strategy, calculate the final "target audio duration" and "target video duration" for each subtitle needing adjustment. This stage does not modify any files.
- Execution Stage: With a clear "blueprint," now begin processing. Based on the decision stage results, process all audio and video files in batches, potentially in parallel. Audio speedup and video processing can be executed separately.
- Merging Stage: After all individual audio/video segments are processed, the final step is to concatenate them in the correct order to generate the final file.

Making each part's function singular results in clearer code and easier error handling and debugging. This is the first step from "usable" to "reliable."
The Silent Enemy: Absorbed Gaps and Error Elimination
The video timeline is continuous. Between subtitles, there are often a few seconds of "silent gaps" without dialogue. These gaps are part of the video's narrative rhythm; mishandling them makes the entire video feel odd.
A natural idea is to treat gaps as special segments. If there's a 2-second gap after subtitle A ends and before subtitle B starts, we should also cut out this 2-second video segment.
But this introduces a new problem: What if the gap is very short, say only 30 milliseconds?
ffmpeg behaves unpredictably when handling such extremely short segments. Video consists of frames, each lasting typically between 16ms to 42ms (corresponding to 60 FPS to 24 FPS). You cannot make ffmpeg precisely cut a segment of only 30ms, as it might be less than one frame. Forcing it likely results in command failure or a zero-byte empty file.
Our initial solution was "discard." If a gap is too short, say less than 50 milliseconds, we simply discard it. But we quickly rejected this idea. A long video might have hundreds or thousands of such tiny gaps. Discarding a frame or two each time accumulates, causing noticeable "jumpiness" and making the video discontinuous. This experience is unacceptable.
A better strategy is "absorption."
After processing a subtitle segment, we look ahead at the gap following it. If this gap is short (below our 50ms threshold), we "absorb" this tiny gap, treating it as part of the current subtitle segment.
Example:
- Subtitle A:
00:10.000->00:12.500 - A 40ms tiny gap
- Subtitle B:
00:12.540->00:15.000
Following the "absorption" strategy, when processing subtitle A, we notice the following gap is only 40ms. So, our cut endpoint is no longer 12.500, but extends directly to 12.540. Thus, this 40ms gap is seamlessly incorporated into the end of segment A.
This approach has two major benefits:
- Avoids Jump Frames: The video timeline remains continuous; no content is discarded.
- Provides Extra Buffer: Segment A's original duration increases from 2.5 seconds to 2.54 seconds. If this segment happens to need video slowdown, the extra 40ms provides a valuable buffer, allowing a slightly lower slowdown rate for more natural visuals.
This strategy's core involves dynamically adjusting cut endpoints and meticulously maintaining the entire timeline progression record to ensure absorbed gaps are not processed again later.
Designed for Failure: A Resilient Processing Pipeline
Real-world media files are "dirtier" than we imagine. Videos might have minor codec errors at certain points, or an unreasonable slowdown parameter (e.g., extremely high slowdown on an already short segment) could cause ffmpeg processing failure. If our program crashes entirely due to one segment's failure, it's an engineering failure.
We must design for failure. Introduce a try-check-fallback mechanism in the video processing execution stage.
Process as follows:
- Try: For a segment, execute the calculated
ffmpegcut command, which may include speed change parameters. - Check: Immediately after command execution, check if the output file exists and its size is greater than 0.
- Fallback: If the check fails, log a warning. Then, the program immediately calls
ffmpegagain, but this time in safe mode—without any speed change parameters, cutting only at the original speed.
This fallback mechanism ensures that even if slowdown for a segment fails, we at least get a correctly timed original segment, preserving the entire video timeline integrity and preventing misalignment of all subsequent segments.
Final Architecture: A Flexible, Decoupled SpeedRate Class
After repeated iterations and optimizations, we arrived at a relatively robust SpeedRate class. It encapsulates the entire complex synchronization process into a clear, reliable execution flow. Let's examine how its key parts work together.
import os
import shutil
import time
from pathlib import Path
import concurrent.futures
from pydub import AudioSegment
from pydub.exceptions import CouldntDecodeError
from videotrans.configure import config
from videotrans.util import tools
class SpeedRate:
"""
Aligns translated dubbing with the original video timeline via audio speedup and video slowdown.
