用 ModelScope cam++和 Paraformer 打造说话人识别字幕:一次完整的踩坑与实践
如果你处理过多媒体内容,一定知道给视频加字幕是基本操作。但如果想更进一步,让字幕自动标出每句话是谁说的,挑战就来了。
这篇文章,就是我的一次完整实战记录。从一个简单的想法出发,我利用 ModelScope 的开源模型,一步步搭建、调试,最终实现了一个能自动识别说话人并生成SRT字幕的工具。在这趟旅程中,我踩过的坑、解决问题的思路,以及对技术边界的思考,或许比最终的代码更有价值。
最初的蓝图:两大模型,各司其职
目标很明确:输入一段多人对话的音频,输出带有 [spk_0], [spk_1] 这类说话人标记的SRT字幕。
要实现这个目标,单靠一个模型是不够的,需要一套组合拳:
说话人分离 (Speaker Diarization)
- 任务:找出“谁在什么时候说话”。它像一个侦探,扫描整个音频,划分出不同人的说话时间段,但它不关心这些人说了什么。
- 选用模型:
iic/speech_campplus_speaker-diarization_common,一个在说话人识别领域身经百战的实力派模型。 - 模型地址:https://www.modelscope.cn/models/iic/speech_campplus_speaker-diarization_common
语音识别 (ASR)
- 任务:搞定“说了什么”。它负责把语音信号转换成带时间戳的文字。
- 选用模型:
iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch,FunASR生态中的Paraformer模型,以中文识别的准确和高效著称。 - 模型地址:https://www.modelscope.cn/models/iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch
结果融合
- 任务:这是我们自己编写的“胶水”代码。它的工作是拿到前两步的结果,像一个导演一样,将每一句台词(文字+时间)精确地分配给对应的演员(说话人),最终生成我们想要的带说话人标记的SRT字幕。
蓝图很美好,但当真正开始施工时,挑战才浮出水面。
调试之旅:在“意外”与“惊喜”中前行
第一道坎:API 参数的“猜谜游戏”
撸起袖子开干,最初的代码却屡屡碰壁,TypeError 成了家常便饭。错误日志像个不耐烦的向导,反复提示:“参数名不对!” 通过反复尝试和对比文档,才发现,即便同在 ModelScope 生态下,不同模型的“口味”也各不相同:
- 说话人分离的
diarization_pipeline需要的音频参数是audio。 - 而语音识别的
asr_model.generate则认准了input。
一个小小的参数名差异,成了万里长征的第一步。
第二道坎:模型输出的“神秘盲盒”
我曾想当然地以为,说话人分离模型会客气地返回一个标准格式(如RTTM)的文件路径。然而,现实是它直接在内存中给了一个列表。更折腾的是,这个列表的格式还几经变化,从最初的“列表的列表”到最终那个极简的 [[开始秒, 结束秒, 说话人ID]] 格式,着实让人摸不着头脑。
这提醒我们,不能凭感觉写代码,必须打印并理解模型每一步的真实输出。
第三道坎:如何优雅地“断句”?
ASR模型给了我们一整段带标点的文字,以及一个精确到“字”级别的时间戳列表,但唯独不给分好句的现成结果。这又是一个难题。
最初的尝试:笨拙但有效 我手写了一个
reconstruct_sentences_from_asr函数,用正则表达式按句号、问号等标点来“粗暴”地切分句子,再根据每个切分后句子的字数去累加时间戳。这个方法能跑通,但感觉不够“AI”,很别扭。最终的优化:发现“隐藏开关” 经过深入研究,我发现 FunASR 模型本身就集成了**语音活动检测(VAD)**的功能,这个功能天生就是用来断句的。只需要在调用
model.generate时,多加一个sentence_timestamp=True参数,就能直接得到一个名为sentence_info的字段。这个字段里包含了分好句、带时间戳的完美结果,一步到位。
最后的困惑:代码对了,结果为何不对?
当所有代码逻辑都已理顺,我用一段包含清晰男女对话的音频进行测试,结果却显示所有话都是同一个人说的。这是最让人困惑的时刻:代码逻辑天衣无缝,为何结果却南辕北辙?
