玩配音的基本都知道,微软的edge-tts是好用免费的语音合成利器,唯一缺点是对国内限流越来越严,不过可以通过部署到 cloudflare 来规避,并且还能白嫖 cloudflare的服务器和带宽资源。
先看效果,完成后将有一个配音api接口和一个web配音界面
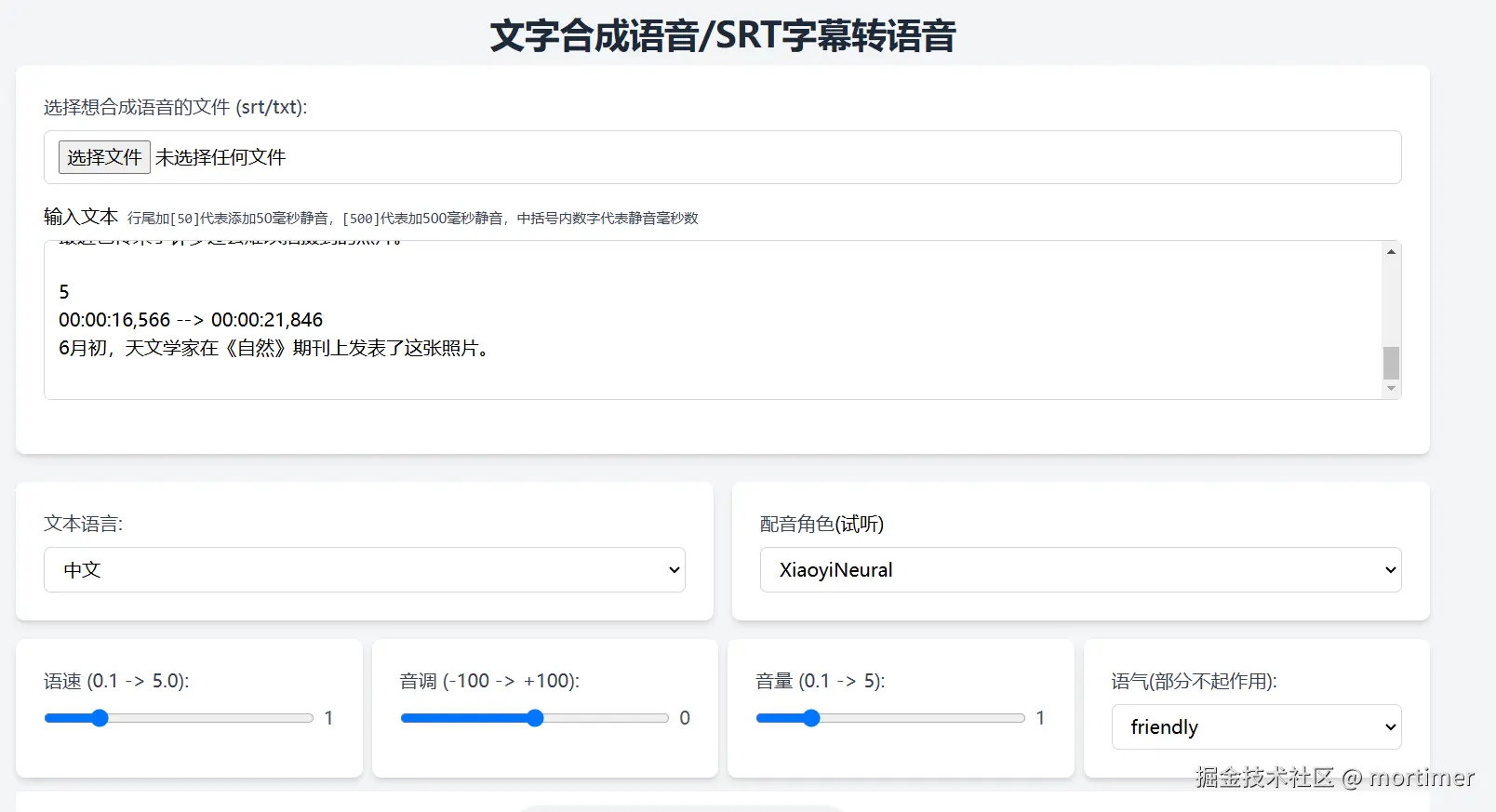
这是web界面
const requestBody = {
"model": "tts-1",
"input": '这是要合成语音的文字',
"voice": 'zh-CN-XiaoxiaoNeural',
"response_format": "mp3",
"speed": 1.0
};
const response = await fetch('部署到cloudflare后的网址', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer 部署后的key,随意`,
},
body: JSON.stringify(requestBody),
});这是接口调用js版函数,并兼容 openai tts 接口
接下来说说如何部署到 cloudflare 上
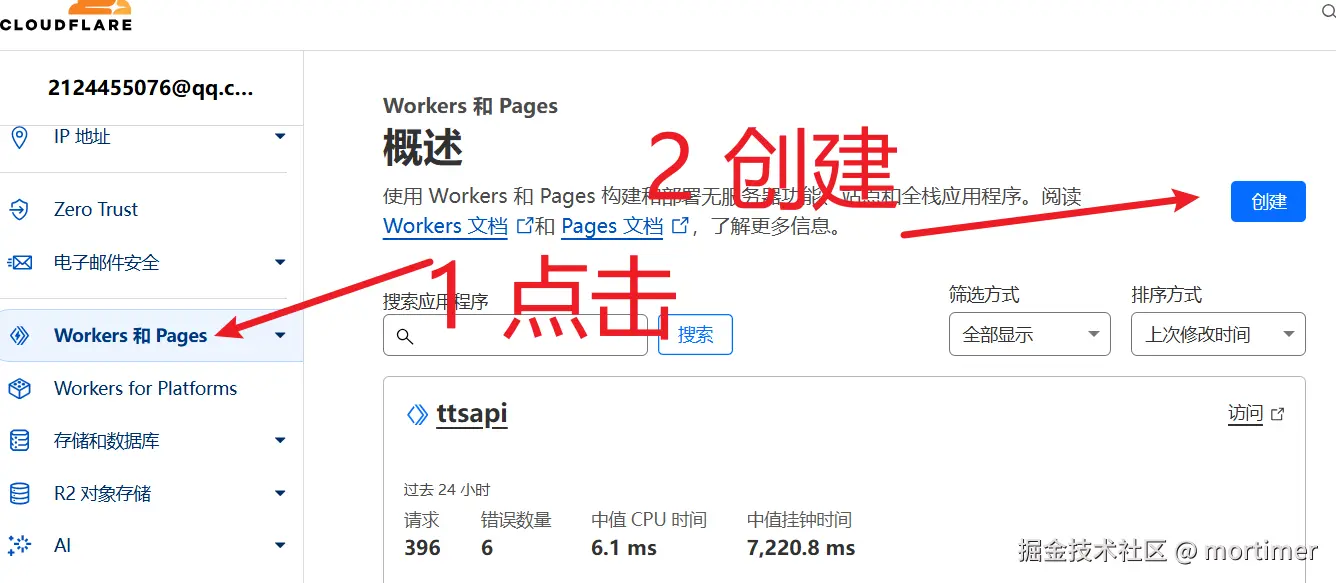
登录 cloudflare 创建一个Workers
网址 https://dash.cloudflare.com/ 如何登录注册不再赘述
登录后,点击左侧 Workers 和 Pages,打开创建页面
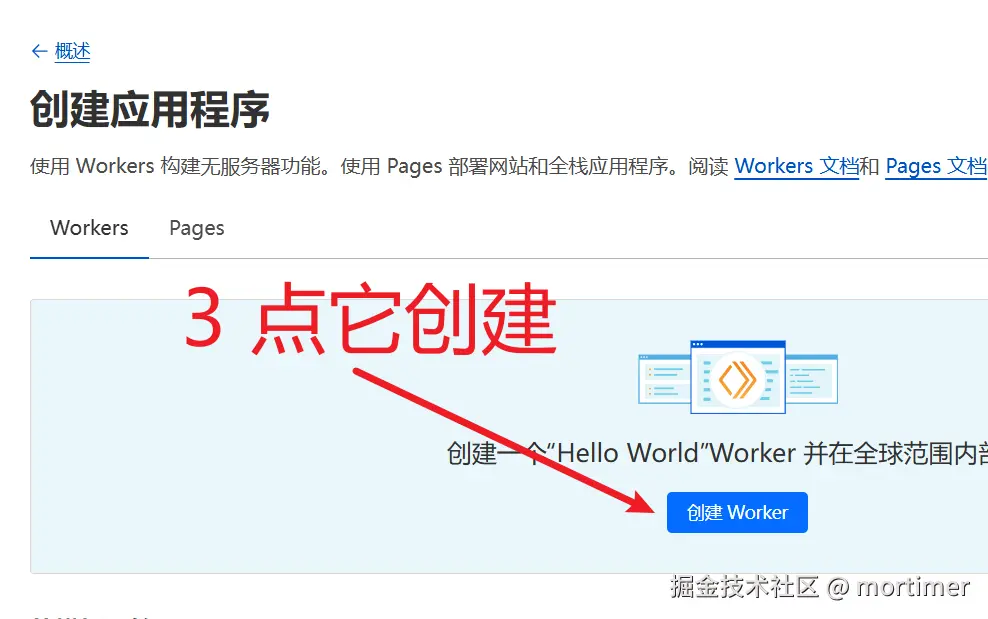
继续点击创建
然后在出现的输入框中填写一个英文名称,作为cloudflare赠送的免费子域名头
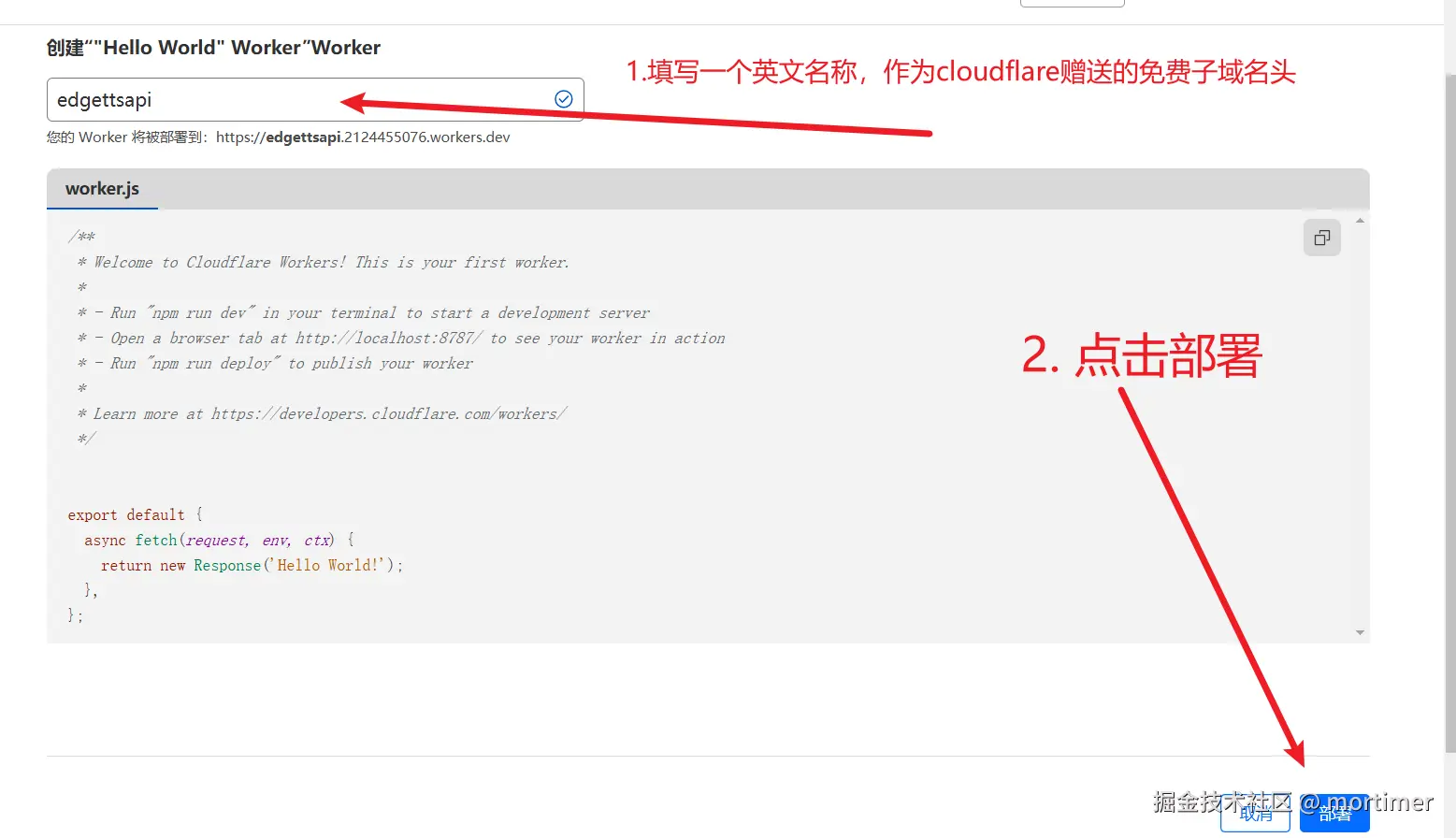
点击右下角部署后,在新出现的页面中继续点击编辑代码,进入核心阶段,复制代码
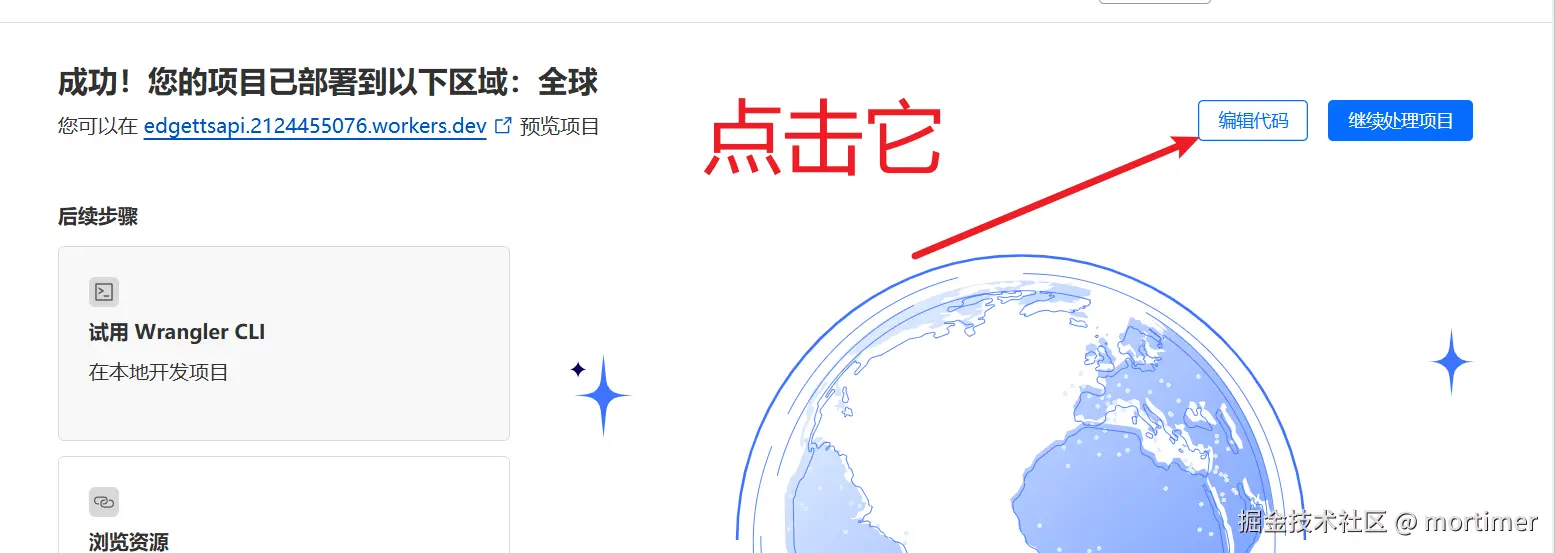
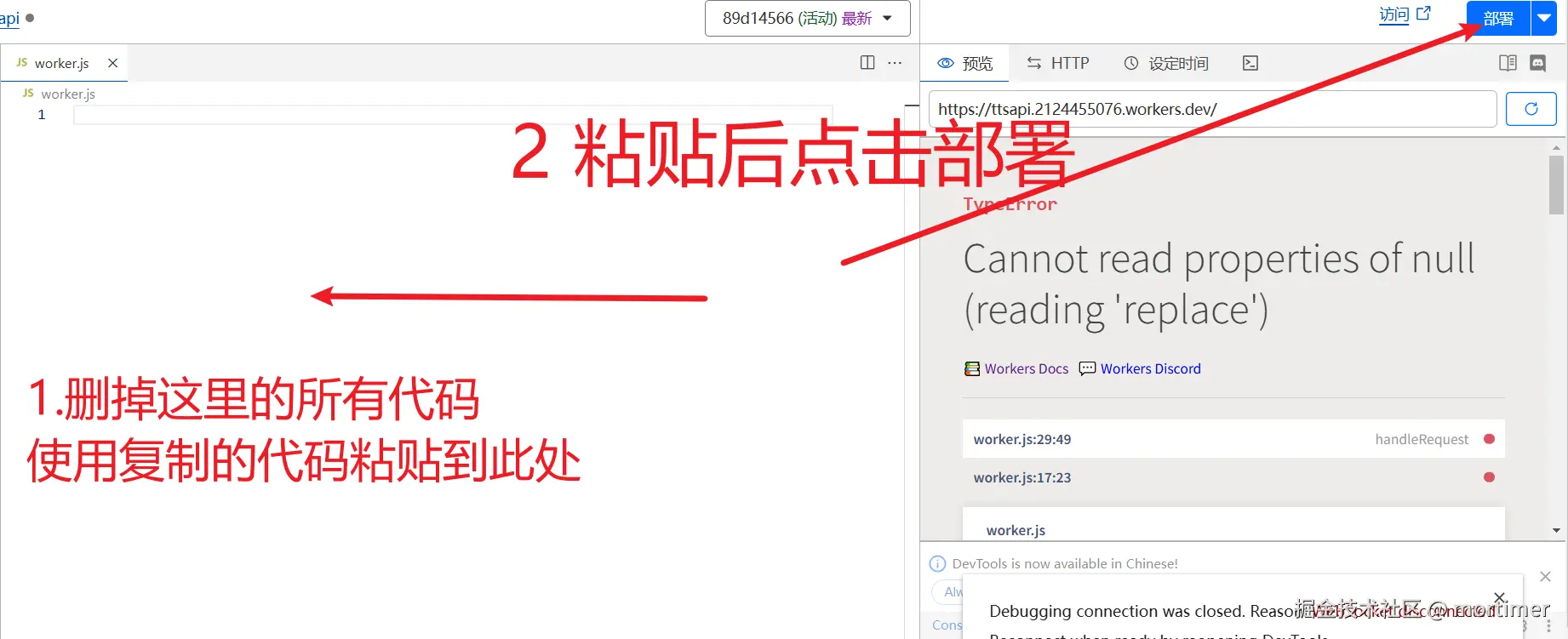
然后删掉里面所有的代码,复制下面的代码去替换
// 自定义api key ,用于防止滥用
const API_KEY = '';
const encoder = new TextEncoder();
let expiredAt = null;
let endpoint = null;
let clientId = "";
const TOKEN_REFRESH_BEFORE_EXPIRY = 3 * 60;
let tokenInfo = {
endpoint: null,
token: null,
expiredAt: null
};
addEventListener("fetch", event => {
event.respondWith(handleRequest(event.request));
});
async function handleRequest(request) {
if (request.method === "OPTIONS") {
return handleOptions(request);
}
const authHeader = request.headers.get("authorization") || request.headers.get("x-api-key");
const apiKey = authHeader?.startsWith("Bearer ")
? authHeader.slice(7)
: null;
// 只在设置了 API_KEY 的情况下才验证
if (API_KEY && apiKey !== API_KEY) {
return new Response(JSON.stringify({
error: {
message: "Invalid API key. Use 'Authorization: Bearer your-api-key' header",
type: "invalid_request_error",
param: null,
code: "invalid_api_key"
}
}), {
status: 401,
headers: {
"Content-Type": "application/json",
...makeCORSHeaders()
}
});
}
const requestUrl = new URL(request.url);