V10 Changelog:
- 【Strategy Optimization】 Introduced "absorption" strategy for tiny gaps, replacing the original "discard" strategy.
When a gap after a subtitle segment is below the threshold, it is absorbed into the preceding subtitle segment for processing,
avoiding "jump frame" phenomena and providing extra duration for video slowdown.
- Adjusted video_pts calculation logic accordingly to accommodate dynamically changing segment durations.
"""
MIN_CLIP_DURATION_MS = 50 # Minimum valid segment duration (milliseconds)
def __init__(self,
*,
queue_tts=None,
shoud_videorate=False,
shoud_audiorate=False,
uuid=None,
novoice_mp4=None,
raw_total_time=0,
noextname=None,
target_audio=None,
cache_folder=None
):
self.queue_tts = queue_tts
self.shoud_videorate = shoud_videorate
self.shoud_audiorate = shoud_audiorate
self.uuid = uuid
self.novoice_mp4_original = novoice_mp4
self.novoice_mp4 = novoice_mp4
self.raw_total_time = raw_total_time
self.noextname = noextname
self.target_audio = target_audio
self.cache_folder = cache_folder if cache_folder else Path(f'{config.TEMP_DIR}/{str(uuid if uuid else time.time())}').as_posix()
Path(self.cache_folder).mkdir(parents=True, exist_ok=True)
self.max_audio_speed_rate = max(1.0, float(config.settings.get('audio_rate', 5.0)))
self.max_video_pts_rate = max(1.0, float(config.settings.get('video_rate', 10.0)))
config.logger.info(f"SpeedRate initialized for '{self.noextname}'. AudioRate: {self.shoud_audiorate}, VideoRate: {self.shoud_videorate}")
config.logger.info(f"Config limits: MaxAudioSpeed={self.max_audio_speed_rate}, MaxVideoPTS={self.max_video_pts_rate}, MinClipDuration={self.MIN_CLIP_DURATION_MS}ms")
def run(self):
"""Main execution function"""
self._prepare_data()
self._calculate_adjustments()
self._execute_audio_speedup()
self._execute_video_processing()
merged_audio = self._recalculate_timeline_and_merge_audio()
if merged_audio:
self._finalize_audio(merged_audio)
return self.queue_tts
def _prepare_data(self):
"""Step 1: Prepare and initialize data."""
tools.set_process(text="Preparing data...", uuid=self.uuid)
# Phase 1: Initialize independent data
for it in self.queue_tts:
it['start_time_source'] = it['start_time']
it['end_time_source'] = it['end_time']
it['source_duration'] = it['end_time_source'] - it['start_time_source']
it['dubb_time'] = int(tools.get_audio_time(it['filename']) * 1000) if tools.vail_file(it['filename']) else 0
it['target_audio_duration'] = it['dubb_time']
it['target_video_duration'] = it['source_duration']
it['video_pts'] = 1.0
# Phase 2: Calculate gaps
for i, it in enumerate(self.queue_tts):
if i < len(self.queue_tts) - 1:
next_item = self.queue_tts[i + 1]
it['silent_gap'] = next_item['start_time_source'] - it['end_time_source']
else:
it['silent_gap'] = self.raw_total_time - it['end_time_source']
it['silent_gap'] = max(0, it['silent_gap'])
def _calculate_adjustments(self):
"""Step 2: Calculate adjustment plan."""
tools.set_process(text="Calculating adjustments...", uuid=self.uuid)
for i, it in enumerate(self.queue_tts):
if it['dubb_time'] > it['source_duration'] and tools.vail_file(it['filename']):
try:
original_dubb_time = it['dubb_time']
_, new_dubb_length_ms = tools.remove_silence_from_file(
it['filename'], silence_threshold=-50.0, chunk_size=10, is_start=True)
it['dubb_time'] = new_dubb_length_ms
if original_dubb_time != it['dubb_time']:
config.logger.info(f"Removed silence from {Path(it['filename']).name}: duration reduced from {original_dubb_time}ms to {it['dubb_time']}ms.")
