搞定 FFmpeg 跨平台硬件加速:我的自动选择方案与踩坑实录 (含 Python 代码)
搞视频处理,FFmpeg 简直是绕不开的神器。但用着用着,性能就成了新瓶颈。想提速?硬件加速编码(比如用显卡搞 H.264/H.265)自然是首选。可接下来,一个让人头大的坎儿就来了:跨平台兼容性。
你想想:
- 操作系统有 Windows、Linux、macOS。
- 显卡有 NVIDIA、AMD、Intel,还有 Mac 自家的 M 系列芯片。
- 它们支持的硬件加速技术五花八门:NVENC, QSV, AMF, VAAPI, VideoToolbox...
- 对应到 FFmpeg 里的参数 (
-c:v xxx_yyy) 又各不相同。
为每个环境手写一套配置?太折腾了,而且准保出错。我的目标很明确:写个 Python 函数,让程序能自己“闻”出当前环境能用哪个硬件编码器,而且得是“最优选”。如果硬件加速这条路走不通,还得能自动、优雅地退回到用 CPU 软编码(比如大家熟悉的 libx264, libx265),保证程序不撂挑子。
我的路子:大胆试错 + 优雅降级
靠猜肯定不行,最稳妥的办法就是——让 FFmpeg 自己去试!我摸索出的基本思路是这样:
- 先搞清楚程序跑在哪个操作系统上,用户想要啥编码格式(H.264 还是 H.265?)。
- 写一个核心的“试探”函数:用特定的硬件加速参数 (
-c:v xxx_yyy) 去尝试编码一个贼短的视频片段。 - 根据不同的操作系统,按“经验优先级”(比如 NVIDIA 通常优先)去调用这个“试探”函数,挨个尝试可能的硬件加速器。
- 哪个试成功了,就用它!如果全军覆没,那就老老实实用默认的 CPU 软编码。
能打能抗的测试函数 test_encoder_internal
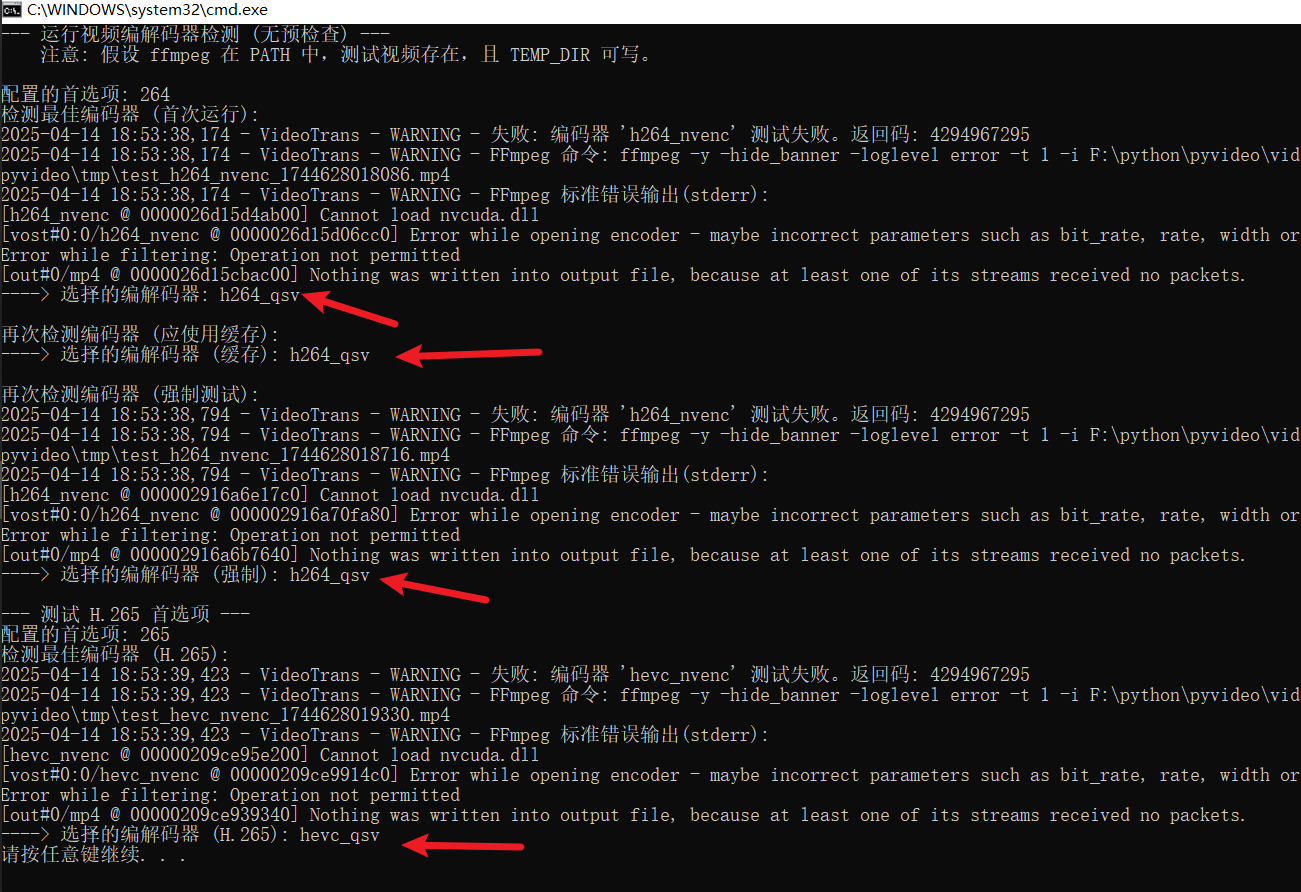
下面这个内部函数,就是整个自动选择机制的“心脏”。它负责真正去调用 ffmpeg 命令,并且能扛住各种失败,还能从失败中挖出点信息:
# --- 内部核心测试函数 (久经沙场版) ---
def test_encoder_internal(encoder_to_test: str, timeout: int = 20) -> bool:
"""
尝试用指定的编码器跑个短任务。
成功返回 True,失败或超时返回 False。
"""
timestamp = int(time.time() * 1000)
# 注意:temp_dir 和 test_input_file 是从外面传进来的
output_file = temp_dir / f"test_{encoder_to_test}_{timestamp}.mp4"
# 构建 ffmpeg 命令,短小精悍,直击要害
command = [
