SenseVoice 是阿里开源的语音识别基础模型,支持识别中日韩英发声的语音,相比之前一些模型,具有识别速度快、精准度高的特点。
只是官方释出的版本一直未自带时间戳输出,在制作字幕时较为不便,目前使用其他vad模型进行预分割,再使用SenseVoice识别,创建了本 api项目,并接入视频翻译软件之中,以方便使用。
本api项目 https://github.com/jianchang512/sense-api
该项目作用
- 替换官方
api.py文件,用于实现带时间戳srt字幕输出 - 连接视频翻译配音软件使用。
- 附带windows整合包,可通过双击
run-api.bat启动api,或双击run-webui.bat启动浏览器界面
该api.py中忽略了情感识别处理,只支持 中日韩英 4种语音的识别
首先需要部署 SenseVoice 项目
使用官方源码方式部署,支持部署到Windows/Linux/MacOSX上,具体教程可参考SenseVoice项目主页 https://github.com/FunAudioLLM/SenseVoice 。部署后,从本项目中下载
api.py文件,覆盖官方包中自带的api.py文件(若要在视频翻译软件中使用,则必须覆盖,否则无法获得带时间戳的字幕)使用win整合包部署,仅支持部署在Windows10/11上,在本页面右侧 https://github.com/jianchang512/sense-api/releases 下载压缩包,解压后双击
run-api.bat即可使用API, 双击run-webui.bat可打开web界面。
使用 Api
默认 Api 地址是 http://127.0.0.1:5000/asr
可打开 api.py 文件修改,
HOST='127.0.0.1'
PORT=5000- 如果是官方源码部署,记得覆盖
api.py文件,然后执行python api.py - 如果是win整合包,双击
run-api.bat即可 - 等待终端中显示
http://127.0.0.1:5000字样时,即启动成功,可以使用了
注意第一次使用时,会联网从 modelscope 下载模型,用时会教长
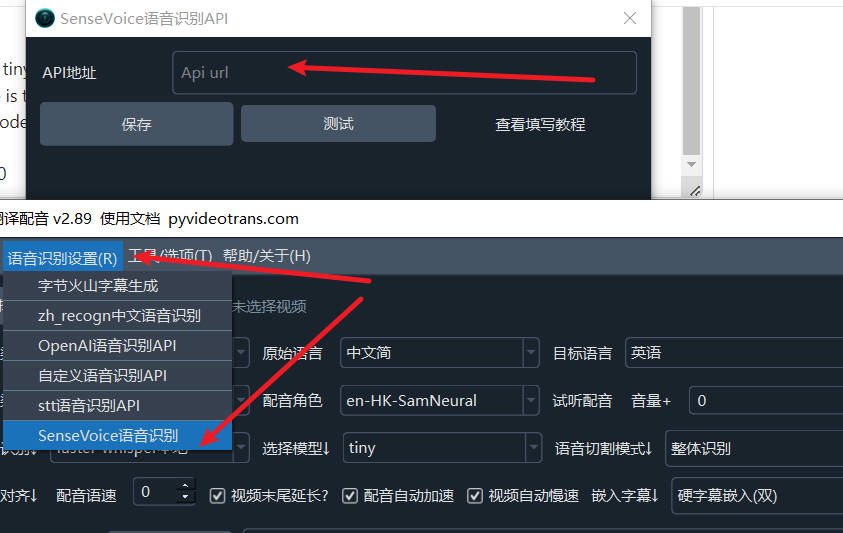
在视频翻译配音工具中使用
将api地址填写到菜单--语音识别设置-SenseVoice语音识别窗口的 API地址中即可。
源码中调用 API
- api地址: 假设是默认api地址 http://127.0.0.1:5000
- 调用方法: POST
- 请求参数
- lang: 字符串类型,可传入 zh | ja | ko | en 四者之一
- file: 要识别的音频二进制数据 wav 格式
- 返回响应
- 识别成功返回:
- 识别失败返回:
- 其他内部错误返回:
示例: 要识别 10.wav 音频文件,该文件中说话语言为中文。
import requests
res = requests.post(f"http://127.0.0.1:5000/asr", files={"file": open("c:/users/c1/videos/10s.wav", 'rb')},data={"lang":"zh"}, timeout=7200)
print(res.json())使用 webui在浏览器中使用
- 如果是源码部署的官方包,执行
python webui.py,等待终端显示http://127.0.0.1:7860时,在浏览器中输入该地址即可使用 - 如果是win整合包,双击
run-webui.bat,启动成功后将自动打开浏览器