except Exception as e:
config.logger.warning(f"Could not remove silence from {it['filename']}: {e}")
# After absorbing tiny gaps, available video duration might increase
effective_source_duration = it['source_duration']
if it.get('silent_gap', 0) < self.MIN_CLIP_DURATION_MS:
effective_source_duration += it['silent_gap']
if it['dubb_time'] <= effective_source_duration or effective_source_duration <= 0:
continue
dub_duration = it['dubb_time']
# Use effective duration for calculation
source_duration = effective_source_duration
silent_gap = it['silent_gap']
over_time = dub_duration - source_duration
# Decision logic now based on `effective_source_duration`
if self.shoud_audiorate and not self.shoud_videorate:
required_speed = dub_duration / source_duration
if required_speed <= 1.5:
it['target_audio_duration'] = source_duration
else:
# Note: silent_gap here is effectively 0 after absorption, but kept for logical completeness
available_time = source_duration + (silent_gap if silent_gap >= self.MIN_CLIP_DURATION_MS else 0)
duration_at_1_5x = dub_duration / 1.5
it['target_audio_duration'] = duration_at_1_5x if duration_at_1_5x <= available_time else available_time
elif not self.shoud_audiorate and self.shoud_videorate:
required_pts = dub_duration / source_duration
if required_pts <= 1.5:
it['target_video_duration'] = dub_duration
else:
available_time = source_duration + (silent_gap if silent_gap >= self.MIN_CLIP_DURATION_MS else 0)
duration_at_1_5x = source_duration * 1.5
it['target_video_duration'] = duration_at_1_5x if duration_at_1_5x <= available_time else available_time
elif self.shoud_audiorate and self.shoud_videorate:
if over_time <= 1000:
it['target_audio_duration'] = source_duration
else:
adjustment_share = over_time // 2
it['target_audio_duration'] = dub_duration - adjustment_share
it['target_video_duration'] = source_duration + adjustment_share
# Safety checks and PTS calculation
if it['target_audio_duration'] < dub_duration:
speed_ratio = dub_duration / it['target_audio_duration']
if speed_ratio > self.max_audio_speed_rate: it['target_audio_duration'] = dub_duration / self.max_audio_speed_rate
if it['target_video_duration'] > source_duration:
pts_ratio = it['target_video_duration'] / source_duration
if pts_ratio > self.max_video_pts_rate: it['target_video_duration'] = source_duration * self.max_video_pts_rate
# pts needs calculation based on final cut's original video duration
it['video_pts'] = max(1.0, it['target_video_duration'] / source_duration)
def _process_single_audio(self, item):
"""Process speedup task for a single audio file"""
input_file_path = item['filename']
target_duration_ms = int(item['target_duration_ms'])
try:
audio = AudioSegment.from_file(input_file_path)
current_duration_ms = len(audio)
if target_duration_ms <= 0 or current_duration_ms <= target_duration_ms: return input_file_path, current_duration_ms, ""
speedup_ratio = current_duration_ms / target_duration_ms
fast_audio = audio.speedup(playback_speed=speedup_ratio)
config.logger.info(f'Audio speedup processing:{speedup_ratio=}')
fast_audio.export(input_file_path, format=Path(input_file_path).suffix[1:])
item['ref']['dubb_time'] = len(fast_audio)
return input_file_path, len(fast_audio), ""
except Exception as e:
config.logger.error(f"Error processing audio {input_file_path}: {e}")
return input_file_path, None, str(e)
def _execute_audio_speedup(self):
"""Step 3: Execute audio speedup."""