"ffmpeg",
"-y", # 如果有同名文件,直接覆盖,别问
"-hide_banner", # 安静点,别打印版本信息刷屏
"-loglevel", "error", # 只关心错误信息,其他的别烦我
"-t", "1", # 就编码 1 秒钟!测试而已,速度要快
"-i", str(test_input_file), # 用这个测试视频文件做输入
"-c:v", encoder_to_test, # !!! 关键:指定这次要试的编码器 !!!
"-f", "mp4", # 输出个 mp4 格式就行
str(output_file) # 临时输出文件,测完就删
]
# ... (这里省略了 Windows 下为隐藏黑窗口设置 creationflags 的代码) ...
config.logger.info(f"开始试探编码器: {encoder_to_test}...")
success = False
try:
# 用 subprocess.run 执行命令,设置好超时和错误捕获
process = subprocess.run(
command,
check=True, # 如果 ffmpeg 返回非 0 退出码,就抛异常
capture_output=True, # 把 ffmpeg 的输出(stdout/stderr)抓回来
text=True, # 输出按文本处理
encoding='utf-8', # 用 utf-8 解码
errors='ignore', # 万一解码出错,忽略掉,别崩
creationflags=creationflags, # (Windows) 隐藏控制台窗口
timeout=timeout # !!! 设置个超时,防止卡死 !!!
)
# 走到这里,说明命令成功执行且退出码为 0
config.logger.info(f"好消息: 编码器 '{encoder_to_test}' 测试通过!可用!")
success = True
except FileNotFoundError:
# 系统 PATH 里连 ffmpeg 命令都找不到
config.logger.error(f"致命错误: 测试 {encoder_to_test} 时,找不到 'ffmpeg' 命令。请检查环境。")
except subprocess.CalledProcessError as e:
# ffmpeg 执行了,但出错了(比如编码器不支持、参数错误等)
config.logger.warning(f"坏消息: 编码器 '{encoder_to_test}' 测试失败。FFmpeg 返回码: {e.returncode}")
# !!! 这才是排查问题的金钥匙:打印 ffmpeg 的 stderr 输出 !!!
if e.stderr:
# 把错误信息记下来,非常重要!
config.logger.warning(f"FFmpeg 说:\n{e.stderr.strip()}")
else:
config.logger.warning("FFmpeg 这次没留下啥错误信息 (stderr 为空)")
except subprocess.TimeoutExpired:
# 在规定时间内没跑完,可能卡住了或者太慢
config.logger.warning(f"超时警告: 测试编码器 '{encoder_to_test}' 超过了 {timeout} 秒,判定为失败。")
except PermissionError:
# 权限问题,比如没权限写临时文件
config.logger.error(f"权限错误: 测试 {encoder_to_test} 时遇到权限问题,请检查临时目录权限。")
except Exception as e:
# 兜底,抓其他意外错误
config.logger.error(f"意外错误: 测试 {encoder_to_test} 时发生未知异常: {e}", exc_info=True)
finally:
# 不管成功失败,都得清理战场:删掉临时文件
# (Python 3.8+ 用 missing_ok=True 很方便)
try:
output_file.unlink(missing_ok=True)
except OSError as e:
# 删文件也可能失败,记录一下就好,别影响主流程
config.logger.warning(f"清理临时文件 {output_file} 时出小错: {e}")
# 把测试结果(成功/失败)返回出去
return success这个“试探”函数打磨了很久,关键点在于:
-t 1和-loglevel error:让测试尽可能快且干净。subprocess.run配套的参数:check=True捕获错误退出码,capture_output=True抓取输出,timeout防止无限等待。- 最重要的:在
CalledProcessError异常里,一定要把e.stderr打印或记录下来!这通常包含了 FFmpeg 失败的直接原因(比如 "Encoder not found"、"Cannot init device" 等),是调试的命根子。 finally块:确保无论发生什么,我们都尝试清理临时文件,避免留下垃圾。unlink(missing_ok=True)让代码更简洁,不怕文件一开始就不存在。
平台策略:因地制宜,排好优先级
有了核心测试函数,接下来就是主函数根据 platform.system() 返回的操作系统类型,决定按什么顺序去尝试哪些编码器了:
# --- 主函数里的平台判断与尝试逻辑 ---
config.logger.info(f"当前系统: {plat}。开始为 '{h_prefix}' 编码寻找最佳拍档...") # h_prefix 是 'h264' 或 'h265'
try:
# macOS 最省心:通常只有 videotoolbox
if plat == 'Darwin':
encoder_name = f"{h_prefix}_videotoolbox"
if test_encoder_internal(encoder_name):
config.logger.info("macOS 环境,VideoToolbox 测试通过!")
selected_codec = encoder_name
# Windows 和 Linux 比较复杂,咱们得按优先级来
elif plat in ['Windows', 'Linux']:
nvenc_found_and_working = False # 先立个 flag
# 第一优先级:试试 NVIDIA 的 NVENC (如果机器上有 N 卡的话)
# (这里可以加个可选逻辑,比如检查 torch.cuda.is_available(),但简单起见先直接试)
encoder_name = f"{h_prefix}_nvenc"
config.logger.info("优先尝试 NVIDIA NVENC...")
if test_encoder_internal(encoder_name):
config.logger.info("NVIDIA NVENC 测试通过!就用它了!")
selected_codec = encoder_name
nvenc_found_and_working = True # 标记成功!
else:
config.logger.info("NVIDIA NVENC 测试失败或当前环境不可用。")
# 如果 NVENC 没戏,再根据具体系统找备胎
if not nvenc_found_and_working:
if plat == 'Linux':
# Linux 备胎 1: 尝试 Intel/AMD 通用的 VAAPI
config.logger.info("NVENC 不行,Linux 环境下尝试 VAAPI...")
encoder_name = f"{h_prefix}_vaapi"
if test_encoder_internal(encoder_name):
config.logger.info("VAAPI 测试通过!可用!")
selected_codec = encoder_name
else:
config.logger.info("VAAPI 测试失败或不可用。")
# Linux 备胎 2: (可选,优先级较低)再试试 AMD 的 AMF
# if selected_codec == default_codec: # 只有在前两者都没选上的情况下才试
# config.logger.info("VAAPI 也不行,最后试试 AMD AMF...")
# # ... 这里加上测试 amf 的代码 ...
elif plat == 'Windows':
# Windows 备胎 1: 尝试 Intel 的 QSV (Quick Sync Video)
config.logger.info("NVENC 不行,Windows 环境下尝试 Intel QSV...")
encoder_name = f"{h_prefix}_qsv"
if test_encoder_internal(encoder_name):
config.logger.info("Intel QSV 测试通过!可用!")