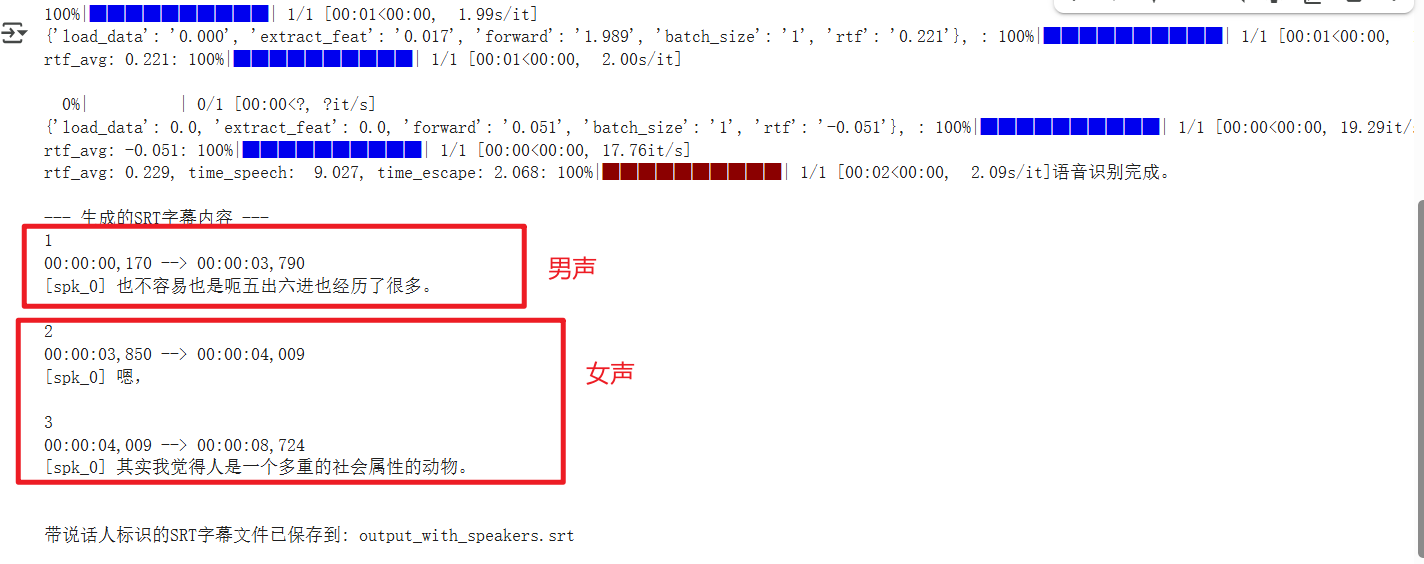 如上图运行结果,第一句是男声,第二句是女声,却并未成功区分。
如上图运行结果,第一句是男声,第二句是女声,却并未成功区分。
我用官方提供的示例音频进行交叉验证,最终确认了一个残酷的事实:我的代码逻辑已经完全正确,但我的测试音频,对 cam++ 这个模型来说难度太高了。即便我通过 oracle_num=2 参数明确告知模型现场有两个人,它依然没能成功区分。
最终代码与现实的差距
这份代码融合了上述所有的优化,它逻辑清晰,并且最大化地利用了模型自身的能力。
import os
import re
from funasr import AutoModel
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import soundfile
audio_file = 'he.wav'
try:
data, sample_rate = soundfile.read(audio_file)
if sample_rate != 16000:
print(f"警告:音频采样率为 {sample_rate}Hz。为了获得最佳效果,建议使用16kHz采样率的音频。")
except Exception as e:
print(f"错误:无法读取音频文件 {audio_file}。请确保文件存在且格式正确。错误信息: {e}")
exit()
# === 说话人分离模型 ===
print("初始化说话人分离模型 (cam++)...")
diarization_pipeline = pipeline(
task=Tasks.speaker_diarization,
model='iic/speech_campplus_speaker-diarization_common',
model_revision='v1.0.0'
)
# === 语音识别模型 ===
print("初始化语音识别模型 (paraformer-zh)...")
asr_model = AutoModel(model="iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
vad_model="fsmn-vad",
punc_model="ct-punc-c")
# --- 2. 执行模型 Pipeline ---
print(f"开始处理音频文件: {audio_file}")
print("开始执行说话人分离...")
# 如果您能确定说话人数量,增加此参数可以提升准确率
num_speakers = 2
diarization_result = diarization_pipeline(audio_file, oracle_num=num_speakers)
diarization_output = diarization_result['text']
print(f"说话人分离完成。")
print(f"--- 说话人分离模型原始输出 ---\n{diarization_output}\n---------------------------------")
print("开始执行语音识别...")