const path = requestUrl.pathname;
if (path === "/v1/audio/speech") {
try {
const requestBody = await request.json();
const {
model = "tts-1",
input,
voice = "zh-CN-XiaoxiaoNeural",
response_format = "mp3",
speed = '1.0',
volume='0',
pitch = '0', // 添加 pitch 参数,默认值为 0
style = "general"//添加style参数,默认值为general
} = requestBody;
let rate = parseInt(String( (parseFloat(speed)-1.0)*100) );
let numVolume = parseInt( String(parseFloat(volume)*100) );
let numPitch = parseInt(pitch);
const response = await getVoice(
input,
voice,
rate>=0?`+${rate}%`:`${rate}%`,
numPitch>=0?`+${numPitch}Hz`:`${numPitch}Hz`,
numVolume>=0?`+${numVolume}%`:`${numVolume}%`,
style,
"audio-24khz-48kbitrate-mono-mp3"
);
return response;
} catch (error) {
console.error("Error:", error);
return new Response(JSON.stringify({
error: {
message: error.message,
type: "api_error",
param: null,
code: "edge_tts_error"
}
}), {
status: 500,
headers: {
"Content-Type": "application/json",
...makeCORSHeaders()
}
});
}
}
// 默认返回 404
return new Response("Not Found", { status: 404 });
}
async function handleOptions(request) {
return new Response(null, {
status: 204,
headers: {
...makeCORSHeaders(),
"Access-Control-Allow-Methods": "GET,HEAD,POST,OPTIONS",
"Access-Control-Allow-Headers": request.headers.get("Access-Control-Request-Headers") || "Authorization"
}
});
}
async function getVoice(text, voiceName = "zh-CN-XiaoxiaoNeural", rate = '+0%', pitch = '+0Hz', volume='+0%',style = "general", outputFormat = "audio-24khz-48kbitrate-mono-mp3") {
try {
const maxChunkSize = 2000;
const chunks = text.trim().split("\n");
// 获取每个分段的音频
//const audioChunks = await Promise.all(chunks.map(chunk => getAudioChunk(chunk, voiceName, rate, pitch, volume,style, outputFormat)));
let audioChunks=[]
while(chunks.length>0){
try{
let audio_chunk= await getAudioChunk(chunks.shift(), voiceName, rate, pitch, volume,style, outputFormat)
audioChunks.push(audio_chunk)
}catch(e){
return new Response(JSON.stringify({