if not self.shoud_audiorate: return
tasks = [
{"filename": it['filename'], "target_duration_ms": it['target_audio_duration'], "ref": it}
for it in self.queue_tts if it.get('dubb_time', 0) > it.get('target_audio_duration', 0) and tools.vail_file(it['filename'])
]
if not tasks: return
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(self._process_single_audio, task) for task in tasks]
for i, future in enumerate(concurrent.futures.as_completed(futures)):
if config.exit_soft: executor.shutdown(wait=False, cancel_futures=True); return
future.result()
tools.set_process(text=f"Audio processing: {i + 1}/{len(tasks)}", uuid=self.uuid)
def _execute_video_processing(self):
"""Step 4: Execute video cutting (using tiny gap absorption strategy)."""
if not self.shoud_videorate or not self.novoice_mp4_original:
return
video_tasks = []
processed_video_clips = []
last_end_time = 0
i = 0
while i < len(self.queue_tts):
it = self.queue_tts[i]
# Handle gap before the subtitle segment
gap_before = it['start_time_source'] - last_end_time
if gap_before > self.MIN_CLIP_DURATION_MS:
clip_path = Path(f'{self.cache_folder}/{i:05d}_gap.mp4').as_posix()
video_tasks.append({"ss": tools.ms_to_time_string(ms=last_end_time), "to": tools.ms_to_time_string(ms=it['start_time_source']), "source": self.novoice_mp4_original, "pts": 1.0, "out": clip_path})
processed_video_clips.append(clip_path)
# Determine the cut endpoint for the current subtitle segment
start_ss = it['start_time_source']
end_to = it['end_time_source']
# V10 Core Logic: Look ahead to decide whether to absorb the next gap
if i + 1 < len(self.queue_tts):
next_it = self.queue_tts[i+1]
gap_after = next_it['start_time_source'] - it['end_time_source']
if 0 < gap_after < self.MIN_CLIP_DURATION_MS:
end_to = next_it['start_time_source'] # Extend cut endpoint
config.logger.info(f"Absorbing small gap ({gap_after}ms) after segment {i} into the clip.")
current_clip_source_duration = end_to - start_ss
# Only create a task if the segment is valid
if current_clip_source_duration > self.MIN_CLIP_DURATION_MS:
clip_path = Path(f"{self.cache_folder}/{i:05d}_sub.mp4").as_posix()
# If speed change is needed, pts might need recalculation
pts_val = it.get('video_pts', 1.0)
if pts_val > 1.01:
# New pts = target duration / new source duration
new_target_duration = it.get('target_video_duration', current_clip_source_duration)
pts_val = max(1.0, new_target_duration / current_clip_source_duration)
video_tasks.append({"ss": tools.ms_to_time_string(ms=start_ss), "to": tools.ms_to_time_string(ms=end_to), "source": self.novoice_mp4_original, "pts": pts_val, "out": clip_path})
processed_video_clips.append(clip_path)
last_end_time = end_to
i += 1
# Handle the final gap at the end
if (final_gap := self.raw_total_time - last_end_time) > self.MIN_CLIP_DURATION_MS:
clip_path = Path(f'{self.cache_folder}/zzzz_final_gap.mp4').as_posix()
video_tasks.append({"ss": tools.ms_to_time_string(ms=last_end_time), "to": "", "source": self.novoice_mp4_original, "pts": 1.0, "out": clip_path})
processed_video_clips.append(clip_path)
# ... (Subsequent execution and merging logic remains the same as previous version) ...
for j, task in enumerate(video_tasks):
if config.exit_soft: return
tools.set_process(text=f"Video processing: {j + 1}/{len(video_tasks)}", uuid=self.uuid)
the_pts = task['pts'] if task.get('pts', 1.0) > 1.01 else ""
config.logger.info(f'Video slowdown:{the_pts=}, processed output video segment={task["out"]}')
tools.cut_from_video(ss=task['ss'], to=task['to'], source=task['source'], pts=the_pts, out=task['out'])
output_path = Path(task['out'])
if not output_path.exists() or output_path.stat().st_size == 0:
config.logger.warning(f"Segment {task['out']} failed to generate (PTS={task.get('pts', 1.0)}). Fallback to original speed.")
