零基础一键运行!Qwen3-TTS 语音合成/克隆 Windows 整合包使用教程
前言
Qwen3-TTS 是一款非常强大的语音合成(TTS)模型,不仅能根据文字生成语音,还能克隆你的声音,甚至通过文字描述来设计一个从未存在过的声音!
通常部署这种开源大模型需要复杂的 Python 环境、各种依赖库安装,对非技术人员来说门槛极高。
本整合包是 Windows 10/11 专用的一键整合包:
- 无需手动安装 Python
- 无需配置复杂的环境变量
- 内置环境管理工具(uv.exe)
- 自动下载模型(已配置国内加速)
你只需要下载整合包,解压,双击,即可开始使用!
前置条件
| 条件 | 说明 |
|---|---|
| 操作系统 | Windows 10/11 |
| 磁盘空间 | 建议预留 10GB 以上 |
| 硬件 | CPU 可运行,有 NVIDIA 显卡可开启 GPU 加速(10 倍提速) |
第一步:下载与解压
- 下载整合包压缩文件:
【重要】 请将压缩包解压到一个没有中文、没有空格的路径下(例如
D:\AI\QwenTTS)- 错误示范:
C:\Users\张三\桌面\新建文件夹 - 正确示范:
D:\Tools\Qwen-TTS
- 错误示范:
打开文件夹,你应该会看到如下图所示的文件结构:

第二步:安装运行环境(仅需一次)
下载解压后,首先双击 0解压后立即点此安装运行环境.bat,该文件会安装配置环境,仅需运行一次。
第三步:选择功能(5 个启动脚本)
文件夹内有 5 个 .bat 文件,分别对应不同的功能和模型大小,根据你的电脑配置和需求选择:
1. 语音克隆模式(基于参考音频)
这种模式允许你上传一段 3~10 秒的参考音频,AI 会模仿这个声音说话。
| 启动脚本 | 特点 |
|---|---|
| 启动语音克隆-0.6B模型.bat | 速度快,对电脑配置要求低,适合尝鲜 |
| 启动语音克隆-1.7B模型.bat | 效果更好,声音更逼真,但生成速度稍慢 |
2. 声音设计模式(Voice Design)
这种模式不需要参考音频,可以直接用文字描述声音特征,例如:「一个深沉的、有磁性的中年男性声音」。
| 启动脚本 | 特点 |
|---|---|
| 启动声音设计.bat | 使用 1.7B 模型,输入 Prompt 创造独一无二的声音 |
注意:声音设计模式不支持在 pyVideoTrans 中使用,仅可在 WebUI 中体验。
3. 自定义音色模式(内置预设角色)
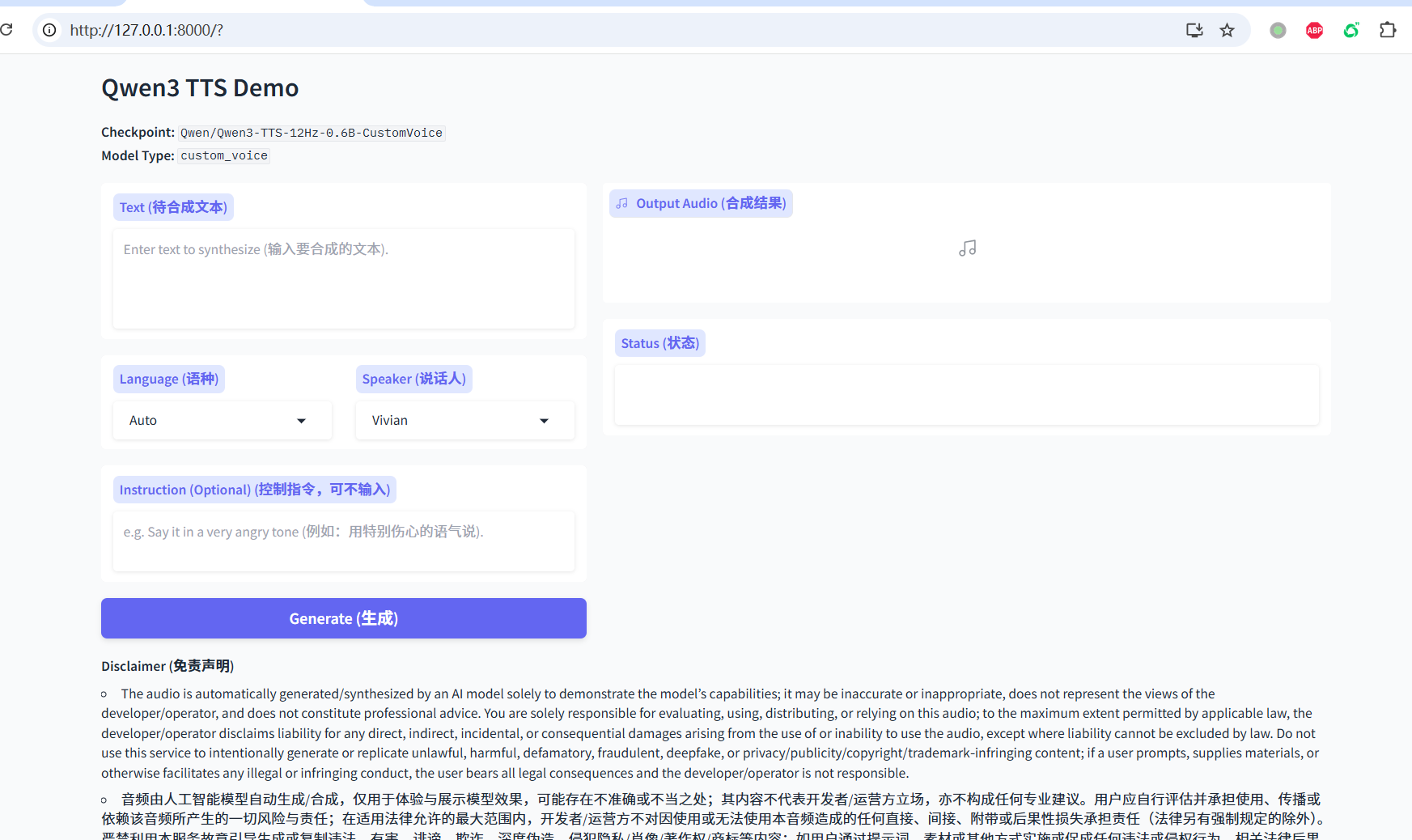
这种模式内置了 Vivian、Uncle_fu、Sohee 等预设的高质量音色,稳定且好听。
| 启动脚本 | 特点 |