error: {
message: String(e),
type: "api_error",
param: `${voiceName}, ${rate}, ${pitch}, ${volume},${style}, ${outputFormat}`,
code: "edge_tts_error"
}
}), {
status: 500,
headers: {
"Content-Type": "application/json",
...makeCORSHeaders()
}
});
}
}
// 将音频片段拼接起来
const concatenatedAudio = new Blob(audioChunks, { type: 'audio/mpeg' });
const response = new Response(concatenatedAudio, {
headers: {
"Content-Type": "audio/mpeg",
...makeCORSHeaders()
}
});
return response;
} catch (error) {
console.error("语音合成失败:", error);
return new Response(JSON.stringify({
error: {
message: error,
type: "api_error",
param: null,
code: "edge_tts_error "+voiceName
}
}), {
status: 500,
headers: {
"Content-Type": "application/json",
...makeCORSHeaders()
}
});
}
}
//获取单个音频数据
async function getAudioChunk(text, voiceName, rate, pitch,volume, style, outputFormat='audio-24khz-48kbitrate-mono-mp3') {
const endpoint = await getEndpoint();
const url = `https://${endpoint.r}.tts.speech.microsoft.com/cognitiveservices/v1`;
let m=text.match(/\[(\d+)\]\s*?$/);
let slien=0;
if(m&&m.length==2){
slien=parseInt(m[1]);
text=text.replace(m[0],'')
}
const response = await fetch(url, {
method: "POST",
headers: {
"Authorization": endpoint.t,
"Content-Type": "application/ssml+xml",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0",
"X-Microsoft-OutputFormat": outputFormat
},
body: getSsml(text, voiceName, rate,pitch,volume, style,slien)
});
if (!response.ok) {
const errorText = await response.text();
throw new Error(`Edge TTS API error: ${response.status} ${errorText}`);
}
return response.blob();
}
function getSsml(text, voiceName, rate, pitch,volume,style,slien=0) {
let slien_str='';
if(slien>0){
slien_str=`<break time="${slien}ms" />`
}
return `<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" version="1.0" xml:lang="zh-CN">
<voice name="${voiceName}">
<mstts:express-as style="${style}" styledegree="2.0" role="default" >
<prosody rate="${rate}" pitch="${pitch}" volume="${volume}">${text}</prosody>