# 利用模型内置的VAD进行智能分句,直接获取句子列表
res = asr_model.generate(input=audio_file, sentence_timestamp=True)
print("语音识别完成。")
# --- 3. 合并与处理 ---
def parse_diarization_result(diarization_segments):
"""解析说话人分离模型返回的 [[start, end, id]] 格式列表。"""
speaker_segments = []
if not isinstance(diarization_segments, list): return []
for segment in diarization_segments:
if isinstance(segment, list) and len(segment) == 3:
try:
start_sec, end_sec = float(segment[0]), float(segment[1])
speaker_id = f"spk_{segment[2]}"
speaker_segments.append({'speaker': speaker_id, 'start': start_sec, 'end': end_sec})
except (ValueError, TypeError) as e: print(f"警告:跳过格式错误的分离片段: {segment}。错误: {e}")
return speaker_segments
def merge_results(asr_sentences, speaker_segments):
"""将ASR结果和说话人分离结果合并"""
merged_sentences = []
if not speaker_segments:
# 如果说话人分离失败,则所有句子都标记为未知
for sentence in asr_sentences:
sentence['speaker'] = "spk_unknown"
merged_sentences.append(sentence)
return merged_sentences
for sentence in asr_sentences:
sentence_start_sec, sentence_end_sec = sentence['start'] / 1000.0, sentence['end'] / 1000.0
found_speaker, best_overlap = "spk_unknown", 0
# 寻找与当前句子时间重叠最长的说话人片段
for seg in speaker_segments:
overlap_start = max(sentence_start_sec, seg['start'])
overlap_end = min(sentence_end_sec, seg['end'])
overlap_duration = max(0, overlap_end - overlap_start)
if overlap_duration > best_overlap:
best_overlap = overlap_duration
found_speaker = seg['speaker']
sentence['speaker'] = found_speaker
merged_sentences.append(sentence)
return merged_sentences
def format_time(milliseconds):
"""将毫秒转换为SRT的时间格式 (HH:MM:SS,ms)"""
seconds = milliseconds / 1000.0
h = int(seconds // 3600)
m = int((seconds % 3600) // 60)
s = int(seconds % 60)
ms = int((seconds - int(seconds)) * 1000)
return f"{h:02d}:{m:02d}:{s:02d},{ms:03d}"
def to_srt(sentences):
"""将合并后的结果转换为带说话人ID的SRT格式"""
srt_content = ""
for i, sentence in enumerate(sentences):
if 'start' not in sentence or 'end' not in sentence: continue
start_time = format_time(sentence['start'])
end_time = format_time(sentence['end'])
speaker_id = sentence.get('speaker', 'spk_unknown')
text = sentence.get('text', '')
srt_content += f"{i + 1}\n{start_time} --> {end_time}\n[{speaker_id}] {text}\n\n"
return srt_content
# --- 4. 生成最终SRT字幕 ---
speaker_info = parse_diarization_result(diarization_output)
sentence_list = []
if res and 'sentence_info' in res[0]:
sentence_list = res[0]['sentence_info']
else:
print("错误或警告:未能从ASR结果中获取 'sentence_info'。")
final_sentences = merge_results(sentence_list, speaker_info)
srt_output = to_srt(final_sentences)
print("\n--- 生成的SRT字幕内容 ---")
if srt_output:
print(srt_output)
output_srt_file = 'output_with_speakers.srt'
with open(output_srt_file, 'w', encoding='utf-8') as f: f.write(srt_output)
print(f"带说话人标识的SRT字幕文件已保存到: {output_srt_file}")
else:
print("未能生成SRT内容。")环境配置小贴士
- 安装依赖:
pip install -U modelscope funasr addict - 版本兼容问题:安装后运行若报错,可以尝试降级
numpy和datasets包,这通常能解决一些常见的兼容性问题:pip install --force-reinstall numpy==1.26.4 datasets==3.0.0
在 Google Colab 上的执行结果
开源说话人分离模型离生产环境还有多远?
这次实践证明,技术上完全可以搭建一套“手作”的说话人识别流水线。但这套方案同样有其明显的局限性:
分离模型是效果瓶颈:这一点怎么强调都不过分。
cam++模型是整个工作流的短板。如果它在你的音频上“听”不出几个人,后续的代码写得再好也无力回天。在处理背景噪音、口音、语速变化等复杂场景时,它的表现不尽人意。惧怕“抢话”和“插话”:我们的合并逻辑是“赢家通吃”,一句话会完整地判给重叠时间最长的说话人。它处理不了两人同时说话或对话有交叉的复杂情况。
那么,放眼业界,其他玩家是怎么做的呢?
| 方案类型 | 代表工具/服务 | 优点 | 缺点 | 一句话点评 |
|---|---|---|---|---|
| 开源集成流水线 | WhisperX, Pyannote.audio | 效果顶级,社区活跃,代表了学术界和开源界的最高水平。 | 配置复杂,资源消耗大,对新手不算友好。 | 适合爱折腾、追求极致效果的技术专家,小白用户速逃。 |
| 商业云服务 API | Google STT, AWS Transcribe, 讯飞 | 简单好用,稳定可靠,基本不用操心底层细节。 | 按量付费,成本高,数据需上传云端。 | “钞能力”之选,适合快速开发和不差钱的企业。 |
| 本项目方案 | ModelScope + FunASR | 免费开源,灵活可控,可以自由组合和修改模型。 | 需要自己动手踩坑和集成,当前效果不稳定。 | 适合学习、实验和对效果要求不高的场景。 |
我最初的目标是测试这套方案的效果,如果足够好,就集成到我的另一个项目 pyVideoTrans 中。但从实际测试结果来看,它的表现,尤其是对于长音频,还远未达到生产可用的标准。而像 Pyannote.audio 这样的顶级开源方案,部署和集成的复杂度的确劝退。
因此,这次探索暂时告一段落。虽然最终的成品效果不佳,但整个过程依然是一次宝贵的学习经历。