tools.cut_from_video(ss=task['ss'], to=task['to'], source=task['source'], pts="", out=task['out'])
if not output_path.exists() or output_path.stat().st_size == 0:
config.logger.error(f"FATAL: Fallback for {task['out']} also failed. Segment will be MISSING.")
valid_clips = [clip for clip in processed_video_clips if Path(clip).exists() and Path(clip).stat().st_size > 0]
if not valid_clips:
config.logger.warning("No valid video clips generated to merge. Skipping video merge.")
self.novoice_mp4 = self.novoice_mp4_original
return
concat_txt_path = Path(f'{self.cache_folder}/concat_list.txt').as_posix()
tools.create_concat_txt(valid_clips, concat_txt=concat_txt_path)
merged_video_path = Path(f'{self.cache_folder}/merged_{self.noextname}.mp4').as_posix()
tools.set_process(text="Merging video clips...", uuid=self.uuid)
tools.concat_multi_mp4(out=merged_video_path, concat_txt=concat_txt_path)
self.novoice_mp4 = merged_video_path
def _recalculate_timeline_and_merge_audio(self):
"""Step 5: Recalculate timeline and merge audio."""
merged_audio = AudioSegment.empty()
video_was_processed = self.shoud_videorate and self.novoice_mp4_original and Path(self.novoice_mp4).name.startswith("merged_")
if video_was_processed:
config.logger.info("Building audio timeline based on processed video clips.")
current_timeline_ms = 0
try:
sorted_clips = sorted([f for f in os.listdir(self.cache_folder) if f.endswith(".mp4") and ("_sub" in f or "_gap" in f)])
except FileNotFoundError: return None
for clip_filename in sorted_clips:
clip_path = Path(f'{self.cache_folder}/{clip_filename}').as_posix()
try:
if not (Path(clip_path).exists() and Path(clip_path).stat().st_size > 0): continue
clip_duration = tools.get_video_duration(clip_path)
except Exception as e:
config.logger.warning(f"Could not get duration for clip {clip_path} (error: {e}). Skipping.")
continue
if "_sub" in clip_filename:
index = int(clip_filename.split('_')[0])
it = self.queue_tts[index]
it['start_time'] = current_timeline_ms
segment = AudioSegment.from_file(it['filename']) if tools.vail_file(it['filename']) else AudioSegment.silent(duration=clip_duration)
if len(segment) > clip_duration: segment = segment[:clip_duration]
elif len(segment) < clip_duration: segment += AudioSegment.silent(duration=clip_duration - len(segment))
merged_audio += segment
it['end_time'] = current_timeline_ms + clip_duration
it['startraw'], it['endraw'] = tools.ms_to_time_string(ms=it['start_time']), tools.ms_to_time_string(ms=it['end_time'])
else: # gap
merged_audio += AudioSegment.silent(duration=clip_duration)
current_timeline_ms += clip_duration
else:
# Mode B logic here remains unchanged as it doesn't process video, so no gap absorption issue
config.logger.info("Building audio timeline based on original timings (video not processed).")
last_end_time = 0
for i, it in enumerate(self.queue_tts):
silence_duration = it['start_time_source'] - last_end_time
if silence_duration > 0: merged_audio += AudioSegment.silent(duration=silence_duration)
it['start_time'] = len(merged_audio)
dubb_time = int(tools.get_audio_time(it['filename']) * 1000) if tools.vail_file(it['filename']) else it['source_duration']
segment = AudioSegment.from_file(it['filename']) if tools.vail_file(it['filename']) else AudioSegment.silent(duration=dubb_time)
if len(segment) > dubb_time: segment = segment[:dubb_time]
elif len(segment) < dubb_time: segment += AudioSegment.silent(duration=dubb_time - len(segment))
merged_audio += segment
it['end_time'] = len(merged_audio)
last_end_time = it['end_time_source']
it['startraw'], it['endraw'] = tools.ms_to_time_string(ms=it['start_time']), tools.ms_to_time_string(ms=it['end_time'])
return merged_audio
def _export_audio(self, audio_segment, destination_path):
"""Export Pydub AudioSegment to specified path, handling different formats."""