</mstts:express-as>
${slien_str}
</voice>
</speak>`;
}
async function getEndpoint() {
const now = Date.now() / 1000;
if (tokenInfo.token && tokenInfo.expiredAt && now < tokenInfo.expiredAt - TOKEN_REFRESH_BEFORE_EXPIRY) {
return tokenInfo.endpoint;
}
// 获取新token
const endpointUrl = "https://dev.microsofttranslator.com/apps/endpoint?api-version=1.0";
const clientId = crypto.randomUUID().replace(/-/g, "");
try {
const response = await fetch(endpointUrl, {
method: "POST",
headers: {
"Accept-Language": "zh-Hans",
"X-ClientVersion": "4.0.530a 5fe1dc6c",
"X-UserId": "0f04d16a175c411e",
"X-HomeGeographicRegion": "zh-Hans-CN",
"X-ClientTraceId": clientId,
"X-MT-Signature": await sign(endpointUrl),
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0",
"Content-Type": "application/json; charset=utf-8",
"Content-Length": "0",
"Accept-Encoding": "gzip"
}
});
if (!response.ok) {
throw new Error(`获取endpoint失败: ${response.status}`);
}
const data = await response.json();
const jwt = data.t.split(".")[1];
const decodedJwt = JSON.parse(atob(jwt));
tokenInfo = {
endpoint: data,
token: data.t,
expiredAt: decodedJwt.exp
};
return data;
} catch (error) {
console.error("获取endpoint失败:", error);
// 如果有缓存的token,即使过期也尝试使用
if (tokenInfo.token) {
console.log("使用过期的缓存token");
return tokenInfo.endpoint;
}
throw error;
}
}
function addCORSHeaders(response) {
const newHeaders = new Headers(response.headers);
for (const [key, value] of Object.entries(makeCORSHeaders())) {
newHeaders.set(key, value);
}
return new Response(response.body, { ...response, headers: newHeaders });
}
function makeCORSHeaders() {
return {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "GET,HEAD,POST,OPTIONS",
"Access-Control-Allow-Headers": "Content-Type, x-api-key",
"Access-Control-Max-Age": "86400"
};
}
async function hmacSha256(key, data) {
const cryptoKey = await crypto.subtle.importKey(
"raw",
key,
{ name: "HMAC", hash: { name: "SHA-256" } },