|---|---|
| 启动自定义音色-0.6B模型.bat | 速度较快 |
| 启动自定义音色-1.7B模型.bat | 效果更好 |
注意:此模式下不能使用参考音频,只能从下拉菜单选择角色。
第四步:启动与自动配置
- 双击你选择的
.bat文件 - 会出现一个黑色的命令行窗口,请不要关闭它!
- 如果是第一次运行,工具会自动为你配置环境并下载模型文件
- 已内置国内加速源(hf-mirror.com),下载速度有保障
- 根据网速,可能需要等待几分钟到十几分钟,请耐心等待
- 当黑色窗口中出现以下字样时,说明启动成功了:
* To create a public link, set `share=True` in `launch()`.
第五步:开始使用
- 打开浏览器(推荐 Chrome 或 Edge)
- 在地址栏输入:
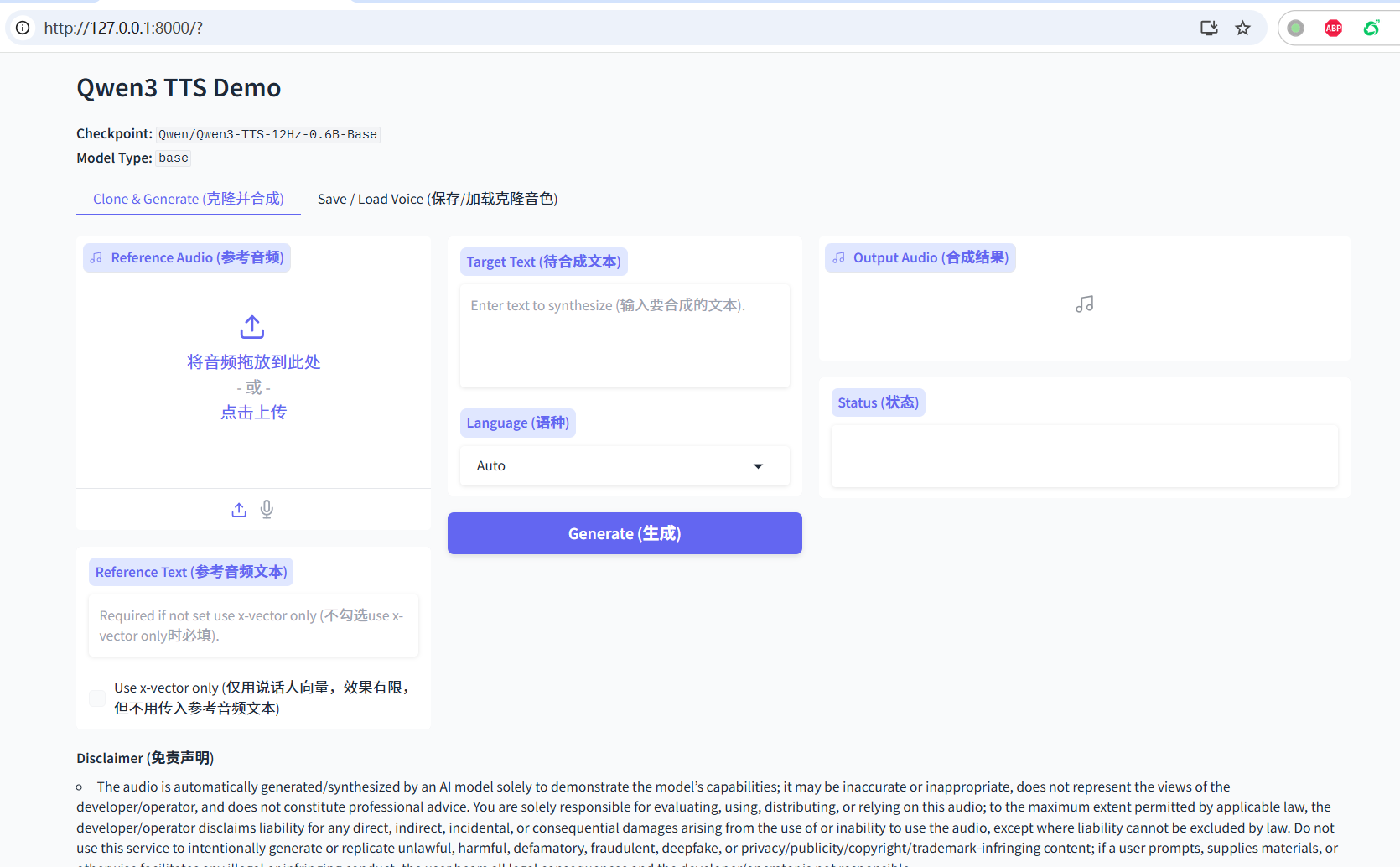
http://127.0.0.1:8000并回车 - 你将看到 Qwen3-TTS 的操作界面:
- 输入框:输入你想让 AI 读的文字
- 参考音频/Prompt:根据你启动的模式,上传音频或输入描述
- Generate(生成):点击按钮生成语音
在 pyVideoTrans 中使用
语音克隆模式
- 在 pyVideoTrans 中配置参考音频(菜单 → TTS设置 → Qwen-tts(本地))
- 在主界面「配音渠道」中选择「Qwen3-TTS」
- 在「配音角色」中选择「clone」使用参考音频克隆
自定义音色模式
- 在 pyVideoTrans 中配置 Qwen3-TTS 地址
- 在主界面「配音渠道」中选择「Qwen3-TTS」
- 在「配音角色」中选择内置音色(如 Vivian、Serena 等)
报错说明
报错
Cannot find a function with api_name: /run_voice_clone:说明你在 pyVideoTrans 中使用了clone角色或参考音频,但启动的不是语音克隆模型。请启动Qwen3-TTS-12Hz-0.6B-Base或Qwen3-TTS-12Hz-1.7B-Base。报错
Cannot find a function with api_name: /run_instruct:说明你在使用内置音色,但启动的不是自定义音色模型。请启动Qwen3-TTS-12Hz-0.6B-CustomVoice或Qwen3-TTS-12Hz-1.7B-CustomVoice。启动 VoiceDesign 模型报错:pyVideoTrans 仅支持语音克隆模型和自定义音色模型,不支持声音设计模型。
高手进阶:开启 GPU 加速
