Built an online speech synthesis platform based on Microsoft Edge TTS engine, completely free, no registration required, ready to use immediately.
Similar services were offered before but had to be paused due to server expiration and other reasons.
Now, leveraging the powerful Workers technology from Cloudflare, this platform has been rebuilt to provide stable and reliable free services! As long as usage is not extremely high, there will be no costs, so there's no need to shut it down, unless Microsoft strengthens rate limiting and stops offering free usage.
Completely Free: Built on Cloudflare Workers, utilizing free quotas. No need for me to pay for servers, so no charges for you.
High-Quality Voice: Uses Microsoft Edge TTS engine for natural, smooth speech that sounds close to a real person.
Multi-Language Support: Supports multiple languages and a wide range of voice roles to meet your diverse needs.
Emotion Adjustment: Offers over 20 emotional tones (e.g., angry, happy, sad) to make your speech more expressive. (Some roles may not support emotion adjustment.)
Easy to Use: No software installation required; operate directly on the web page for convenience and speed.
Customizable Parameters: Adjust speed, pitch, volume, and more to create personalized voice output.
How to Use?
Get your desired voice in just three simple steps:
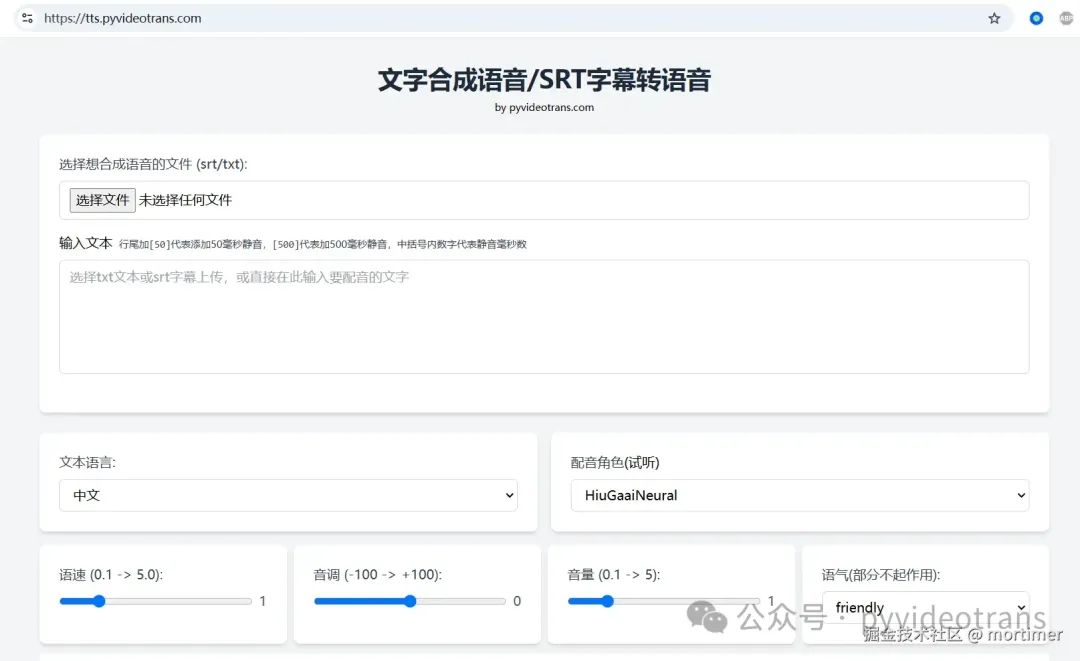
Visit the Website: Go to https://tts.pyvideotrans.com to access the online speech synthesis platform. You can enter text directly in the text box or upload SRT subtitle files or TXT text files.
Select Language and Role: Accurately choose the language of your text and pick your preferred voice role. Use the preview button to listen to different voice samples.
Customize and Synthesize: Set parameters like speed, pitch, volume, and emotional tone, then click the "Execute" button. Once synthesis is complete, download the audio file or play it directly on the webpage.
Tips for Adding Silent Segments
To make the speech more rhythmic, you can add silent segments in the text.
Method: Add square brackets [] at the end of the line where you want silence, and specify the duration in milliseconds inside the brackets. For example, [500] adds a 500-millisecond silence after that line.
Note
Avoid overly long lines of text, as this may cause synthesis to fail. Keep each line concise for best results.
Speech synthesis is processed line by line, and silent segments are applied between lines.