false,
["sign"]
);
const signature = await crypto.subtle.sign("HMAC", cryptoKey, new TextEncoder().encode(data));
return new Uint8Array(signature);
}
async function base64ToBytes(base64) {
const binaryString = atob(base64);
const bytes = new Uint8Array(binaryString.length);
for (let i = 0; i < binaryString.length; i++) {
bytes[i] = binaryString.charCodeAt(i);
}
return bytes;
}
async function bytesToBase64(bytes) {
return btoa(String.fromCharCode.apply(null, bytes));
}
function uuid() {
return crypto.randomUUID().replace(/-/g, "");
}
async function sign(urlStr) {
const url = urlStr.split("://")[1];
const encodedUrl = encodeURIComponent(url);
const uuidStr = uuid();
const formattedDate = dateFormat();
const bytesToSign = `MSTranslatorAndroidApp${encodedUrl}${formattedDate}${uuidStr}`.toLowerCase();
const decode = await base64ToBytes("oik6PdDdMnOXemTbwvMn9de/h9lFnfBaCWbGMMZqqoSaQaqUOqjVGm5NqsmjcBI1x+sS9ugjB55HEJWRiFXYFw==");
const signData = await hmacSha256(decode, bytesToSign);
const signBase64 = await bytesToBase64(signData);
return `MSTranslatorAndroidApp::${signBase64}::${formattedDate}::${uuidStr}`;
}
function dateFormat() {
const formattedDate = (new Date()).toUTCString().replace(/GMT/, "").trim() + " GMT";
return formattedDate.toLowerCase();
}
// 添加请求超时控制
async function fetchWithTimeout(url, options, timeout = 30000) {
const controller = new AbortController();
const id = setTimeout(() => controller.abort(), timeout);
try {
const response = await fetch(url, {
...options,
signal: controller.signal
});
clearTimeout(id);
return response;
} catch (error) {
clearTimeout(id);
throw error;
}
}特别需要注意的是顶部两行代码,设置 api key ,防止被他人滥用
// 这是 api key,用于验证可用权限
const API_KEY = '';绑定自己的域名
默认绑定的域名是 https://输入框填写的子域名头.你的账号名.workers.dev/
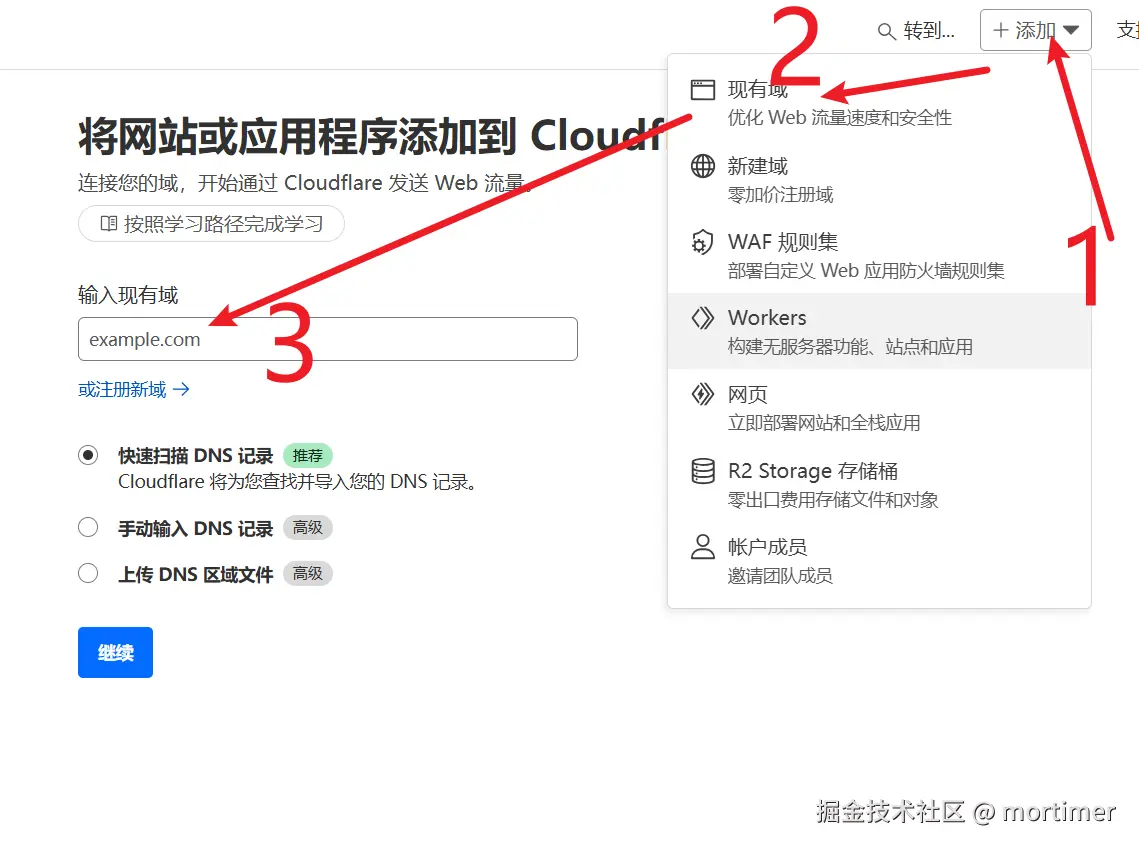
但不幸的是该域名在国内被墙,想免翻墙使用,你需要绑定一个自己的域名。
- 如果你还没有在 cloudflare上添加过自己的域名,可点击右上角
添加--现有域,然后输入自己的域名
- 如果在cloudflare上已添加过域名,则点击左侧名称返回管理界面,添加自定义域名
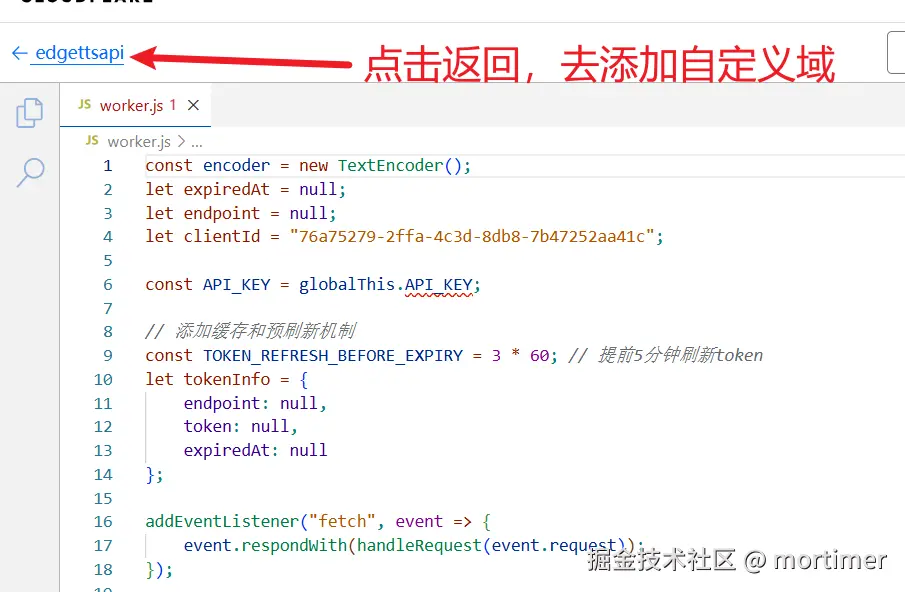
