This article introduces an online web-based real-time speech recognition tool that supports microphone live recording recognition and audio/video file speech recognition, available for free with no usage restrictions.
Speech recognition technology, also known as speech transcription, uses artificial intelligence to convert speech from audio or video into text. This technology is widely applied in many fields, such as meeting minutes, voice assistants, subtitle generation, and more.
Currently, there are two main methods of speech recognition:
1. Offline Model-Based Speech Recognition:
This method requires deploying a speech recognition model on a local computer. A popular open-source solution is OpenAI Whisper. After downloading its large model (e.g., large-v2), it can be used offline without an internet connection and without any cost.
However, this approach requires strong computational resources (e.g., a powerful graphics card); otherwise, the recognition speed will be slow, and accuracy will decrease.
2. Online API-Based Speech Recognition:
Some companies provide online speech recognition API services, such as ByteDance and OpenAI.
Users only need to upload audio data to the API to receive transcription results.
This method does not require local hardware resources, is fast, and has high accuracy, but it comes with associated costs.
Real-Time Speech Recognition
The two methods above mainly target existing audio or video files. So, how can real-time transcription be performed on audio streams recorded live from a microphone? For example, how can speech in a meeting be recorded and converted to text in real time?
Real-time speech recognition is similar in principle to file transcription but is technically more challenging. It requires:
- Real-time data stream processing: Continuously receiving audio data from the microphone.
- Data segmentation and recognition: Splitting the continuous audio stream into smaller segments and recognizing them one by one.
- Result integration and error correction: Combining the recognition results from each segment and performing error correction to improve the accuracy of the final transcription. This often requires more complex algorithms to handle pauses, overlaps, and other speech phenomena.
- Minimal latency: Reducing the delay from audio input to text output as much as possible to ensure real-time performance.
Technical Principles and Usage Introduction
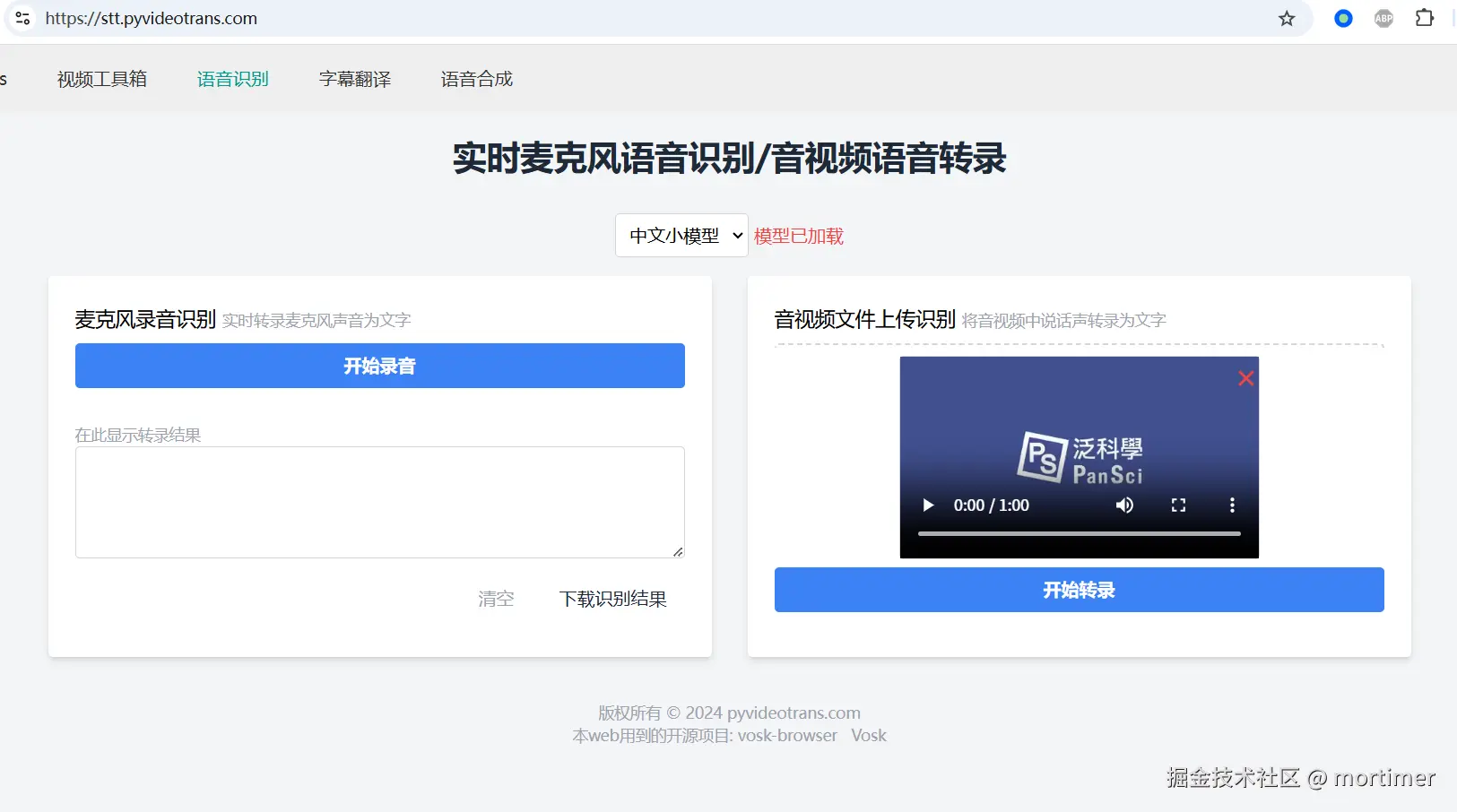