wavfile = Path(f'{self.cache_folder}/temp_{time.time_ns()}.wav').as_posix()
try:
audio_segment.export(wavfile, format="wav")
ext = Path(destination_path).suffix.lower()
if ext == '.wav':
shutil.copy2(wavfile, destination_path)
elif ext == '.m4a':
tools.wav2m4a(wavfile, destination_path)
else: # .mp3
tools.runffmpeg(["-y", "-i", wavfile, "-ar", "48000", "-b:a", "192k", destination_path])
finally:
if Path(wavfile).exists():
os.remove(wavfile)
def _finalize_audio(self, merged_audio):
"""Step 6: Export and align final audio/video durations (only when video was processed)."""
tools.set_process(text="Exporting and finalizing audio...", uuid=self.uuid)
try:
self._export_audio(merged_audio, self.target_audio)
video_was_processed = self.shoud_videorate and self.novoice_mp4_original and Path(self.novoice_mp4).name.startswith("merged_")
if not video_was_processed:
config.logger.info("Skipping duration alignment as video was not processed.")
return
if not (tools.vail_file(self.novoice_mp4) and tools.vail_file(self.target_audio)):
config.logger.warning("Final video or audio file not found, skipping duration alignment.")
return
video_duration_ms = tools.get_video_duration(self.novoice_mp4)
audio_duration_ms = int(tools.get_audio_time(self.target_audio) * 1000)
padding_needed = video_duration_ms - audio_duration_ms
if padding_needed > 10:
config.logger.info(f"Audio is shorter than video by {padding_needed}ms. Padding with silence.")
final_audio_segment = AudioSegment.from_file(self.target_audio)
final_audio_segment += AudioSegment.silent(duration=padding_needed)
self._export_audio(final_audio_segment, self.target_audio)
elif padding_needed < -10:
config.logger.warning(f"Final audio is longer than video by {-padding_needed}ms. This may cause sync issues.")
except Exception as e:
config.logger.error(f"Failed to export or finalize audio: {e}")
raise RuntimeError(f"Failed to finalize audio: {e}")
config.logger.info("Final audio merged and aligned successfully.")Code Explanation
__init__: Initializes all parameters and defines the key constantMIN_CLIP_DURATION_MS, the foundation for all our tiny segment handling strategies._prepare_data: Employs a robust two-phase method to prepare data, completely resolving potentialKeyErrorissues from "looking ahead" in a single loop._calculate_adjustments: The decision core. It first attempts to reduce subsequent processing pressure by removing "fluff" (silence) from the dubbing's start/end, then performs calculations based on our balancing strategy._execute_audio_speedup: Utilizes multithreading to process all audio requiring speedup in parallel, improving efficiency._execute_video_processing: This is the most complex part of the entire process and best embodies engineering practice. It implements the superior "absorption" strategy to ensure visual continuity while incorporating a "try-check-fallback" error tolerance mechanism, forming the cornerstone of the process's stability._recalculate_timeline_and_merge_audio: This method's design is very flexible. It automatically determines if the video was actually processed and chooses different modes to build the final audio timeline. This design allows the class to handle complex A/V sync tasks as well as pure audio concatenation._finalize_audio: The final "quality control" step. If the video was processed, it ensures the final generated audio track and video durations match exactly—an essential detail in a professional workflow.
Usable, But Far From Perfect
Audio-visual synchronization, especially cross-language synchronization, is a field full of details and challenges. The automated solution proposed in this article is not the final answer and cannot fully replace the fine-tuning of professionals. Its value lies in constructing a sufficiently "smart" and "robust" automated process through a series of carefully designed engineering practices—logic decoupling, absorption strategy, error fallback. It handles the vast majority of scenarios and gracefully navigates around pitfalls that would crash simpler scripts.
It is a product of a practical balance between "perfect results" and "engineering feasibility." For scenarios requiring large-scale, rapid video dubbing processing, it provides a reliable starting point, automating 80% of the work to generate an acceptable initial version. The remaining 20% can be left for manual final polishing.