默认情况下,为了保证所有人的电脑都能运行,配置设置为 CPU 模式。
如果你有 NVIDIA 显卡 并且已安装好 CUDA 环境,可通过以下步骤获得 10 倍以上推理速度:
第一步:安装 CUDA 版 PyTorch
在整合包 bat 所在文件夹内,地址栏清空输入 cmd 回车,然后执行以下命令:
CUDA 12.x 版本:
runtime\python -m pip install --force-reinstall torch torchaudio --index-url https://download.pytorch.org/whl/cu128CUDA 13.x 版本:
runtime\python -m pip install --force-reinstall torch torchaudio --index-url https://download.pytorch.org/whl/cu130第二步:修改启动脚本
- 右键点击你想修改的
.bat文件,选择「编辑」(或用记事本打开) - 找到文件最后一行包含以下代码的部分:
--device cpu --dtype float32- 删除这段代码(即删除
--device cpu --dtype float32) - 保存文件,重新双击运行即可。程序会自动调用 GPU 进行加速
参考音频要求
| 项目 | 要求 |
|---|---|
| 格式 | WAV 格式(推荐) |
| 时长 | 3~10 秒 |
| 内容 | 发音清晰,无背景噪音 |
| 放置位置 | pyVideoTrans 根目录下的 f5-tts 文件夹 |
常见问题
1. 双击后闪退怎么办?
请检查解压路径是否包含中文或空格。请确保安装了 VC++ 运行库(通常玩游戏的电脑都有)。
2. 生成速度很慢?
默认 CPU 模式确实比 GPU 慢。如果你有 NVIDIA 显卡,建议按照「高手进阶」部分开启加速。1.7B 模型比 0.6B 慢是正常的。
3. 第一次启动卡住不动了?
这是在下载模型,文件较大(几GB),请看黑色窗口是否有进度条或下载提示,只要不报错就请耐心等待。
4. 模型下载失败?
默认从 hf-mirror.com 下载,如果仍然失败,可尝试:
- 检查网络连接
- 使用科学上网访问 huggingface.co
- 手动下载模型文件放到
models目录
5. 报错 Cannot find a function with api_name: /run_voice_clone?
你在 pyVideoTrans 中使用了 clone 角色或参考音频配音,这要求启动语音克隆模型(Base 模型),而你启动了其他模型(如自定义音色模型或声音设计模型)。请切换到正确的启动脚本。