点击 设置--域和路由--添加
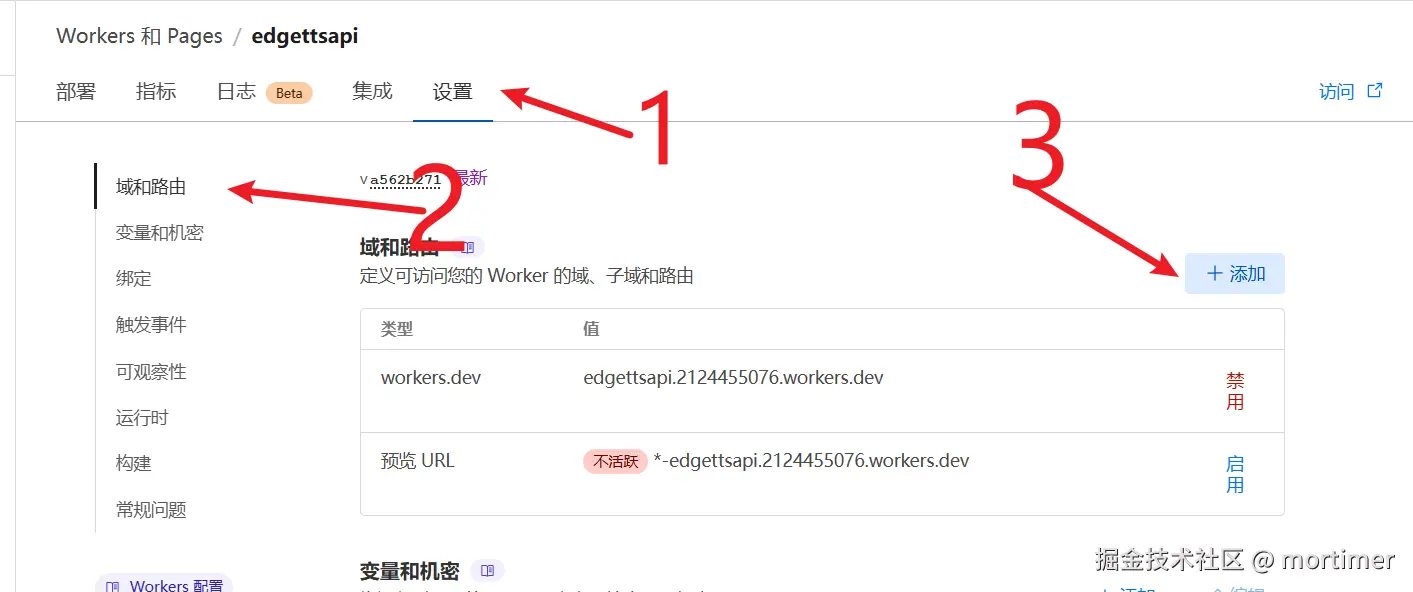
再点击自定义域,然后填写已添加到 cloudflare 的域名的子域名,例如我的域名 pyvideotrans.com 已添加cloudflare,那么此处我可以填写 ttsapi.pyvideotrans.com
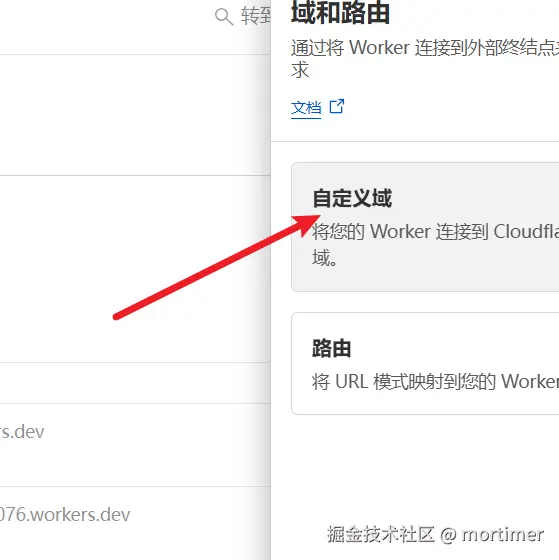
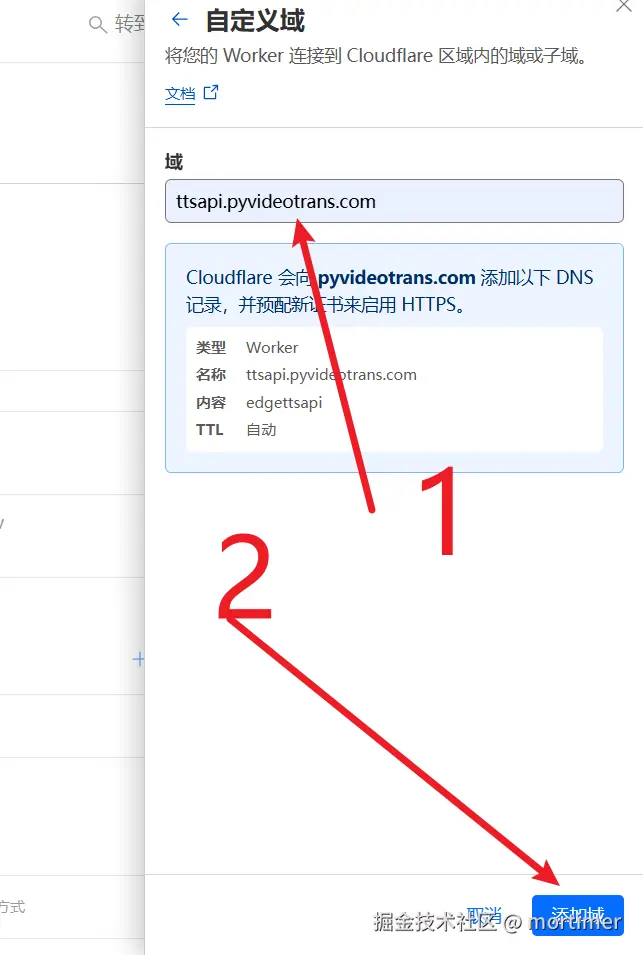
如下图,添加完毕
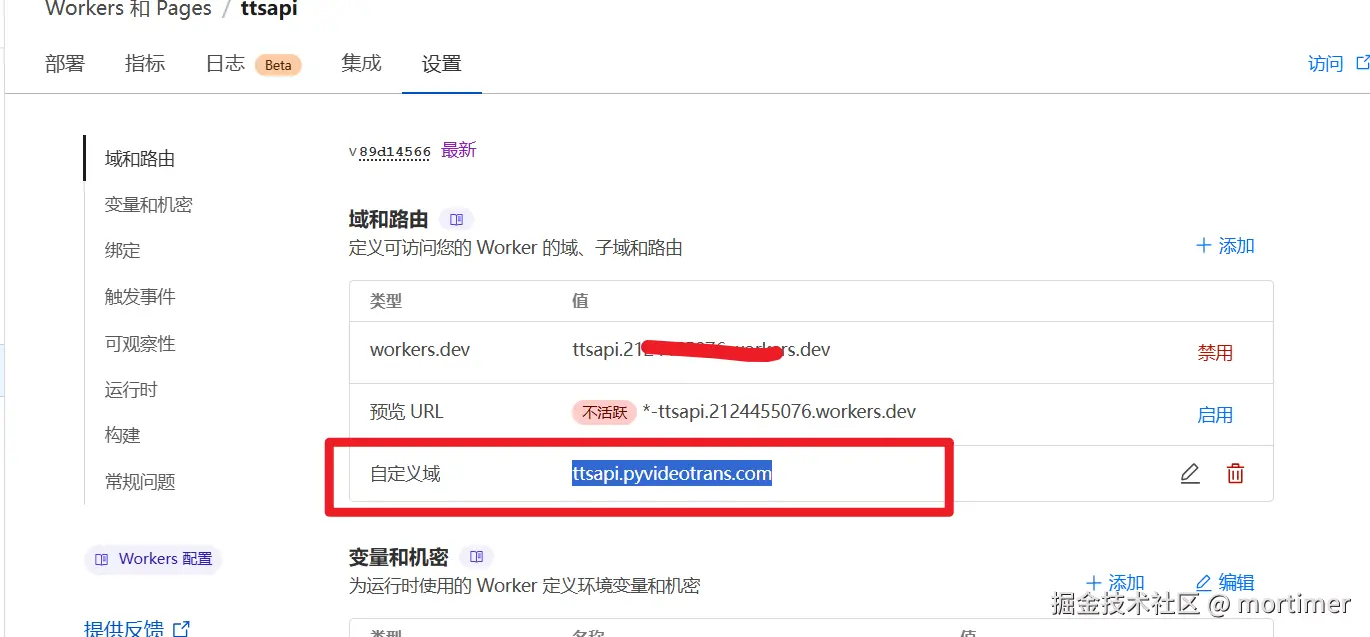
此处显示你添加的自定义域
在视频翻译软件中使用
请将软件升级到 v3.40 方可使用,升级下载地址 https://pyvideotrans.com/downpackage
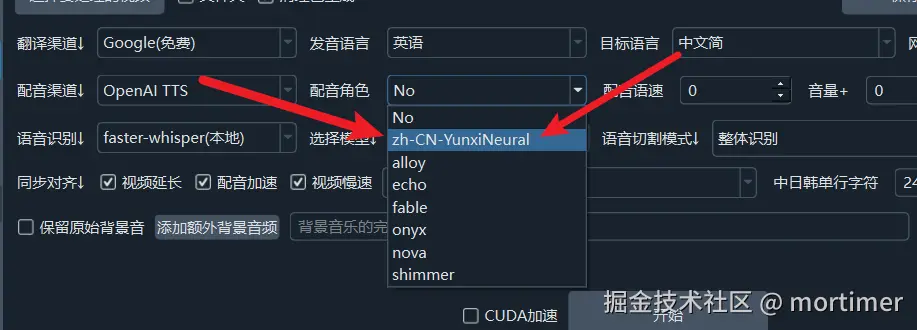
打开菜单,进入 “TTS 设置” -> “OpenAI TTS”。将接口地址更改为 https://替换为你的自定义域/v1,"SK" 填写你的 API_KEY。在角色列表中,用英文逗号分隔,填写你想要使用的角色。
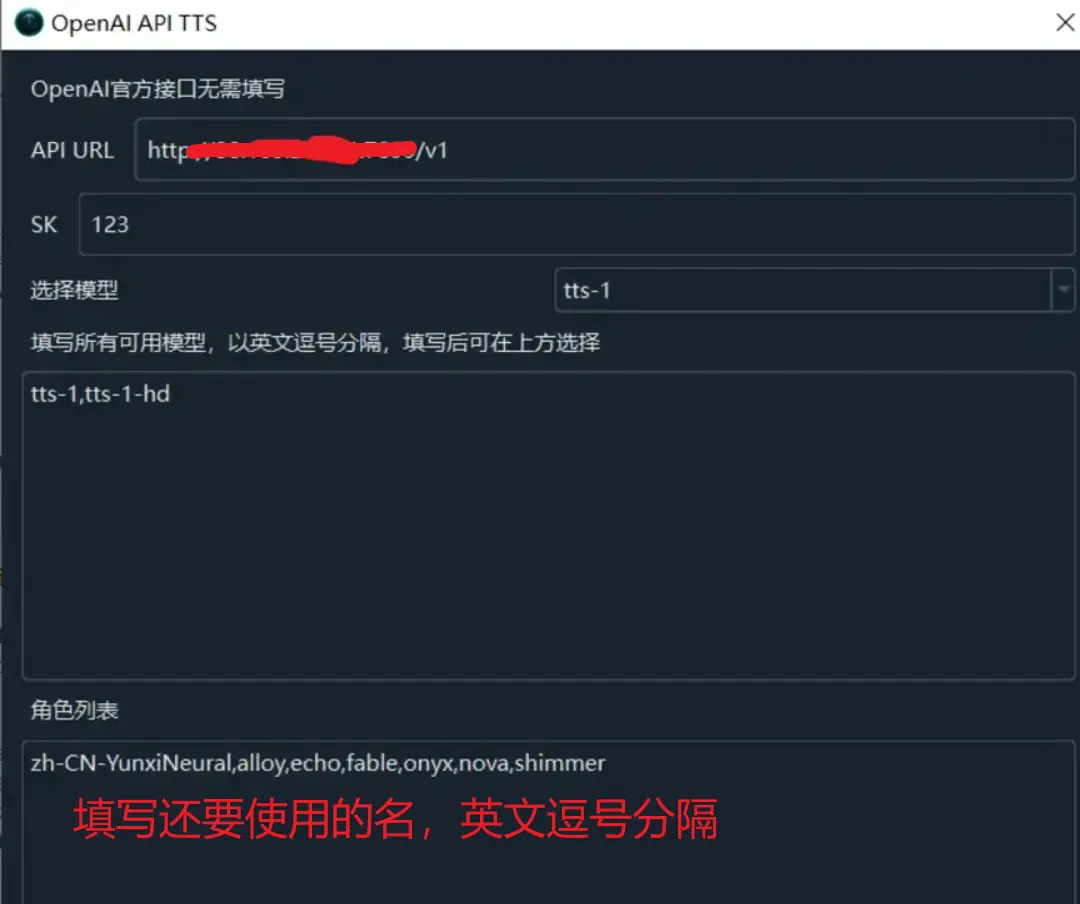
可用角色
以下是可用的角色列表。请注意,文字语言和角色必须匹配。
中文发音角色:
zh-HK-HiuGaaiNeural
zh-HK-HiuMaanNeural
zh-HK-WanLungNeural
zh-CN-XiaoxiaoNeural
zh-CN-XiaoyiNeural
zh-CN-YunjianNeural
zh-CN-YunxiNeural
zh-CN-YunxiaNeural
zh-CN-YunyangNeural
zh-CN-liaoning-XiaobeiNeural
zh-TW-HsiaoChenNeural
zh-TW-YunJheNeural
zh-TW-HsiaoYuNeural
zh-CN-shaanxi-XiaoniNeural
英语角色:
en-AU-NatashaNeural
en-AU-WilliamNeural
en-CA-ClaraNeural
en-CA-LiamNeural
en-HK-SamNeural
en-HK-YanNeural
en-IN-NeerjaExpressiveNeural
en-IN-NeerjaNeural
en-IN-PrabhatNeural
en-IE-ConnorNeural
en-IE-EmilyNeural
en-KE-AsiliaNeural
en-KE-ChilembaNeural
en-NZ-MitchellNeural
en-NZ-MollyNeural
en-NG-AbeoNeural
en-NG-EzinneNeural
en-PH-JamesNeural
en-PH-RosaNeural
en-SG-LunaNeural
en-SG-WayneNeural
en-ZA-LeahNeural
en-ZA-LukeNeural
en-TZ-ElimuNeural
en-TZ-ImaniNeural
en-GB-LibbyNeural
en-GB-MaisieNeural
en-GB-RyanNeural
en-GB-SoniaNeural
en-GB-ThomasNeural
en-US-AvaMultilingualNeural
en-US-AndrewMultilingualNeural
en-US-EmmaMultilingualNeural
en-US-BrianMultilingualNeural
en-US-AvaNeural
en-US-AndrewNeural
en-US-EmmaNeural
en-US-BrianNeural
en-US-AnaNeural
en-US-AriaNeural
en-US-ChristopherNeural
en-US-EricNeural
en-US-GuyNeural
en-US-JennyNeural
en-US-MichelleNeural
en-US-RogerNeural
en-US-SteffanNeural
日语角色:
ja-JP-KeitaNeural
ja-JP-NanamiNeural
韩语角色:
ko-KR-HyunsuNeural
ko-KR-InJoonNeural
ko-KR-SunHiNeural
法语角色:
fr-BE-CharlineNeural
