SenseVoice is Alibaba's open-source speech recognition foundation model, capable of recognizing speech in Chinese, Japanese, Korean, and English. Compared to previous models, it offers faster recognition speed and higher accuracy.
However, the official release does not include built-in timestamp output, which makes it less convenient for subtitle creation. To address this, this API project was developed by using other VAD models for pre-segmentation and then applying SenseVoice for recognition. It has been integrated into video translation software for ease of use.
SenseVoice Official Repository
This API Project https://github.com/jianchang512/sense-api
Purpose of This Project
- Replaces the official
api.pyfile to enable SRT subtitle output with timestamps. - Connects with video translation and dubbing software.
- Includes a Windows integrated package: double-click
run-api.batto start the API orrun-webui.batto launch the browser interface.
This
api.pyignores emotion recognition processing and only supports speech recognition for Chinese, Japanese, Korean, and English.
First, Deploy the SenseVoice Project
Deploy using the official source code, compatible with Windows/Linux/MacOS. Refer to the SenseVoice project homepage for details: https://github.com/FunAudioLLM/SenseVoice. After deployment, download the
api.pyfile from this project and replace the officialapi.pyfile (this replacement is mandatory for timestamped subtitles in video translation software).Deploy using the Windows integrated package, only for Windows 10/11. Download the compressed package from the right side of this page: https://github.com/jianchang512/sense-api/releases. After extraction, double-click
run-api.batto use the API orrun-webui.batto open the web interface.
Using the API
The default API address is http://127.0.0.1:5000/asr.
You can modify it in the api.py file:
HOST='127.0.0.1'
PORT=5000- If deployed via official source code, remember to replace the
api.pyfile and runpython api.py. - If using the Windows integrated package, simply double-click
run-api.bat. - Wait until the terminal displays
http://127.0.0.1:5000, indicating successful startup and readiness for use.
Note: The first time you use it, the model will be downloaded from ModelScope, which may take some time.
Using in Video Translation and Dubbing Tools
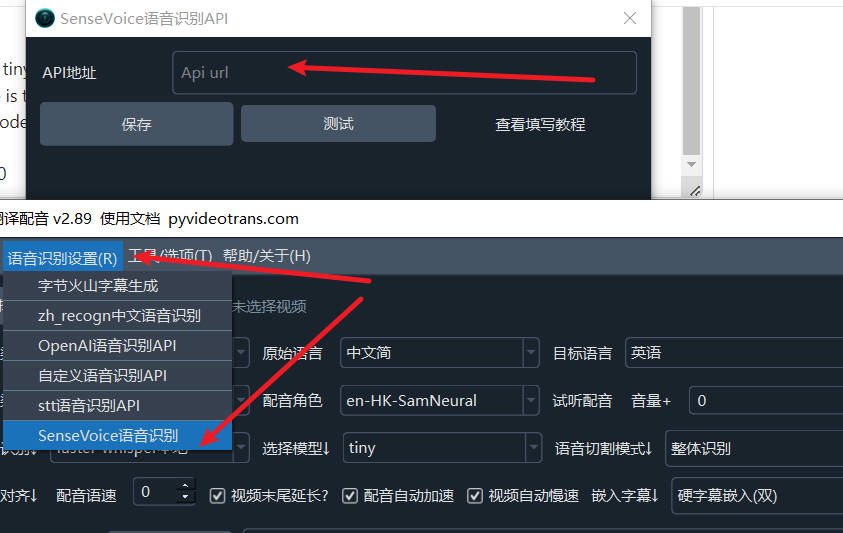
Enter the API address in the menu under "Speech Recognition Settings" → "SenseVoice Speech Recognition" window.
Calling the API in Source Code
- API Address: Assuming the default is http://127.0.0.1:5000
- Method: POST
- Request Parameters:
- lang: String type, one of zh | ja | ko | en
- file: Binary data of the audio file to recognize, in WAV format
- Response:
- On success:
- On failure:
- Other internal errors:
Example: To recognize the audio file 10.wav, where the spoken language is Chinese.
import requests
res = requests.post(f"http://127.0.0.1:5000/asr", files={"file": open("c:/users/c1/videos/10s.wav", 'rb')}, data={"lang":"zh"}, timeout=7200)
print(res.json())Using WebUI in the Browser
- If deployed via official source code, run
python webui.py. When the terminal showshttp://127.0.0.1:7860, open this address in your browser. - If using the Windows integrated package, double-click
run-webui.bat. The browser will open automatically upon successful startup.