selected_codec = encoder_name
else:
config.logger.info("Intel QSV 测试失败或不可用。")
# Windows 备胎 2: 再试试 AMD 的 AMF
# if selected_codec == default_codec:
# config.logger.info("QSV 也不行,试试 AMD AMF...")
# # ... 这里加上测试 amf 的代码 ...
else:
# 其他奇奇怪怪的系统,直接放弃治疗
config.logger.info(f"哎呀,遇到不支持的平台: {plat}。只能用 CPU 软编码 {default_codec} 了。")
except Exception as e:
# 如果整个测试过程中出现任何意外,比如权限问题、磁盘满了等
# 为了保证程序健壮性,直接回退到安全的软编码
config.logger.error(f"在检测编码器过程中发生意外错误: {e}。将强制使用软件编码。", exc_info=True)
selected_codec = default_codec # 保险起见,退回默认
# --- 最终拍板 ---
if selected_codec == default_codec:
# 如果转了一圈还是默认值,说明硬加速没找到合适的
config.logger.info(f"一番尝试后,未能找到合适的硬件编码器。最终决定使用 CPU 软编码: {selected_codec}")
else:
# 成功找到了硬加速器!
config.logger.info(f"太棒了!已选定硬件编码器: {selected_codec}")
# 把结果缓存起来,下次就不用再测一遍了
_codec_cache[cache_key] = selected_codec
return selected_codec # 把选好的编码器名字返回出去这段逻辑体现了几个决策点:
- macOS 单独处理:它有自己的一套
videotoolbox,比较简单。 - Windows 和 Linux 优先考虑 NVIDIA:因为 N 卡的
nvenc兼容性通常较好,如果用户有 N 卡,优先用它。 - 备胎策略:如果
nvenc不行,Linux 接下来试试通用的vaapi(Intel/AMD 都可能支持),Windows 则试试 Intel 的qsv。AMD 的amf优先级可以放得更低一些(根据你的目标用户和经验调整)。 - 安全回退:任何一步测试成功,
selected_codec就会被更新为那个硬件加速器的名字。如果所有尝试都失败了,或者中间出了任何岔子,它会保持(或被重置为)初始的默认值(比如libx264),保证总有个能用的编码器。 - 缓存是必须的:最后把千辛万苦测出来的结果存进缓存,下次再调用这个函数时(只要平台和编码格式没变),直接从缓存取,避免重复耗时的测试。
别忘了缓存!性能优化的关键一步
反复运行 ffmpeg 测试是很慢的,所以缓存机制少不了:
# --- 函数开头先查缓存 ---
_codec_cache = config.codec_cache # 假设你的配置里有个全局缓存字典
cache_key = (plat, video_codec_pref) # 用平台和想要的编码格式做 key
# 如果不是强制重新测试,并且缓存里有结果,直接返回!
if not force_test and cache_key in _codec_cache:
cached_codec = _codec_cache[cache_key]
config.logger.info(f"命中缓存!平台 {plat} 的 '{video_codec_pref}' 编码器直接用上次的结果: {cached_codec}")
return cached_codec
# --- 如果缓存没有,或者强制测试 ---
# ... (执行上面的平台判断和测试逻辑) ...
# --- 函数末尾,把结果存入缓存 ---
# ... (经过一番折腾,最终确定了 selected_codec) ...
_codec_cache[cache_key] = selected_codec # 记住了!下次用
config.logger.info(f"已将 {cache_key} 的选择结果 {selected_codec} 存入缓存。")
return selected_codec在函数开头检查缓存,在函数末尾存入结果,逻辑简单,效果拔群。
给 Linux 和 macOS 用户的友情提示
虽然代码是跨平台的,但能不能成功用上硬件加速,还得看环境本身给不给力:
- macOS:
videotoolbox一般来说比较省心,只要你用的ffmpeg(比如通过 Homebrew 装的) 编译时开启了支持就行。 - Linux: 这边坑就多了,用户得确保:
- 显卡驱动装对了吗? NVIDIA 的闭源驱动、Intel 的 Media Driver、AMD 的 Mesa/AMDGPU-PRO...
- 相关的库装了吗? 比如
libva-utils(for vaapi),nv-codec-headers(for nvenc)... - 你用的
ffmpeg版本对吗? 是不是编译的时候就没包含你要的硬件加速支持?(用ffmpeg -encoders | grep nvenc这类命令可以查) - 权限够吗? 运行程序的用户可能需要被添加到
video或render用户组才能访问硬件设备。
收个尾
想让 FFmpeg 在不同平台上自动用上硬件加速,核心就是别怕失败,拥抱测试:大胆去试,但要准备好接住各种错误(特别是抓住 stderr 这个救命稻草),并且一定要有条可靠的后路(回退到 CPU 软编码)。再配上缓存这个加速器,你就能得到一个既聪明又高效的解决方案了。
虽然最终的函数很长很丑陋,但又不是不能用! 希望我趟过的这些坑和整理的代码思路,能帮你少走弯路,更顺畅地驾驭 FFmpeg 的硬件加速!