fr-BE-GerardNeural
fr-CA-ThierryNeural
fr-CA-AntoineNeural
fr-CA-JeanNeural
fr-CA-SylvieNeural
fr-FR-VivienneMultilingualNeural
fr-FR-RemyMultilingualNeural
fr-FR-DeniseNeural
fr-FR-EloiseNeural
fr-FR-HenriNeural
fr-CH-ArianeNeural
fr-CH-FabriceNeural
德语角色:
de-AT-IngridNeural
de-AT-JonasNeural
de-DE-SeraphinaMultilingualNeural
de-DE-FlorianMultilingualNeural
de-DE-AmalaNeural
de-DE-ConradNeural
de-DE-KatjaNeural
de-DE-KillianNeural
de-CH-JanNeural
de-CH-LeniNeural
西班牙语角色:
es-AR-ElenaNeural
es-AR-TomasNeural
es-BO-MarceloNeural
es-BO-SofiaNeural
es-CL-CatalinaNeural
es-CL-LorenzoNeural
es-ES-XimenaNeural
es-CO-GonzaloNeural
es-CO-SalomeNeural
es-CR-JuanNeural
es-CR-MariaNeural
es-CU-BelkysNeural
es-CU-ManuelNeural
es-DO-EmilioNeural
es-DO-RamonaNeural
es-EC-AndreaNeural
es-EC-LuisNeural
es-SV-LorenaNeural
es-SV-RodrigoNeural
es-GQ-JavierNeural
es-GQ-TeresaNeural
es-GT-AndresNeural
es-GT-MartaNeural
es-HN-CarlosNeural
es-HN-KarlaNeural
es-MX-DaliaNeural
es-MX-JorgeNeural
es-NI-FedericoNeural
es-NI-YolandaNeural
es-PA-MargaritaNeural
es-PA-RobertoNeural
es-PY-MarioNeural
es-PY-TaniaNeural
es-PE-AlexNeural
es-PE-CamilaNeural
es-PR-KarinaNeural
es-PR-VictorNeural
es-ES-AlvaroNeural
es-ES-ElviraNeural
es-US-AlonsoNeural
es-US-PalomaNeural
es-UY-MateoNeural
es-UY-ValentinaNeural
es-VE-PaolaNeural
es-VE-SebastianNeural
阿拉伯语角色:
ar-DZ-AminaNeural
ar-DZ-IsmaelNeural
ar-BH-AliNeural
ar-BH-LailaNeural
ar-EG-SalmaNeural
ar-EG-ShakirNeural
ar-IQ-BasselNeural
ar-IQ-RanaNeural
ar-JO-SanaNeural
ar-JO-TaimNeural
ar-KW-FahedNeural
ar-KW-NouraNeural
ar-LB-LaylaNeural
ar-LB-RamiNeural
ar-LY-ImanNeural
ar-LY-OmarNeural
ar-MA-JamalNeural
ar-MA-MounaNeural
ar-OM-AbdullahNeural
ar-OM-AyshaNeural
ar-QA-AmalNeural
ar-QA-MoazNeural
ar-SA-HamedNeural
ar-SA-ZariyahNeural
ar-SY-AmanyNeural
ar-SY-LaithNeural
ar-TN-HediNeural
ar-TN-ReemNeural
ar-AE-FatimaNeural
ar-AE-HamdanNeural
ar-YE-MaryamNeural
ar-YE-SalehNeural
孟加拉语角色:
bn-BD-NabanitaNeural
bn-BD-PradeepNeural