- Microphone Live Recording Recognition: Uses the microphone to record audio in real time and transcribe it simultaneously.
- Audio/Video File Speech Recognition: Supports uploading local audio or video files for transcription.
Technical Principles:
Lightweight Speech Recognition Model (Vosk): To run in a browser environment, we use the compact Vosk speech recognition model. Although its accuracy is relatively lower, it effectively reduces resource usage and ensures smooth operation in the browser.
Local Audio Processing (ffmpeg.wasm): Utilizes ffmpeg.wasm to process audio/video files and extract speech directly in the user's browser, without uploading audio data to a server.
Client-Side Model Loading: The speech recognition model is downloaded and runs in the browser's memory. This limits the use of larger, more accurate models, as only smaller models can be selected to prevent browser crashes. Even if the user's computer is powerful, large models are not currently supported due to server bandwidth limitations.
How to Use
- Model Loading: Before use, load the Chinese or English model as needed.
- Microphone Recognition: Click the button in the left area to start real-time recording and recognition using the microphone. The recognition results will be displayed in real time in the text box.
- File Recognition: Select a local audio or video file in the right area. The tool will use ffmpeg.wasm for local processing and perform speech recognition. The results will be displayed in the text box.
- Result Download: The transcribed text can be downloaded as a TXT file.
Notes
- Mutually Exclusive Features: Microphone real-time recognition and file recognition cannot be used simultaneously.
- Local Processing: Both the model and audio processing are performed locally in the user's browser.
- Language Support: Currently, only Chinese and English speech recognition are supported.
- Performance Limitations: Due to the use of lightweight models, recognition accuracy may not match that of larger models.
Frequently Asked Questions
- Q: What if the recognition accuracy is low? A: We use lightweight models to ensure browser compatibility and performance. If you need higher accuracy, we recommend downloading pyVideoTrans to use the large-v2 model locally.
- Q: Which languages are supported? A: Currently, only Chinese and English are supported.
- Q: Why is it slow? A: This may be due to network conditions, browser performance, or insufficient computer resources.
- Q: How large a file can be uploaded? A: File size is limited by browser memory and processing capabilities.