bn-IN-BashkarNeural
bn-IN-TanishaaNeural
捷克语角色
cs-CZ-AntoninNeural
cs-CZ-VlastaNeural
荷兰语角色:
nl-BE-ArnaudNeural
nl-BE-DenaNeural
nl-NL-ColetteNeural
nl-NL-FennaNeural
nl-NL-MaartenNeural
希伯来语角色:
he-IL-AvriNeural
he-IL-HilaNeural
印地语角色:
hi-IN-MadhurNeural
hi-IN-SwaraNeural
匈牙利语角色:
hu-HU-NoemiNeural
hu-HU-TamasNeural
印尼语角色:
id-ID-ArdiNeural
id-ID-GadisNeural
意大利语角色:
it-IT-GiuseppeNeural
it-IT-DiegoNeural
it-IT-ElsaNeural
it-IT-IsabellaNeural
哈萨克语角色:
kk-KZ-AigulNeural
kk-KZ-DauletNeural
马来语角色:
ms-MY-OsmanNeural
ms-MY-YasminNeural
波兰语角色:
pl-PL-MarekNeural
pl-PL-ZofiaNeural
葡萄牙语角色:
pt-BR-ThalitaNeural
pt-BR-AntonioNeural
pt-BR-FranciscaNeural
pt-PT-DuarteNeural
pt-PT-RaquelNeural
俄语角色:
ru-RU-DmitryNeural
ru-RU-SvetlanaNeural
瑞典语角色:
sw-KE-RafikiNeural
sw-KE-ZuriNeural
sw-TZ-DaudiNeural
sw-TZ-RehemaNeural
泰国语角色:
th-TH-NiwatNeural
th-TH-PremwadeeNeural
土耳其语角色:
tr-TR-AhmetNeural
tr-TR-EmelNeural
乌克兰语角色:
uk-UA-OstapNeural
uk-UA-PolinaNeural
越南语角色:
vi-VN-HoaiMyNeural
vi-VN-NamMinhNeural使用 openai sdk 测试
这是兼容openai 的接口,可使用openai sdk 直接测试,如下python代码
import logging
from openai import OpenAI
import json
import httpx
api_key = 'adgas213423235saeg' # 替换为你的实际 API key
base_url = 'https://xxx.xxx.com/v1' # 替换为你的自定义域,默认加 /v1
client = OpenAI(
api_key=api_key,
base_url=base_url
)
data = {
'model': 'tts-1',
'input': '你好啊,亲爱的朋友们',
'voice': 'zh-CN-YunjianNeural',
'response_format': 'mp3',
'speed': 1.0,
}
try:
response = client.audio.speech.create(
**data
)
with open('./test_openai.mp3', 'wb') as f:
f.write(response.content)
print("MP3 file saved successfully to test_openai.mp3")
except Exception as e:
print(f"An error occurred: {e}")搭建web界面
接口有了,那么如何搭建页面呢?
打开该项目 https://github.com/jianchang512/tts-pyvideotrans 下载解压,然后将其中的 index.html/output.css/vue.js 3个文件放在服务器目录下,访问 index.html 即可。
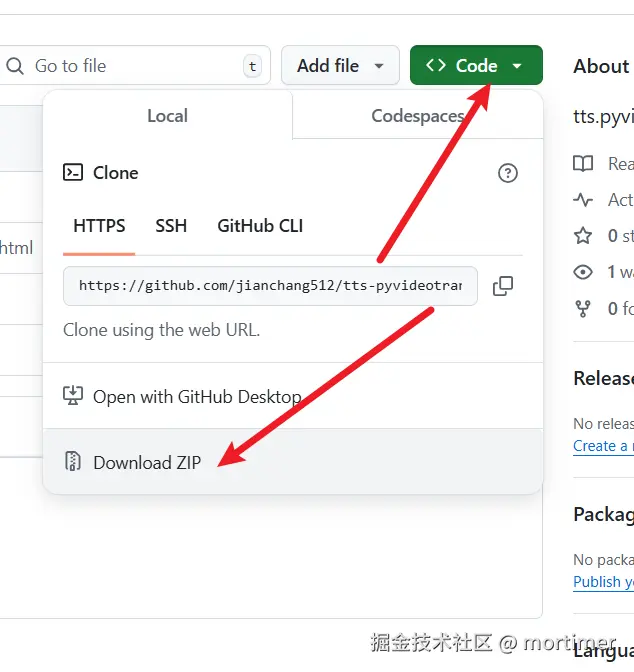
注意在 index.html 搜索 https://ttsapi.pyvideotrans.com, 改为你部署在 cloudflare 的自定义域,否则无法使用
注意必须删掉底部的 4个 script 行代码,这是用于本站的统计和广告代码,因该项目直接用于本站,故有此代码